Q1: What Is an AI SOC SLA, and Why Do Traditional SOC SLAs Fall Short in 2026?
Most SOC SLAs still in production were written for a world that no longer exists: human-only operations with 4-hour MTTR targets, 99.5% uptime commitments, and 24-hour breach notification windows. These benchmarks made sense when every alert required a human to open a ticket, pivot between three consoles, and manually correlate logs. But AI-driven SOCs now operate at fundamentally different speeds, investigating alerts the moment they fire and executing containment playbooks in minutes, not hours. That means legacy SLA language, “best effort response,” “within one business day,” is not just outdated. It is dangerous. If your procurement team is still evaluating MDR providers against 2019-era SLA templates, this article gives you the 2026 framework you actually need.
⚠️ The “Black Box SLA” Trap
Here is the operational reality most buyers never see until contract renewal: traditional MDR providers either don’t publish MTTR targets or bury them behind vague “best effort response” language. Arctic Wolf, CrowdStrike Falcon Complete, and ReliaQuest: none of them give you a published, contractual MTTR commitment you can hold them to on a quarterly business review. Legacy MSSPs are worse. They provide checkbox SLAs tied to monitoring, not outcomes. “We will monitor 24/7” is not an SLA. “We will contain P1 threats within 30 minutes” is. The distinction matters because when you’re negotiating renewal and asking why a critical alert sat uninvestigated for 6 hours, “best effort” gives them an exit. A published MTTR target gives you leverage.
⏰ The AI-Era Transformation
AI SOCs fundamentally compress the response timeline. MTTA, Mean Time to Acknowledge, effectively approaches zero because AI begins investigating alerts the moment they fire, eliminating the human queue entirely. SLAs must now measure end-to-end time-to-contain, not just time-to-acknowledge. The new SLA framework has seven pillars: detection speed (MTTD), triage accuracy, containment time (MTTC), escalation gates, uptime guarantees, penalty structures, and compliance notification windows. The Softenger SOC Modernization Blueprint sets 2026 benchmarks at MTTD < 10 minutes and MTTR < 1 hour, and organizations deploying SOAR-integrated AI SOCs achieve MTTR 60 to 90% lower than those without automation.
✅ How UnderDefense Approaches AI SOC SLAs
We built the UnderDefense MAXI platform specifically so these numbers are not aspirational but contractual. UnderDefense publishes a 2-minute alert-to-triage and 15-minute escalation for critical incidents, integrates vendor-agnostically across 250+ existing security tools, and delivers concierge analyst response that closes the human-decision bottleneck traditional MDR providers leave open. That means your SLA doesn’t just promise “we’ll look at it.” It guarantees detection, investigation, user verification, and containment within a defined time window. Transparent, published commitments vs. competitors’ “contact sales” opacity: that is the difference between an SLA that protects your organization and one that protects the vendor.
Organizations with SOAR-integrated AI SOCs achieve MTTR 60 to 90% lower than those without automation, and UnderDefense bakes this into contractual SLA guarantees, not marketing averages. When every 10-minute improvement in detection time can save approximately $50K to $100K per incident for a mid-size enterprise, the gap between a published SLA and a “best effort” promise is not academic. It is financial.
Q2: MTTR, MTTD, MTTA, and MTTC: How Does AI Transform Every SOC Response Metric?
Before negotiating any AI SOC SLA, you need a shared vocabulary. Too many contracts conflate “response time” with “acknowledgment time,” and vendors exploit that ambiguity. Here are the four core metrics every security leader must understand, and how AI fundamentally changes each phase.
📌 The Four Core SOC Metrics, Defined
| Metric | Full Name | Definition |
|---|---|---|
| MTTD | Mean Time to Detect | Time from breach occurrence to initial detection by monitoring systems |
| MTTA | Mean Time to Acknowledge | Time from alert generation to when an analyst (or AI) begins investigation |
| MTTR | Mean Time to Respond | Time from detection to full containment and remediation |
| MTTC | Mean Time to Contain | Time from confirmed threat identification to isolation and neutralization |
These are not interchangeable, and vendors who report MTTA as MTTR are hiding the gap between “we saw it” and “we stopped it.” Prophet Security’s phased MTTR framework breaks this lifecycle into discrete, measurable stages precisely because lumping them together obscures where time is actually lost. Dropzone AI’s taxonomy adds MTTC as the comprehensive metric capturing the entire alert lifecycle from detection through final disposition.
⚡ How AI Transforms Each Phase
MTTD drops from days to minutes. Continuous ML-based anomaly detection replaces periodic human review, catching behavioral deviations in real time rather than waiting for signature matches. Elite SOCs now target MTTD under 1 hour. AI-driven platforms push this below 10 minutes.
MTTA approaches zero. This is the biggest structural shift. In traditional SOCs, alerts sit in queues waiting for human attention, the “hidden bottleneck” that stretches every downstream metric. AI SOC analysts begin investigating the moment an alert arrives, eliminating MTTA entirely. As Dropzone AI’s research frames it: “MTTA is killing your MTTR,” because every minute an alert sits unacknowledged is a minute attackers use to move laterally.
MTTR compresses from hours to minutes. AI runs parallel investigations across all telemetry sources simultaneously. What took a human analyst 20 to 40 minutes per alert now completes in 3 to 10 minutes with consistent depth. Top-performing AI SOC platforms cut MTTD/MTTR by 40 to 60%.
MTTC drops 75 to 95% as automated playbooks execute containment actions, disabling compromised accounts, blocking malicious traffic, quarantining endpoints, the moment a threat is confirmed.
📊 AI-Native Companion KPIs for Modern SLAs
Legacy contracts stop at MTTR. Modern AI SOC SLAs should include these companion KPIs that measure quality, not just speed:
- AI Decision Accuracy: % of correct triage decisions (target: >95%)
- Automated Response Rate: % of incidents fully resolved without human intervention
- Alert Coverage Rate: % of alerts receiving full investigation vs. auto-closed (industry norm: ~50 to 70%; AI target: 100%)
- Escalation Rate: % requiring human analyst review (healthy range: 5 to 15%)
- Analyst Force Multiplication: ratio of alerts handled per analyst per shift
These metrics belong in your SLA because they separate vendors who process alerts from vendors who investigate them.
✅ How UnderDefense Simplifies This
UnderDefense’s SLA includes KPIs beyond basic MTTR, including 96% MITRE ATT&CK coverage, 99% alert noise reduction, and transparent monthly reporting that tracks detection, response, and quality metrics. You see the numbers, not just the claims. That is the “show, don’t tell” approach: observable workflows, reproducible outcomes, and contractual accountability for every metric that matters.
Q3: What MTTR, Alert-to-Triage, and False Positive Targets Should Your AI SOC SLA Guarantee?
This is the section your procurement team should bookmark. Below are the specific numeric benchmarks, severity-tiered MTTR targets, alert-to-triage time windows, and false positive rate SLAs, that separate a real AI SOC commitment from marketing language.
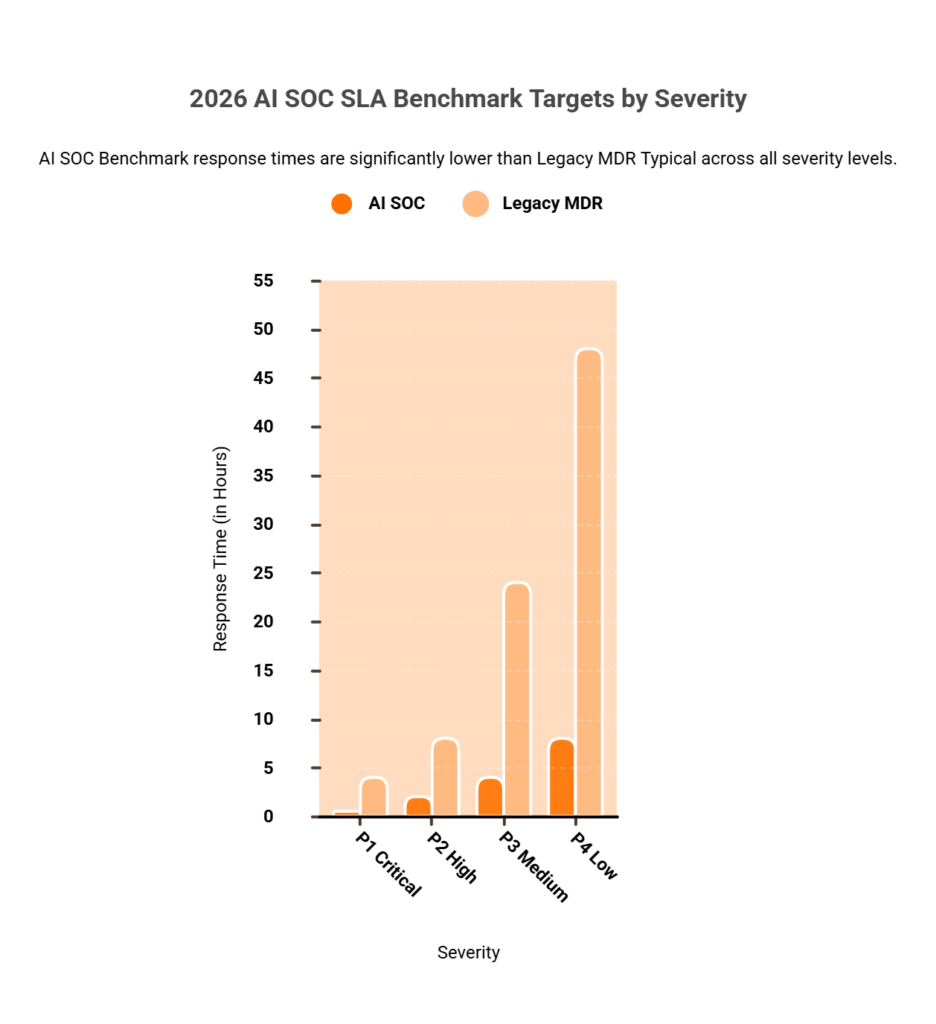
⏰ Severity-Tiered MTTR Benchmarks
| Severity | AI Triage Target | Total Containment Target | What This Means |
|---|---|---|---|
| Critical (P1) | ≤15 min | ≤30 min | Active ransomware, confirmed data exfiltration, live attacker in environment |
| High (P2) | ≤30 min | ≤2 hours | Credential compromise, lateral movement indicators, C2 communication |
| Medium (P3) | ≤1 hour | ≤4 hours | Suspicious behavior patterns, policy violations, anomalous access |
| Low (P4) | ≤4 hours | ≤8 hours | Informational alerts, configuration drift, non-critical policy exceptions |
The Softenger SOC Modernization Blueprint benchmarks MTTR < 1 hour and MTTD < 10 minutes for mature AI-ready SOCs. UnderDefense publishes a 2-minute alert-to-triage and 15-minute escalation for critical incidents. ⚠️ Warning: Watch for vendors who report MTTA (time to acknowledge) as MTTR (time to respond). Acknowledgment without containment is just a timestamp, not a security outcome.
📊 Alert-to-Triage Benchmarks
| Phase | AI SOC Target | Traditional SOC Baseline |
|---|---|---|
| AI Initial Triage (enrichment + classification) | <60 seconds | 30 to 60 min for acknowledgment alone |
| Full AI Investigation (correlation + context) | 3 to 10 minutes | 20 to 40 minutes per alert |
| Human Escalation Decision (when required) | <15 minutes | Hours to days |
| Total Alert-to-Verdict (P1/P2) | <20 minutes | 4 to 24 hours |
Dropzone AI’s research confirms that AI-driven investigation compresses the 20 to 40 minute manual investigation window to 3 to 10 minutes with consistent depth and accuracy. For traditional SOCs, initial acknowledgment alone takes 30 to 60 minutes, before any investigation even begins. That is an entire phase AI eliminates.
❌ False Positive and Coverage SLA Targets
| Metric | Target | Why It Matters |
|---|---|---|
| AI Decision Accuracy | >95% | Measures correct triage decisions, not just speed but quality |
| False Positive Reduction Rate | >90% vs. pre-AI baseline | Validates that AI tuning actually reduces noise, not just relabels it |
| Alert Coverage Rate | 100% investigated | Industry norm is 50 to 70% of alerts investigated; AI SOCs should cover all |
| Escalation Rate | 5 to 15% of total alerts | Too low means AI is auto-closing without scrutiny; too high means AI is not adding value |
⚠️ Measurement methodology matters: demand clarity on whether benchmarks use mean, median, or P95 calculations. Vanity metrics like “alerts processed” without quality measures tell you nothing about actual security outcomes.
✅ How UnderDefense Simplifies This
UnderDefense achieves 99% alert noise reduction through custom detection tuning and AI-driven triage. Combined with ChatOps user verification, alerts that competitors cannot resolve get closed without escalating back to your team. The UnderDefense MAXI platform’s published benchmarks, 2-minute alert-to-triage, 15-minute escalation for critical incidents, 96% MITRE ATT&CK coverage, 98% verdict accuracy, are not marketing averages. They are contractual SLA commitments you can audit monthly.
Q4: What Platform Uptime and SLA Penalty Standards Should You Negotiate?
A security platform that goes down during an active incident is worse than no platform at all, because your team built workflows around it. Uptime SLAs and penalty structures are the most under-negotiated sections of MDR contracts, and most buyers don’t push back until it is too late.
📊 Uptime Tiers with Real Downtime Math
| Uptime SLA | Annual Downtime | Monthly Downtime | Best Fit |
|---|---|---|---|
| 99.9% | 8 hours 45 minutes | ~43 minutes | Acceptable baseline for most mid-market organizations |
| 99.95% | 4 hours 23 minutes | ~21 minutes | Recommended for regulated industries: healthcare, financial services |
| 99.99% | 52 minutes 36 seconds | ~4 minutes | Premium tier for critical infrastructure and high-frequency environments |
These numbers come from straightforward math: (Total Time – Downtime) / Total Time × 100. The difference between 99.9% and 99.99% is roughly 10× less downtime, but the cost and architectural complexity to achieve it scales exponentially. Your SLA should also define whether scheduled maintenance windows count against uptime and whether the measurement is provider-reported or independently monitored.
💰 SLA Penalty and Service-Credit Structures
This is the topic no MDR competitor covers, but every buyer cares about. What happens when commitments are missed? Here is a tiered credit model your legal team should push for:
| Breach Condition | Recommended Credit |
|---|---|
| Each 0.1% uptime shortfall below committed SLA | 5% monthly service credit |
| MTTR exceeds committed target by >50% in any calendar month | 10% monthly service credit |
| Escalation time gates breached more than 3× in a quarter | 15% monthly service credit |
| Repeated SLA failures across consecutive quarters | Termination rights without penalty |
Understand the difference between service credits (applied to future invoices), financial penalties (direct cash compensation), and termination rights (ability to exit without early-termination fees). Most MDR vendors offer only service credits, which means you are paying them less next month for failing you this month. Push for escalating penalties that include termination rights after repeated failures.
⚠️ What to Watch for in Uptime SLA Language
- Exclusion clauses: Scheduled maintenance, force majeure, and “customer-caused” outages are standard exclusions, but watch for overly broad definitions that let vendors classify planned upgrades as “emergency maintenance” to avoid SLA penalties.
- Measurement methodology: Provider-reported uptime is inherently conflicted. Require independent monitoring tools (e.g., third-party synthetic monitoring) and a real-time status page, not a monthly retrospective PDF.
- Reporting transparency: A real-time incident status page is table stakes. If a vendor resists publishing live uptime data, ask yourself what they are protecting: their SLA record or your security posture.
✅ How UnderDefense Simplifies This
UnderDefense’s UnderDefense MAXI platform is architected for continuous 24/7/365 monitoring with published uptime commitments and defined maintenance windows. Transparent SLAs include service-credit structures, because a security platform that avoids accountability for downtime is not a security platform. When you are evaluating MDR providers, the willingness to put financial skin in the game on uptime and response time tells you everything about how seriously they take operational reliability.
Q5: How Should an AI SOC Escalation Process Work for Critical Incidents?
The old SOC escalation model, L1 analyst triages, escalates to L2, L2 escalates to L3, repeat, was built for an era of hundreds of alerts per day. That era is gone. Modern environments generate tens of thousands of alerts daily across hybrid cloud, identity, endpoint, and SaaS layers. The manual escalation chain bleeds time at every handoff, loses context at every tier, and burns out analysts who spend most of their shift on noise rather than real threats.
⏰ The AI-First Escalation Model
The shift happening right now is structural: AI handles triage and investigation autonomously, and humans enter the chain only when decision-making requires organizational context or judgment under ambiguity. Torq’s research on the evolution from manual to AI-powered escalation frames this clearly. AI filters out 99% of alert noise, enriches the remaining 1% with full context and risk scores, and analysts only see validated cases prioritized by business impact. The escalation matrix no longer flows through human tiers linearly; it flows through capability tiers where automation handles the predictable, and analysts handle the novel.
Here is a concrete, numbered escalation matrix with time gates at each tier:
Step 1, L0: AI Triage (0 to 60 seconds)
- Alert ingestion from all connected telemetry (SIEM, EDR, cloud, identity, SaaS)
- Automated enrichment: IP reputation, threat intel, user behavior baseline, asset criticality
- Severity classification using dynamic risk scoring (not static severity labels)
- Auto-closure of confirmed false positives with documented reasoning
✅ Gate: If alert matches known-benign pattern with >98% confidence, close and log. Otherwise, escalate to L1.
Step 2, L1: AI Investigation (1 to 10 minutes)
- Full cross-tool correlation: endpoint alert + identity logs + cloud activity + network telemetry
- User verification via ChatOps (Slack, Teams, email): “Did you initiate this login from [location]?”
- Context assembly: timeline reconstruction, lateral movement indicators, related alerts
- Automated containment for known attack patterns (credential revocation, host isolation)
✅ Gate: If automated investigation confirms threat with high confidence and containment succeeds, document and close. If novel or ambiguous, escalate to L2.
🔍 Where Humans Enter the Chain
Step 3, L2: Human Analyst Decision (10 to 30 minutes)
- Concierge analyst reviews AI-assembled investigation package
- Initiates containment actions for novel threats that fall outside automated playbooks
- Communicates directly with affected users and IT teams for organizational context
✅ Gate: If containment succeeds and scope is limited, document and move to after-action. If breach is confirmed or scope expands, escalate to L3.
Step 4, L3: Incident Commander (30 to 60 minutes)
- Senior IR lead coordinates cross-functional response for confirmed breaches
- Engages legal, communications, and executive stakeholders
- Directs forensic investigation and evidence preservation
✅ Gate: If breach impacts regulated data or exceeds defined thresholds, escalate to L4.
Step 5, L4: Executive Notification (≤4 hours)
- CISO/CTO briefed with preliminary incident summary
- Regulatory notification clock formally starts
- External counsel and cyber insurance carrier engaged as needed
⚠️ SLA Clauses to Demand for Escalation
When evaluating any AI SOC provider, demand these escalation SLA elements in writing:
- Maximum dwell time at each tier before auto-escalation: if L1-AI hasn’t resolved within 10 minutes, it must auto-escalate to L2 without waiting for a human to notice
- Explicit severity-level definitions: what qualifies as P1 vs. P2 vs. P3, tied to business impact (not just alert severity scores)
- Named escalation contacts: “the team” is not an escalation path; you need named individuals or, at minimum, role-specific contacts available via direct channel
- After-action reporting timelines: preliminary incident report within 24 hours of containment, full root-cause analysis within 5 business days
How UnderDefense Simplifies This
UnderDefense’s escalation model is built around the AI SOC + Human Ally architecture. UnderDefense MAXI handles L0 to L1 autonomously, ingesting alerts from 250+ integrated tools, enriching with threat intelligence, and executing automated containment for known patterns. Dedicated concierge analysts own L2 containment with a documented 2-minute alert-to-triage and 15-minute escalation for critical incidents, communicating directly with affected users via Slack or Teams to verify and contain. Your team is only engaged at L3+ for strategic decisions. No “please investigate” tickets bounced back to you at 2 AM.
Q6: How Do Breach Notification Deadlines Back-Calculate Into Your SOC SLA?
Most security leaders treat breach notification as a legal exercise that starts after an incident. That is backwards. If you know the notification clock starts ticking the moment you become aware of a breach, every hour your SOC takes to detect, investigate, and contain directly compresses the time available for legal review, forensic scoping, and executive decision-making. Your SOC SLA is not just an operational metric. It is a compliance constraint.
📋 The Regulatory Landscape
Here is the current breach notification timeline across major frameworks:
| Regulation | Notification Deadline | Who Must Be Notified | Key Detail |
|---|---|---|---|
| GDPR (Articles 33 to 34) | 72 hours | Supervisory authority; individuals if high risk | Clock starts when organization has “sufficient awareness” a breach likely occurred |
| SEC Regulation S-P | 30 days | Affected customers | Large entities: Dec 3, 2025 compliance deadline; Small entities: June 3, 2026 |
| HIPAA Breach Notification Rule | 60 days | Affected individuals; HHS (and media if 500+ affected) | 60 days is the outer limit; “without unreasonable delay” is the actual standard |
| US State Laws | Varies (24 states ≤72 hours) | Affected residents; state AG offices | California requires 30-day notification starting Jan 1, 2026 |
| CIRCIA | 72 hours (incidents); 24 hours (ransom payments) | CISA | Applies to 16 critical infrastructure sectors; 300,000+ covered entities |
⏰ The Back-Calculation Framework
This is where operational SLA design gets mathematical. Take GDPR’s 72-hour notification requirement as the worked example:
Total available time: 72 hours
Work backwards from the notification deadline:
| Phase | Maximum Time Budget | Cumulative |
|---|---|---|
| Legal review + notification drafting | ≤24 hours | 24 hrs used |
| Executive briefing + approval | ≤4 hours | 28 hrs used |
| Forensic scoping (blast radius, data affected) | ≤12 hours | 40 hrs used |
| Containment (stop the bleeding) | ≤4 hours | 44 hrs used |
| Human analyst confirmation | ≤2 hours | 46 hrs used |
| AI-driven investigation | ≤30 minutes | 46.5 hrs used |
| Detection (MTTD) | ≤4 hours | 50.5 hrs used |
| Buffer for unexpected delays | ~21.5 hours | 72 hrs total |
That ~21.5-hour buffer is not luxury. It is insurance against forensic complexity, multi-jurisdiction coordination, and the inevitable 3 AM discovery that doubles scope. Without it, you are one delayed forensic finding away from a notification deadline violation.
⚠️ What This Means for Your SOC SLA
The back-calculation makes one thing clear: your SOC’s detection-to-containment window must complete within approximately 48 hours maximum under GDPR, leaving 24 hours for legal and executive workflows. Under SEC Regulation S-P’s 30-day window, you have more breathing room, but the principle is identical. Under HIPAA’s 60-day limit, the buffer is larger, but “without unreasonable delay” means regulators expect action far sooner than the outer boundary.
SLA clauses to demand from any MDR provider:
- Maximum detection-to-notification time: contractually defined, not aspirational
- Preliminary incident report within 8 hours of confirmed breach, because your legal team cannot start notification drafting without it
- Cooperation clauses for forensic investigation: provider must support evidence collection, not just detect
- Evidence chain-of-custody preservation: documented handling procedures that hold up under regulatory scrutiny
- Explicit vendor vs. customer responsibility matrix: who owns detection, who owns notification, who owns forensic evidence
How UnderDefense Simplifies This
UnderDefense includes forever-free compliance kits (SOC 2, HIPAA, ISO 27001) with MDR, and the UnderDefense MAXI platform automatically generates audit-ready incident documentation that accelerates your breach notification workflow from days to hours. With a documented 2-minute alert-to-triage and 15-minute escalation for critical incidents, the detection-to-containment window shrinks well below the back-calculated budget. Back-calculation is not theoretical when your SOC provider’s SLA already exceeds the math.
Q7: What Does an AI SOC SLA Actually Look Like? Sample Clause Tables You Can Use Today
Most AI SOC SLA guides tell you what to measure but never show you what the contract should actually say. That gap between knowledge and procurement action is where organizations get locked into vague commitments, unmeasurable promises, and penalty-free underperformance. Below are sample SLA clause tables covering six core domains. Adapt them for your next MDR vendor negotiation.
📋 Sample SLA Table 1: Response Time & Triage Quality
| Metric | SLA Target | Measurement Method | Reporting Cadence | Remedy if Missed |
|---|---|---|---|---|
| P1 MTTR (Critical) | ≤30 minutes | Median per calendar month, measured from alert ingestion to confirmed containment | Monthly | 10% service credit on monthly invoice |
| P2 MTTR (High) | ≤2 hours | Median per calendar month | Monthly | 7% service credit |
| P3 MTTR (Medium) | ≤4 hours | Median per calendar month | Monthly | 5% service credit |
| P4 MTTR (Low) | ≤8 hours | Median per calendar month | Monthly | Documented in review; no credit |
| Alert-to-Triage Time | ≤60 sec (AI initial); ≤10 min (full investigation) | Automated timestamp measurement | Monthly | 5% service credit if monthly median exceeds target |
| False Positive Rate | ≤10% of escalated alerts | Ratio of escalated alerts confirmed benign vs. total escalated | Quarterly | Joint tuning session within 5 business days; 3% credit if sustained >2 months |
📋 Sample SLA Table 2: Uptime, Escalation & Compliance Support
| Metric | SLA Target | Measurement Method | Reporting Cadence | Remedy if Missed |
|---|---|---|---|---|
| Platform Uptime | ≥99.9% | Independent third-party monitoring (e.g., StatusPage, Pingdom) | Monthly | 5% credit per 0.1% shortfall below 99.9% |
| Escalation Time Gates | L0→L1: ≤60 sec (auto); L1→L2: ≤10 min; L2→L3: ≤30 min | Automated workflow timestamps | Monthly | Root-cause report within 48 hrs for any breach of time gate |
| Breach Notification Support | Preliminary report ≤8 hrs of confirmed breach; full forensic report ≤5 business days | Timestamp from breach confirmation to report delivery | Per incident | 15% service credit per incident where timeline is missed |
| After-Action Reporting | RCA within 5 business days of incident closure | Timestamp from incident closure to RCA delivery | Per incident | Documented escalation to account executive; 5% credit if >7 days |
| Compliance Evidence Generation | Automated evidence collection for SOC 2, HIPAA, ISO 27001 | Quarterly audit-readiness validation | Quarterly | Joint remediation plan within 10 business days |
✅ How to Adapt These Tables
These sample clauses are starting points, not gospel. Adjust based on:
- Industry vertical: healthcare and financial services typically need tighter windows (P1 MTTR ≤15 min) due to regulatory pressure and data sensitivity
- Regulatory jurisdiction: GDPR’s 72-hour notification means your breach notification support SLA must leave adequate buffer for legal review; HIPAA’s 60-day window allows more flexibility, but “without unreasonable delay” is the operative standard
- Risk appetite: organizations with high-value IP or customer data should negotiate steeper service credits (15 to 20% for critical metric misses) to ensure accountability
- Measurement methodology: insist on median, not mean, for response time metrics; a single 10-hour outlier should not mask consistent 25-minute performance
One critical point: UnderDefense’s published SLAs already meet or exceed every target in these sample tables, with 2-minute alert-to-triage, 15-minute escalation for critical incidents, 99%+ MITRE ATT&CK coverage, and forever-free compliance kits. That makes these tables a ready-made benchmark for evaluating any AI SOC provider against a provider that already delivers at this level.
💡 Want the full negotiation-ready version? Download the complete AI SOC SLA negotiation template (PDF) with all clause tables, measurement definitions, and penalty structures ready for your legal team → Request the template
Q8: How Do Legacy MDR Providers’ SLAs Compare to AI-Native SOC SLAs?
When you are comparing SLAs across MDR providers, the numbers on paper can look deceptively similar. The real differences lie in measurement methodology, exclusion clauses, and whether the provider actually delivers on operational commitments or just publishes aspirational targets. Here is how legacy MDR architectures compare to AI-native SOC SLAs across the dimensions that matter.
Legacy MDR: The Structural Constraints
Arctic Wolf has built strong brand recognition with a dedicated Concierge Security Team model and comprehensive MDR coverage. The architecture, however, requires proprietary stack replacement. You abandon your existing SIEM and security tools for theirs. Pricing remains opaque, with a reported median annual contract around $96K and no published per-endpoint rates. MTTR targets are not publicly documented, which makes SLA enforcement difficult during contract negotiation.
“We received little value from ArcticWolf. The product offered little visibility when we were using it… Anything you want to look at or changes you need to make in the product must go through their engineering team.”
— Matt C., Manager, Cybersecurity Services Arctic Wolf – G2 Verified Review
“Analysts provide little context, and when asked for more information in the investigation nothing is ever provided or even communicated. Support incidents are not worked to completion and communication evaporates.”
— CISO, Manufacturing Arctic Wolf – Gartner Peer Review
CrowdStrike Falcon Complete excels at endpoint-native detection with best-in-class EDR technology and massive threat intelligence. The limitation is ecosystem lock-in. Falcon Complete operates within the CrowdStrike stack, and OverWatch’s human response layer has been documented as slower than AI-native alternatives in head-to-head comparisons. Pricing runs approximately $60/user/year, positioning it as a premium endpoint solution rather than a full-spectrum MDR.
ReliaQuest offers broad integration capabilities and has received significant investment (~$600M), but reviews consistently cite alert escalation without actionable context. The over-reliance on AI automation without sufficient human follow-through means tickets come back to customers without clear answers: detection without response ownership.
“There have been several instances where we expected [our MDR provider] to identify an issue and no alert was surfaced. Because of this, senior leadership feels, at times, that [the provider] isn’t the right partner for us.”
— Mike S., Information Security Manager, VP Red Canary – G2 Verified Review
AI-Native SOC: The Architectural Difference
UnderDefense approaches the problem from a fundamentally different starting point: vendor-agnostic integration across 250+ existing security tools (no stack replacement), published 2-minute alert-to-triage and 15-minute escalation for critical incidents, ChatOps-based user verification (the only MDR that contacts affected users directly to close alerts), and transparent pricing at $11 to $15/endpoint/month. Forever-free compliance kits (SOC 2, HIPAA, ISO 27001) are included with MDR, not sold as a separate product.
📊 Traditional vs. AI-Native SOC SLA Comparison
| SLA Criterion | Arctic Wolf | CrowdStrike Falcon Complete | ReliaQuest | UnderDefense (AI-Native) |
|---|---|---|---|---|
| MTTR Commitment | Not publicly documented | Not publicly documented | Not publicly documented | ≤30 min (published, median) |
| Uptime Guarantee | Not published | Platform-dependent | Not published | ≥99.9% with independent monitoring |
| Escalation Model | Ticket-based via Concierge Team | OverWatch + Falcon console | AI-automated, limited human follow-through | AI-automated L0 to L1 + concierge analyst L2 + ChatOps verification |
| Breach Notification Support | Not included in base MDR | Incident response available (separate) | Limited forensic support | Preliminary report ≤8 hrs; compliance kits included |
| Pricing Transparency | Opaque (~$96K median/year) | ~$60/user/year | Enterprise-negotiated | Published $11 to $15/endpoint/month |
| Integration Approach | Proprietary stack required | Falcon ecosystem only | Broad but platform-locked | 250+ tools, vendor-agnostic |
| Compliance Inclusion | Separate product | Not included | Not included | Forever-free compliance kits (SOC 2, HIPAA, ISO 27001) |
| User Verification | Escalates back to customer | Escalates back to customer | Escalates back to customer | ✅ Direct ChatOps via Slack/Teams/Email |
✅ Who Should Choose What
- Choose Arctic Wolf if you are starting from scratch with no existing security investments and prefer a single-vendor ecosystem with white-glove deployment
- Choose CrowdStrike Falcon Complete if you are already fully committed to the Falcon stack and want endpoint-native detection with premium threat intelligence
- Choose ReliaQuest if you need broad integration for a large enterprise environment and have strong internal resources to handle escalated investigations
- Choose UnderDefense if you need vendor-agnostic integration that protects your current stack investments, published SLA targets you can hold accountable, and analysts who verify and contain threats, not just detect and escalate
“Arctic Wolf provides solid detection and response capabilities, but overly relies on the client’s team for remediation, which really hurts the value of the service.” — VP of Technology, Services Arctic Wolf – Gartner Peer Review
Q9: Which AI SOC Providers Should You Evaluate for SLA-Backed Protection?
The leading AI SOC providers offering contractual SLA commitments in 2026 include UnderDefense, Dropzone AI, Prophet Security, Torq, and Intezer, each with distinct architectural approaches to detection, triage, and response.
⚠️ Not All “AI SOC” Claims Come With Contractual Teeth
The AI SOC market is growing fast, but there is a wide gap between providers who market AI-driven response times and those who contractually commit to them. Before you shortlist anyone, understand what actually separates SLA-ready providers from the rest.
What separates SLA-ready AI SOC providers:
✅ Published MTTR and alert-to-triage commitments vs. vague “best effort” language buried in marketing copy
✅ Vendor-agnostic integration across your existing SIEM, EDR, and cloud stack vs. proprietary lock-in that forces tool replacement
✅ Service-credit penalties for SLA violations that create real accountability vs. zero financial consequence for missed targets
✅ Human analyst escalation model: concierge-style direct communication vs. ticket-based queues with 24-hour response windows
✅ Compliance support included by default vs. separate add-on products that inflate your total cost of ownership
🔍 The Right Choice Depends on Your Stack
Each provider excels in different scenarios. The right choice depends on your current security stack, regulatory requirements, and whether you need detection-only or full detection + response. For a detailed breakdown with pricing, response times, and integration capabilities, see our comprehensive provider comparison.
📋 Need to estimate SOC costs before evaluating providers? Use the SOC Cost Calculator to benchmark your current spend against managed alternatives.
This analysis is based on documented SLA commitments, G2 reviews, published pricing, and operational outcomes across 500+ MDR deployments.
Q10: AI SOC SLA Negotiation Checklist: 10 Items to Demand Before Signing
Before signing with any AI SOC or MDR provider, verify that your SLA covers these 10 critical areas. Missing even one can leave you exposed during an incident, and I have seen procurement teams skip items here that cost them six figures in unrecoverable response delays.
✅ The 10-Point SLA Procurement Checklist
Use this as a pass/fail scorecard in your next vendor evaluation:
☐ 1. Severity-Tiered MTTR Targets (P1 to P4)
Demand specific time commitments per severity level, not a single blended average. Require the provider to define measurement methodology (mean, median, or P95) and reporting cadence.
☐ 2. Alert-to-Triage Time SLA With AI Investigation Benchmarks
AI triage should complete initial enrichment and classification in under 60 seconds. Full AI investigation in 3 to 10 minutes. Total alert-to-verdict for critical threats: under 20 minutes. If the provider cannot publish these benchmarks, their “AI SOC” is marketing, not architecture.
☐ 3. Platform Uptime Guarantee ≥99.9%
Require defined maintenance windows, independent uptime monitoring, and scheduled reporting. Verify whether uptime includes the detection pipeline or just the customer portal. There is a significant difference.
☐ 4. Escalation Matrix With Named Contacts and Time Gates
The SLA should specify named contacts at each escalation tier, auto-escalation triggers if thresholds are missed, and time gates between Tier 1 → Tier 2 → Tier 3 handoffs.
☐ 5. Breach Notification Support With Regulatory Alignment
Work backwards from your strictest deadline (GDPR: 72 hours, SEC Regulation S-P: 30 days). Your SOC SLA should guarantee detection + containment + preliminary reporting within 48 hours to leave buffer for legal review.
☐ 6. AI Decision Accuracy and False Positive Rate Targets
Request monthly reporting on AI verdict accuracy, false positive reduction rate, and human override frequency. If the vendor refuses to share these numbers, you cannot audit their AI, and unauditable AI is a liability, not a feature.
☐ 7. Service Credit Structure for SLA Violations
Negotiate tiered service credits: 5% per 0.1% uptime shortfall, 10% if MTTR exceeds target by >50%. Include termination rights after repeated SLA breaches within a rolling 90-day window.
☐ 8. Reporting Cadence and Format
Lock in monthly metrics dashboards, quarterly business reviews, and annual SLA review meetings. Ensure reports include raw data, not just summary narratives. You need auditable evidence, not slide decks.
☐ 9. Data Retention, Evidence Preservation, and Chain-of-Custody
Confirm log retention periods align with your compliance framework (most require 12+ months). Verify chain-of-custody protocols for forensic evidence during incident response.
☐ 10. Exit Clause With Data Portability and Knowledge Transfer
Define transition support timelines (minimum 90 days), data export formats, and knowledge transfer obligations. If you own your SIEM, ensure all custom detection rules and correlation logic transfer with you, not stay locked inside the vendor’s platform.
📊 Score Interpretation
| Score | Assessment |
|---|---|
| ✅ 9 to 10 | Enterprise-grade SLA, ready to sign after legal review |
| ⚠️ 6 to 8 | Negotiate the gaps before committing; your provider may be SLA-ready but hasn’t documented it |
| ❌ Below 6 | The vendor is selling monitoring, not managed detection and response. Walk away or demand a rewrite |
How UnderDefense Covers All 10
We built the UnderDefense MAXI platform so that all 10 items are standard, not negotiated as contract appendixes after the fact. Transparent, measurable commitments, 2-minute alert-to-triage and 15-minute escalation for critical incidents, 99% alert noise reduction, 96% MITRE ATT&CK coverage, and published $11 to $15/endpoint/month pricing, are baked into the architecture, not bolted on during procurement.
Q11: Why Your SLA Expectations Need to Catch Up With What AI-Driven SOCs Already Deliver
The gap is not technological but contractual. AI SOCs in 2026 can detect in seconds, investigate in minutes, and contain critical threats in under 30 minutes. Yet most buyers still accept 4-hour MTTR SLAs, unpublished uptime targets, and vague “best effort” escalation language, because that is what vendors trained them to expect.
❌ The “Best Effort” Accountability Problem
Traditional MDR providers benefit from low SLA expectations. Vague commitments mean no accountability. “Best effort” language means missed response times carry no consequences. The vendor gets paid the same whether they contain a threat in 10 minutes or 10 hours. I have watched CISOs accept SLAs they would never tolerate from any other business-critical vendor. Imagine telling your CFO that your cloud provider’s uptime guarantee is “we’ll try our best.”
This is not a technology limitation but an incentive misalignment. When your MDR contract says “reasonable efforts to respond within four hours,” the provider has zero financial motivation to invest in the automation, staffing, or architecture required to consistently hit sub-hour response. The result? You are paying for a promise that nobody is obligated to keep.
⏰ The Technical Barriers Are Gone
In 2026, AI-driven SOCs have eliminated every technical barrier to aggressive SLAs. AI triage completes enrichment and classification in under 60 seconds. Full automated investigation runs in 3 to 10 minutes. Concierge analyst response, verifying suspicious activity directly with affected users via Slack or Teams, closes the context gap that has historically stretched MTTR to hours.
Sub-hour critical MTTR, 99.9%+ platform uptime, and automated breach notification support are not aspirational targets. They are documented, operational realities across leading AI SOC deployments. The only barrier left is the buyer’s willingness to demand what is already achievable.
✅ What UnderDefense Commits To, Contractually
We publish aggressive SLA targets because the UnderDefense MAXI platform and concierge analyst model are engineered to meet them, not as marketing claims, but as contractual obligations with service credits for missed targets.
- 2-minute alert-to-triage and 15-minute escalation for critical (P1) incidents
- 99% alert noise reduction through custom detection tuning and direct user verification
- 96% MITRE ATT&CK coverage across 250+ integrated security tools
- $11 to $15/endpoint/month transparent pricing, published, not hidden behind “contact sales”
- Forever-free compliance kits (SOC 2, ISO 27001, HIPAA) included with MDR
Every one of these numbers is observable, auditable, and reproducible in your own environment within 30 days of onboarding. That is the “show, don’t tell” standard we hold ourselves to.
“It’s reassuring to know they’re always watching for threats, and it doesn’t cost a fortune. They catch and stop problems quickly, which is a huge relief.”
— Serhii B., Chief Information Security Officer UnderDefense – G2 Verified Review
“Their adherence to SLAs gives me confidence in our infrastructure’s protection. As the Information Security Director, it lets me focus on strategy, knowing the day-to-day security is managed effectively.”
— Oleg K., Director Information Security UnderDefense – G2 Verified Review
Stop accepting SLAs written for 2019 SOCs. Request UnderDefense’s SLA documentation and see what AI-driven security operations actually commit to, then ask your current provider why they won’t.
Q12: AI SOC SLA, Frequently Asked Questions
Q1: What is a good MTTR for an AI SOC?
For critical (P1) incidents, target ≤30 minutes total containment time. For high (P2) severity, ≤2 hours. For medium (P3), ≤8 hours. AI-driven SOCs routinely achieve these targets through automated triage and enrichment that eliminates manual investigation bottlenecks. If your provider cannot commit contractually to these numbers, they are underperforming what the technology allows in 2026.
Q2: How do you measure SOC performance in 2026?
Through six core KPIs: Mean Time to Detect (MTTD), Mean Time to Acknowledge (MTTA), Mean Time to Respond (MTTR), Mean Time to Contain (MTTC), AI Decision Accuracy, and False Positive Reduction Rate. Modern SLAs should include all six with defined measurement methodology, specifying whether targets use mean, median, or P95 calculations, and monthly reporting cadence.
Q3: What uptime should a managed SOC guarantee?
Minimum 99.9%, which translates to a maximum of 8 hours and 46 minutes of annual downtime. Regulated industries (healthcare, financial services) should demand 99.95%+ for detection pipelines. Verify whether the uptime SLA covers just the customer portal or the full detection-and-response pipeline. These are often measured separately.
Q4: How fast should AI triage alerts?
AI initial triage, including enrichment, classification, and severity scoring, should complete in under 60 seconds. Full AI investigation with cross-telemetry correlation should finish in 3 to 10 minutes. Total alert-to-verdict for critical threats: under 20 minutes. These benchmarks are documented across leading AI SOC platforms and should be contractually committed, not estimated.
Q5: What SLA penalties should I negotiate with an MDR vendor?
Tiered service credits are the standard: 5% credit per 0.1% uptime shortfall below the guaranteed threshold, and 10% credit if MTTR exceeds the target by more than 50%. Include termination rights after three or more SLA breaches within a rolling 90-day period. Without financial penalties, an SLA is just a marketing document.
Q6: How do breach notification laws affect SOC SLAs?
Work backwards from your strictest regulatory deadline. GDPR requires notification within 72 hours of discovery. SEC Regulation S-P (effective 2025) mandates notification within 30 days. Your SOC SLA should guarantee detection + containment + escalation to your legal team within 48 hours at most, leaving buffer for internal review, evidence packaging, and formal notification drafting.
Q7: What is the difference between MTTA and MTTR?
MTTA (Mean Time to Acknowledge) measures the time until an analyst begins investigating an alert. MTTR (Mean Time to Respond) measures the time until the threat is actually contained. AI SOCs are making MTTA functionally obsolete by investigating alerts instantly through automated enrichment, shifting the focus entirely to MTTR as the definitive performance metric.
Q8: How does UnderDefense’s SLA compare to other AI SOC providers?
UnderDefense publishes contractual commitments: 2-minute alert-to-triage, 15-minute escalation for critical incidents, 99% alert noise reduction, 96% MITRE ATT&CK coverage, and transparent $11 to $15/endpoint/month pricing, with service credits for missed targets. The UnderDefense MAXI platform integrates with 250+ existing tools without forcing vendor replacement, and concierge analysts verify suspicious activity directly with affected users via Slack or Teams. These commitments are validated across 500+ MDR deployments with zero customer churn and a 100% ransomware prevention record over six years.
1. What MTTR should an AI SOC guarantee in its SLA for critical incidents?
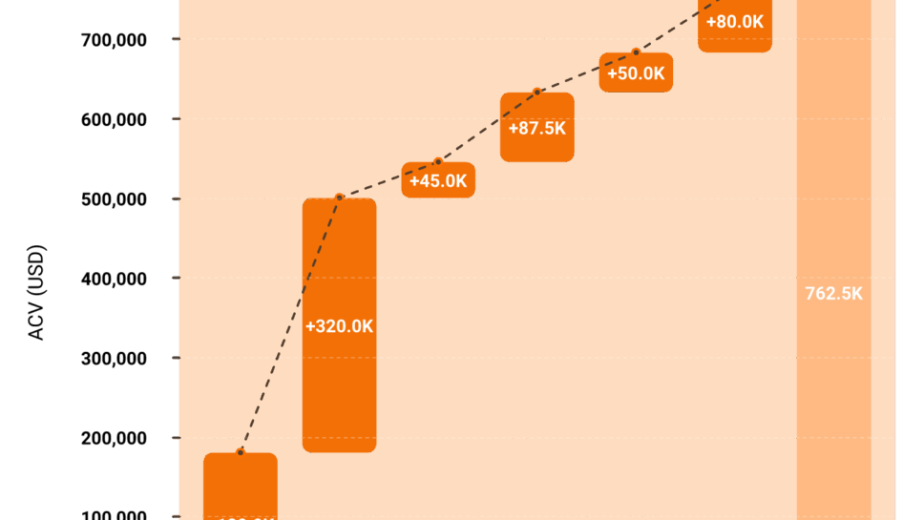
For critical (P1) incidents, we recommend demanding a contractual MTTR of ≤30 minutes for total containment. High (P2) severity should target ≤2 hours, and medium (P3) ≤8 hours. These are not aspirational benchmarks. They reflect what AI-native SOC architectures operationally deliver in 2026 through automated triage, cross-telemetry correlation, and concierge analyst escalation.
The key is measurement methodology. Insist on median, not mean, calculations in your SLA. A single 12-hour outlier can mask months of consistent sub-30-minute performance if you use averages. Monthly reporting cadence with raw data access is the minimum standard.
At UnderDefense, we publish a documented 2-minute alert-to-triage and 15-minute escalation for critical incidents, with service credits if targets are missed. Our SOC performance metrics are transparent, auditable, and validated across 500+ MDR deployments. If your current provider cannot commit to these numbers contractually, they are underperforming what the technology allows.
2. How fast should AI triage and investigate security alerts?
AI initial triage, including enrichment, classification, and severity scoring, should complete in under 60 seconds. Full AI investigation with cross-telemetry correlation (endpoint + identity + cloud + network) should finish in 3 to 10 minutes. Total alert-to-verdict for critical threats should land under 20 minutes.
These benchmarks matter because they define the operational boundary between AI-native SOCs and legacy MDR providers that still rely on manual L1 triage. When AI handles enrichment and classification autonomously, human analysts only enter the chain for novel or ambiguous threats, which compresses the entire detection-to-containment window.
We built the UnderDefense MAXI platform around these benchmarks. AI handles L0 to L1 autonomously, ingesting alerts from 250+ integrated tools, enriching with threat intelligence, and executing automated containment for known patterns. These numbers are contractually committed, not estimated.
3. What uptime guarantee should a managed AI SOC provide?
We recommend demanding a minimum 99.9% uptime guarantee, which translates to a maximum of 8 hours and 46 minutes of annual downtime. Regulated industries like healthcare and financial services should push for 99.95%+ for detection pipelines specifically.
A critical distinction most buyers miss: verify whether the uptime SLA covers just the customer-facing portal or the full detection-and-response pipeline. These are often measured separately, and a vendor can claim 99.9% portal uptime while the detection engine experiences unmonitored outages.
Require independent third-party monitoring (StatusPage, Pingdom, or equivalent), defined maintenance windows, and tiered service credits: 5% per 0.1% shortfall below the guaranteed threshold. At UnderDefense, we guarantee ≥99.9% uptime with independent monitoring and transparent SLA accountability built into every contract.
4. How should an AI SOC escalation process work for critical incidents?
A modern AI SOC escalation model follows capability tiers, not human tiers. AI handles triage and investigation autonomously (L0 to L1 in under 10 minutes), and humans enter the chain only when decision-making requires organizational context or judgment under ambiguity.
The escalation should flow through five steps with strict time gates:
-
L0 AI Triage: 0 to 60 seconds (enrichment, classification, auto-closure of false positives)
-
L1 AI Investigation: 1 to 10 minutes (cross-tool correlation, automated containment)
-
L2 Human Analyst: 10 to 30 minutes (concierge review, novel threat containment)
-
L3 Incident Commander: 30 to 60 minutes (cross-functional response for confirmed breaches)
-
L4 Executive Notification: ≤4 hours (CISO briefing, regulatory notification clock starts)
Demand maximum dwell time at each tier before auto-escalation in your SLA. At UnderDefense, our concierge analysts own L2 containment with a documented 2-minute alert-to-triage and 15-minute escalation for critical incidents, communicating directly via ChatOps with affected users.
5. How do breach notification deadlines affect SOC SLA design?
Breach notification is not a post-incident legal exercise. It is a constraint that back-calculates directly into your SOC SLA. If GDPR gives you 72 hours from awareness to notification, every hour your SOC takes to detect, investigate, and contain compresses the time available for legal review, forensic scoping, and executive approval.
Working backwards from GDPR’s 72-hour deadline: legal review and notification drafting need ≤24 hours, executive briefing ≤4 hours, forensic scoping ≤12 hours, containment ≤4 hours, and detection ≤4 hours. That leaves roughly 21 hours of buffer for unexpected complexity. Your SOC’s detection-to-containment window must complete within approximately 48 hours maximum.
Demand a preliminary incident report within 8 hours of confirmed breach from your provider, because your legal team cannot start notification drafting without it. At UnderDefense, we include forever-free compliance kits and audit-ready incident documentation that accelerates breach notification workflows from days to hours.
6. What SLA penalties should I negotiate with an AI SOC or MDR vendor?
Without financial penalties, an SLA is just a marketing document. We recommend negotiating tiered service credits as the baseline accountability mechanism:
-
5% credit per 0.1% uptime shortfall below the guaranteed threshold
-
10% credit if MTTR exceeds the target by more than 50%
-
15% credit per incident where breach notification support timelines are missed
-
Termination rights after three or more SLA breaches within a rolling 90-day window
The credit structure creates real financial incentive for the provider to invest in the automation, staffing, and architecture required to consistently hit targets. Without it, your vendor has zero motivation to improve after contract signing.
At UnderDefense, service credits for missed targets are standard in every contract, not negotiated as appendixes after the fact. Our MDR pricing is transparent at $11 to $15/endpoint/month, and our SLA commitments are baked into the architecture, not bolted on during procurement.
7. How do legacy MDR providers' SLAs compare to AI-native SOC SLAs?
The numbers on paper can look deceptively similar, but the real differences lie in measurement methodology, exclusion clauses, and operational delivery. Legacy MDR providers like Arctic Wolf, CrowdStrike Falcon Complete, and ReliaQuest typically do not publish MTTR targets, do not offer published uptime guarantees, and rely on ticket-based escalation models that push investigation work back to customers.
AI-native SOCs, by contrast, commit to published response times (≤30-minute critical MTTR), vendor-agnostic integration (no stack replacement), automated L0 to L1 triage, and concierge analyst escalation with direct user verification via ChatOps.
At UnderDefense, we publish every SLA target: 2-minute alert-to-triage, 15-minute escalation for critical incidents, 99%+ MITRE ATT&CK coverage, ≥99.9% uptime, and vendor-agnostic integration across 250+ existing security tools. The comparison is not theoretical. It is documented and reproducible in your environment within 30 days of onboarding.
8. Can we switch from Arctic Wolf to another MDR provider without losing our data and detection logic?
Switching from Arctic Wolf presents challenges across all three lock-in layers. Because Arctic Wolf operates a proprietary cloud-native platform that functions as a SIEM replacement, your logs, detection rules, and historical telemetry all live inside their ecosystem. Multiple Gartner reviewers reported that when they asked Arctic Wolf to provide logs during an investigation, no logs could be provided.
To minimize exit friction, we recommend:
-
Requesting explicit data export terms in writing before signing any contract.
-
Asking what standard formats (JSON, CEF, Syslog) are supported for export.
-
Confirming post-termination data retention policies. Some providers delete data 30 days after contract end.
-
Evaluating BYOS-compatible providers where your data stays in your SIEM from day one.
At UnderDefense, we designed for zero exit friction. Your data stays in your SIEM, your detection rules stay portable, and there is nothing to migrate if you leave. Learn more about how organizations are switching cybersecurity providers without operational disruption.
The post AI SOC SLA in 2026: MTTR, Benchmarks, Clause Tables, Negotiation Checklist appeared first on UnderDefense.