Q1: Why Do Most AI SOC Evaluations Fail Before They Start, and What Framework Fixes That?
Every vendor in the AI SOC space claims “AI-native detection.” Scroll through their landing pages and you’ll find the same language: machine learning, autonomous triage, intelligent alerting. Here’s the operational reality: the majority of these “AI SOC” offerings are repackaged SOAR playbooks or LLM wrappers bolted onto legacy alert pipelines. Choose wrong, and you end up with opaque automation that shifts alert fatigue downstream, vendor lock-in disguised as “platform integration,” and investigation logic you can’t audit or reproduce.
⚠️ The Checklist Trap That Every Vendor Passes
Most evaluations fail because they use legacy MSSP-style feature checklists: Do you support our SIEM? Yes/No. Do you integrate with CrowdStrike? Yes/No. Every vendor passes these. You’re evaluating AI SOC vendors by integration count or brand recognition rather than probing how the AI reasons, what constrains it, and whether accuracy is measured or merely claimed. A 2024 SANS SOC Survey found that 62.5% of SOC teams feel overwhelmed by data volume, a burden that checkbox evaluations do nothing to address. If your RFP doesn’t force vendors to show their work, you’re buying a marketing deck.
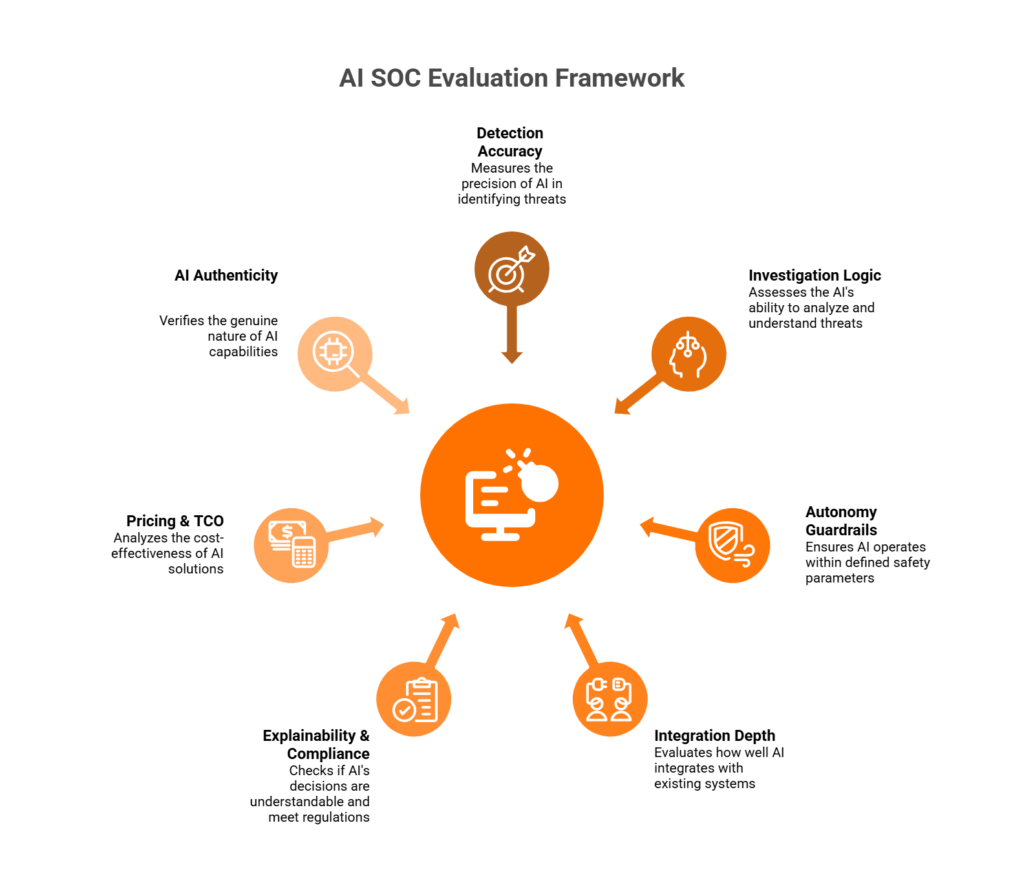
The 7-Pillar Framework + SOC Phase Mapping
We’ve distilled 33 evaluation questions into seven pillars and mapped every question to its relevant SOC workflow stage:
- Detection Accuracy — Is the signal real? (Triage Phase)
- Investigation Logic — Deterministic vs. non-deterministic reasoning (Investigation Phase)
- Autonomy Guardrails — What can AI do without permission? (Response Phase)
- Integration Depth — Does it work with your stack or replace it? (Triage + Investigation)
- Explainability & Compliance — Can you audit the AI’s reasoning chain? (Investigation + Response)
- Pricing & TCO — Is the cost transparent and predictable? (All Phases)
- AI Authenticity — Is it actually AI, or SOAR with a chatbot skin? (All Phases)
Phase Mapping at a Glance:
- Triage (Questions 1–5): Alert quality, confidence scoring, MITRE ATT&CK coverage, false positive rates, detection improvement loops.
- Investigation (Questions 6–10): Deterministic vs. non-deterministic logic, reasoning auditability, hallucination mitigation, fallback paths.
- Response (Questions 11–15): Autonomy governance, pre-action approval, rollback mechanisms, compliance audit logging.
- Integration, Explainability, Pricing, Authenticity (Questions 16–33): Cross-phase questions on depth, transparency, TCO, and proof of genuine AI reasoning.
No competitor structures their evaluation this way. Most stop at feature tables.
✅ Built from Operational Reality, Not Vendor Marketing
These 33 questions were developed from operational experience across 500+ MDR clients and 65,000+ protected endpoints, organizations from 50-person startups to enterprises with 35,000 people. The philosophy behind the framework: AI collects context at machine speed; humans decide and respond with organizational understanding. That’s the “AI SOC + Human Ally” model, a system where every investigative step is observable and auditable, not a black box you’re asked to trust.
⏰ The Baseline Proof Point
In documented case studies, UnderDefense detected threats 2 days faster than CrowdStrike OverWatch, because AI-driven detection paired with human analysts who communicate directly with affected users closes the context gap that pure technology cannot. That’s the standard these 33 questions help you hold every vendor against.
Q2: What Should You Probe on Detection Accuracy and Signal Quality? (Questions 1–5)
Alert fatigue isn’t a buzzword but the #1 operational failure mode in modern SOCs. The average enterprise SOC receives roughly 2,992 alerts daily, yet 63% go unaddressed. Around 83% turn out to be false positives. When analysts are drowning in noise, critical threats slip through, not because people don’t care, but because the signal-to-noise ratio has collapsed beyond human bandwidth. These five questions map directly to the Triage Phase of the SOC workflow, where detection accuracy determines everything downstream.
The Five Questions on Detection Accuracy
| # | Question | ✅ Strong Answer | ❌ Red Flag |
|---|---|---|---|
| Q1 | What is your measured true positive rate on production customer environments, not lab benchmarks? | Specific TP rates from real deployments, with methodology documentation. They can show you the dashboard. | “Our lab tests show 99.9%.” Lab benchmarks are meaningless in messy production environments. |
| Q2 | How do you calculate and report false positive rates, and what is your current customer average? | Published FP reduction metrics (e.g., “99% noise reduction through detection tuning”) with trend data over time. | No specific FP metrics, or “it varies by customer” without aggregated benchmarks. |
| Q3 | What confidence scoring model does the AI use, and can analysts see and override thresholds? | Transparent scores per alert, configurable thresholds per detection type, full visibility into scoring rationale. | Opaque, non-configurable, or absent confidence scoring entirely. |
| Q4 | What % of MITRE ATT&CK techniques do you detect out-of-the-box, and which gaps do you acknowledge? | Specific coverage (e.g., 96%) with honest gap disclosure. Transparent gap acknowledgment signals maturity, not weakness. | Claims “full ATT&CK coverage” without documentation or gap discussion. Every tool has gaps; the question is whether they know theirs. |
| Q5 | How does detection logic improve: analyst feedback loops, anomaly adaptation, or static rule updates? | Hybrid approach: analyst corrections improve accuracy, anomaly detection handles novel threats, detection logic versioned via CI/CD, treated like code. | “We update rules quarterly.” Static rules = always behind the curve. |
💡 Why “Lab Benchmark” Numbers Are Theater
Vendors love presenting detection benchmarks from synthetic environments: controlled datasets, known attack patterns, predictable behavior. Production is nothing like this. Your developers run scripts that look like lateral movement. Your C-suite connects from hotel Wi-Fi in countries you’ve never operated in. Your admins do weird things at 2 AM. If a vendor can’t show you production metrics from real customer environments, those numbers are marketing, not evidence. The right vendor invites you to observe their detection workflows: transparent prompts, observable outcomes, reproducible results. Not “trust me, it works.”
✅ How UnderDefense Approaches Detection Accuracy
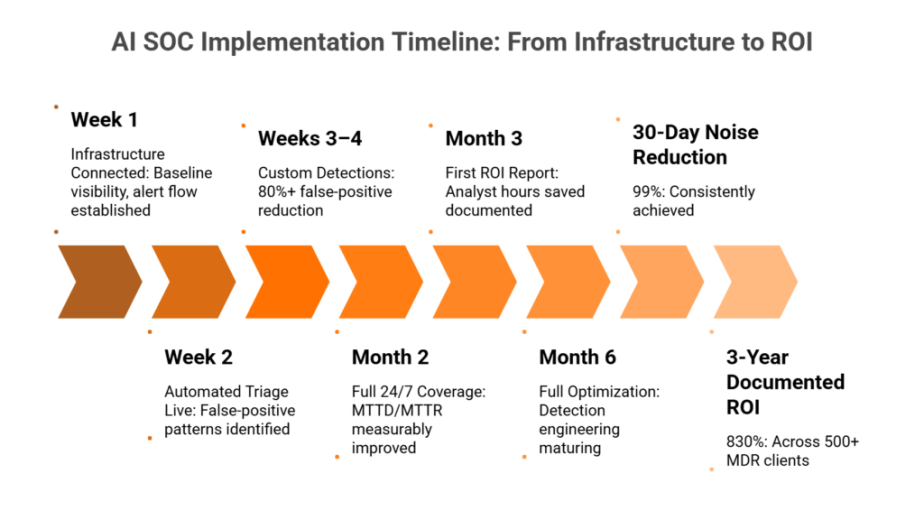
UnderDefense provides 96% MITRE ATT&CK coverage and reduces customer-facing alerts by 99% through custom detection tuning, direct user verification via ChatOps, and a documented 2-minute alert-to-triage SLA. During the 30-day onboarding, we build customized detection rules, testing with MITRE Caldera and Atomic Red Team simulations, to deliver only confirmed, validated offenses. These are concrete, reproducible benchmarks evaluators can hold every other vendor against.
Q3: Is the Investigation Deterministic, Non-Deterministic, or Hybrid, and Why Does It Matter? (Questions 6–10)
This is the most consequential technical distinction in AI SOC evaluation, and the one most buyers skip entirely. The investigation engine is where AI either earns trust or destroys it. If you don’t understand how your vendor’s AI reasons through an alert, and whether that reasoning is reproducible, you’re building your security program on quicksand. These questions map to the Investigation Phase of the SOC workflow.
Defining the Three Approaches
- Deterministic: Fixed, reproducible logic. Same input → same output every time. Automated enrichment, rule-based correlation, structured context collection.
- Non-Deterministic (LLM-based): Probabilistic reasoning that may vary per run. Best for novel threat investigation and contextual triage of ambiguous alerts.
- Hybrid: Deterministic for structured investigation phases, non-deterministic for novel or ambiguous scenarios. Where mature architectures land.
| Dimension | Deterministic | Non-Deterministic |
|---|---|---|
| Best for | Compliance-sensitive containment, audit-ready investigations | Novel threat hunting, unstructured data analysis |
| Reproducibility | ✅ Identical every time | ❌ May vary between runs |
| Hallucination risk | ✅ Zero, logic is coded | ❌ Present in any LLM component |
| Adaptability | ❌ Limited to programmed logic | ✅ Reasons about unfamiliar patterns |
The Five Questions on Investigation Logic
| # | Question | ✅ Strong Answer | ❌ Red Flag |
|---|---|---|---|
| Q6 | Is your investigation engine deterministic, non-deterministic, or hybrid? Can you show the architecture? | Architecture diagram showing which phases use which approach, with clear rationale for each. | “We use AI” without specifying type, architecture, or decision boundaries. |
| Q7 | For which SOC phases do you use each approach? | Clear breakdown: “Deterministic for enrichment and correlation, non-deterministic for novel threat classification, deterministic for response.” | Single approach for everything. No engine should be entirely one type. |
| Q8 | Can you replay the same alert and produce identical output, and audit the full reasoning chain? | Deterministic components: identical replay guaranteed. Non-deterministic: inputs, outputs, and confidence logged for post-hoc audit. | “Outputs are dynamic” with no replay or audit mechanism. If you can’t reproduce it, you can’t defend it to auditors. |
| Q9 | How do you mitigate hallucination risk in LLM-based components? | Deterministic guardrails around LLM outputs, human review checkpoints, confidence thresholds that escalate rather than auto-execute. | Vendor dismisses hallucination risk or claims “our model doesn’t hallucinate.” Every LLM hallucinates. |
| Q10 | If your AI is degraded or unavailable, what’s the fallback, and has it been tested? | Documented fallback: human analysts with playbooks, or deterministic-only mode. Vendor provides last test date. | No fallback, or “99.99% uptime.” Uptime SLAs are not fallback plans. |
⚠️ Why This Matters for Compliance
Under SOC 2, ISO 27001, or HIPAA, auditors will ask: “How does your AI reach conclusions, and can you prove consistent logic?” Deterministic chains provide audit trails you can point to. Non-deterministic reasoning requires additional documentation layers. Hybrid architectures with deterministic structure and guardrailed LLM reasoning are where the industry is heading, but verify, don’t assume, your vendor built it this way.
✅ How UnderDefense MAXI Handles Investigation
UnderDefense MAXI uses deterministic automated context collection: queries your SIEM, pulls logs, enriches with threat intel, and correlates across systems. It then delivers structured investigation reports to human analysts. “AI doesn’t make decisions; it collects context so you can decide.” This eliminates hallucination risk while leveraging AI speed for the mechanical grunt work. Every step is observable and auditable, with no black boxes and no hidden automation.
Q4: What Autonomy Guardrails Prevent the AI From Taking Unvetted Actions? (Questions 11–15)
As AI SOC tools gain agentic capabilities, including auto-containment, credential revocation, and endpoint isolation, ungoverned autonomy becomes as dangerous as the attacks it’s designed to stop. Isolating the wrong endpoint during production, revoking C-suite credentials before confirming compromise, or blocking a legitimate VPN at 2 AM because a threshold was miscalibrated: these aren’t hypotheticals. They happen when autonomy outpaces governance. These questions map to the Response Phase.
The Autonomy Spectrum
| Level | Mode | Description | Recommended For |
|---|---|---|---|
| 0 | Notification Only | AI detects, notifies; humans execute all actions | Initial deployments, ultra-sensitive environments |
| 1 | Recommend + Approve | AI recommends with evidence; human approves before execution | ✅ Most enterprises, the sweet spot for high-impact actions |
| 2 | Auto-Execute + Guardrails | AI executes within confidence thresholds and scope limits | ✅ Low-impact, high-confidence actions (blocking known malicious IPs) |
| 3 | Full Autonomous | AI detects, decides, executes without human input | ❌ Never appropriate for high-impact actions |
Most enterprises should sit at Level 1–2 for critical systems. Level 3 is a ticking time bomb regardless of AI quality.
The Five Questions on Autonomy Guardrails
| # | Question | ✅ Strong Answer | ❌ Red Flag |
|---|---|---|---|
| Q11 | What actions can your AI execute autonomously? Can I see the complete list? | Documented action inventory categorized by impact level. Autonomous execution limited to low-impact actions. | “Our AI handles response automatically” without an action inventory. |
| Q12 | What confidence threshold triggers autonomous action, and can I adjust it per action type? | Configurable per action type, adjustable in real time. Customer controls: “Block malicious IP at 85%, require approval for isolation.” | Fixed, vendor-defined thresholds. Your risk tolerance isn’t every customer’s. |
| Q13 | Can I set scope limits per asset class, such as “never isolate DCs” or “never revoke C-suite creds without approval”? | Per-asset-class policies with granular controls and asset tagging for custom protection rules. | No asset-class differentiation. Dev laptop = domain controller = disaster waiting to happen. |
| Q14 | What’s the rollback mechanism and MTTR if autonomous action causes disruption? | One-click automated rollback with tested recovery times. Vendor shows last test date. | Rollback requires a support case. If AI acts in seconds but reversal takes hours, the math fails. |
| Q15 | How is every autonomous action logged for compliance audit (SOC 2, ISO 27001, HIPAA)? | Immutable logs: timestamp, action, confidence, trigger, approving authority, affected assets. Export-ready. | Incomplete logging, missing confidence scores or triggering context. |
💰 When Autonomy Goes Wrong
A managed security provider auto-quarantined domain controllers because their policy didn’t differentiate asset classes. Nobody could authenticate. VPN went down. Email stopped. Production halted four hours. The “threat”? A miscategorized alert from a legitimate admin script. The response caused more damage than the threat ever would have. This is why autonomy governance isn’t optional.
✅ How UnderDefense Handles Autonomy
UnderDefense operates a written pre-authorization model: containment actions require customer pre-approval per asset class, with documented escalation paths. ChatOps verification via Slack and Teams means a human ally confirms context with affected users before high-impact actions execute. We learn who your VIPs are, ask technical users about suspicious activity, and loop in managers for security-impacting changes. AI speed with human judgment, never AI alone.
Q5: How Deep Is the Integration, or Will You Face Vendor Lock-In? (Questions 16–20)
Integration depth is the most common evaluation blind spot. Vendors claim “200+ integrations,” but few explain whether your business logic, including custom correlation rules, detection tuning, and automation workflows, survives a vendor switch. These 5 questions expose real integration depth vs. checkbox claims.
⚠️ The Lock-In Question Nobody Asks Early Enough
Here’s what happens in practice: you onboard an MDR provider, spend months building custom detection rules and fine-tuning alert logic within their platform, and three years later realize your correlation rules, your playbooks, and your institutional knowledge are trapped. Switching providers means starting from scratch. This is the vendor lock-in tax that never shows up in a pricing table.
- Q16: Do you require replacing any existing security tools (SIEM, EDR, SOAR), or do you layer on top of our current stack? ✅ Strong answer: “We integrate with your existing tools, no replacement required.” ❌ Red flag: “Our platform works best when you use our proprietary SIEM.” That’s not integration but acquisition.
- Q17: How many integrations are API-native vs. syslog/generic, and what’s the functional difference in detection fidelity? ✅ Strong answer: API-native integrations pull structured, enriched data. Syslog-only means raw logs without context, and detection fidelity drops significantly.
- Q18: If we terminate the relationship, do our custom correlation rules, detection tuning, and playbooks come with us? ✅ Strong answer: “Yes, your business logic lives in your SIEM, not ours.” ❌ Red flag: “Our detection logic is proprietary.”
- Q19: What is the documented onboarding timeline from contract signature to production monitoring? ✅ Strong answer: 30 days or fewer, with defined milestones and a security hardening phase included.
- Q20: Can you demonstrate a live integration with our specific stack during the proof-of-value? ✅ Strong answer: “Yes, bring your stack, and we’ll show you during POV.” ❌ Red flag: “We’ll need 6 months of professional services to integrate.”
💡 The CISO Perspective on Data Ownership
The smartest CISOs frame it this way: “I want to control where my data lives. If I switch providers, my business logic, my correlation rules, my automation, that stays with me.” If your vendor can’t guarantee this, you’re renting security intelligence, not building it.
✅ How UnderDefense Handles Integration
UnderDefense integrates with 250+ existing tools, including CrowdStrike, SentinelOne, Splunk, Microsoft Sentinel, Okta, and more, without requiring stack replacement. Our analysts log into your system, not the other way around. Business logic stays in your SIEM. Onboarding takes 30 days with custom detection tuning from day one.
“The platform seamlessly integrates our existing security tools, simplifying management. Plus, it’s incredibly easy to deploy. I used to work with many MDR solutions in the past, and so far Underdefense is the best one!”
— Inga M., CEO UnderDefense – G2 Verified Review
“We received little value from ArcticWolf. The product offered little visibility… Anything you want to look at or changes you need to make in the product must go through their engineering team.”
— Matt C., Manager, Cybersecurity Services Arctic Wolf – G2 Verified Review
“UnderDefense MAXI integrates well with our systems, specifically with our SIEM, Splunk. Their team is proactive in identifying and addressing threats, providing 24/7 oversight.”
— Oleg K., Director Information Security UnderDefense – G2 Verified Review
Q6: Can the AI Explain Its Decisions, and Will It Hold Up in a Compliance Audit? (Questions 21–24)
Regulators, auditors, and boards now ask: “How did the AI reach that conclusion?” An AI SOC that can’t produce a human-readable reasoning chain for every investigation is a compliance liability, not an asset. This applies across all SOC phases: triage decisions, investigation conclusions, and response actions must all be auditable. The relevant frameworks are specific: SOC 2 Trust Services Criteria CC7.2 (monitoring), ISO 27001 A.12.4 (logging and monitoring), and HIPAA § 164.312 (audit controls).
The Four Questions on Explainability & Compliance
| # | Question | ✅ Strong Answer | ❌ Red Flag |
|---|---|---|---|
| Q21 | For every investigation, can you produce a human-readable reasoning chain showing what data was collected, what logic was applied, and what conclusion was reached, exportable for audit? | Every investigation generates a structured report: data sources queried, correlation logic applied, confidence score, recommended action, and outcome. Exportable as PDF or API-accessible. | “Our AI handles investigations automatically.” Without a visible reasoning chain, you can’t defend the conclusion to an auditor. |
| Q22 | Does the platform automatically generate compliance evidence artifacts mapped to SOC 2 / ISO 27001 / HIPAA requirements? | Compliance evidence is a byproduct of security operations: audit logs, incident reports, and control attestations auto-map to framework requirements. No separate tool needed. | Compliance requires a separate product or manual evidence collection. If security operations don’t generate evidence natively, you’re paying twice. |
| Q23 | What RBAC model governs who can configure AI behavior, approve autonomous actions, and access investigation details, and is it auditable? | Granular RBAC with documented role definitions, audit logs for every configuration change, and separation of duties between AI configuration and response approval. | No RBAC differentiation, or “admins can do everything.” That’s a governance gap auditors will find. |
| Q24 | How do you handle data residency, tenant isolation, and PII exposure in AI-processed investigation data? | Customer data stays in your region, tenant isolation is architecturally enforced, and PII is masked in AI processing. Vendor can show SOC 2 Type II attestation. | Vague answers about “cloud security” without specific data residency commitments or tenant isolation documentation. |
💰 The Hidden Cost of Non-Explainable AI
Here’s the compliance math: if your AI SOC takes an autonomous action, say isolating an endpoint at 3 AM, and an auditor asks “why?”, you need a documented answer. Not “the AI decided.” A timestamped chain: alert triggered → data collected → correlation applied → confidence score exceeded threshold → action pre-authorized per asset policy → action executed. Without this, every autonomous action is an audit finding waiting to happen.
✅ How UnderDefense Delivers Audit-Ready Explainability
Every UnderDefense MAXI investigation produces a structured, exportable report with full reasoning chain: what was detected, what context was collected, what correlation was applied, and what action was recommended or taken. Forever-free compliance kits (SOC 2, ISO 27001, HIPAA) are included with MDR. Compliance evidence is a byproduct of security operations, not a separate line item. Every investigative step is observable, auditable, and ready for your next audit without additional cost or tooling.
Q7: What Does Total Cost of Ownership Really Look Like, and Where Are the Hidden Charges? (Questions 25–28)
You signed what looked like a reasonable AI SOC contract, $96K/year for “comprehensive AI-driven detection and response.” Six months in: overage charges for alert volume, professional services fees for detection tuning, a separate compliance module at $24K/year, and a 3-year lock-in with 15% annual escalators. Your “predictable” security spend just became your most unpredictable budget line.
⚠️ Why Pricing Pain Runs Deeper Than the Invoice
This happens because most MDR vendors use pricing models designed to obscure true cost. Per-alert pricing punishes you for having a noisy environment. Per-user pricing scales unpredictably with headcount. And “contact sales” pricing means every customer pays a different rate based on negotiation leverage, not value delivered. The real question isn’t “what does it cost?” but “what will it cost in 18 months when your environment has grown?”
| Pricing Model | Pros | Cons | 🔴 Watch For |
|---|---|---|---|
| Per-Endpoint | Predictable, scales with infrastructure | Doesn’t account for cloud-only environments | Endpoint definitions that exclude servers or cloud workloads |
| Per-Alert | Aligns cost with activity | Punishes noisy environments; vendor has no incentive to reduce alerts | Overage charges that double your bill when alert volume spikes |
| Per-User | Aligns with headcount | Unpredictable with growth; doesn’t reflect security complexity | Automatic tier escalation when you add employees |
| Flat-Fee | Simple budgeting | May not scale; vendor may throttle service if scope exceeds estimates | Hidden scope limitations buried in contract appendices |
The Four Questions on TCO
- Q25: What is your pricing model, per endpoint, per alert, per user, or flat, and what is the exact per-unit cost? If you need a “custom quote call” to learn the price, that’s a red flag, not a premium buying experience.
- Q26: What is explicitly NOT included in the base price? Ask for the full list: detection tuning, compliance, onboarding, custom integrations, professional services, and API access. If they can’t enumerate exclusions, those exclusions will find you later.
- Q27: What happens when alert volume or endpoint count exceeds scope? Are there overage charges, throttling, or automatic tier escalation?
- Q28: What are the contract termination terms, minimum commitment, and data portability guarantees? Can you leave in 30 days, or are you locked in for 36 months?
💸 How It Should Work
Pricing should be published, predictable, and all-inclusive. The price on the website should be the price you pay, no surprises at month six.
✅ UnderDefense’s Transparent Model
UnderDefense publishes $11–15/endpoint/month. Forever-free compliance kits (SOC 2, ISO 27001, HIPAA) are included. 30-day onboarding is included. No alert volume overage charges. No hidden professional services fees. Contrast that with Arctic Wolf’s opaque median $96K annual contract or CrowdStrike’s “contact sales” model where pricing requires a conversation, not a webpage.
“UnderDefense is surprisingly affordable considering the level of protection we get. Their proactive threat hunting and rapid response have saved us from incidents that could have been incredibly costly.”
— Verified User in Program Development UnderDefense – G2 Verified Review
“Beware they add a 60 day renewal notice instead of the typical 30 day notice. If you don’t give notice of cancelling any services before 60 days, you will automatically renew everything.”
— Verified User in Electrical/Electronic Manufacturing Arctic Wolf – G2 Verified Review
Q8: How Do You Separate Real AI From Vendors Wrapping Hype in a Dashboard? (Questions 29–33)
Choosing an AI SOC platform means betting your security operations on a vendor’s AI claims. Get it wrong, and you invest in “AI” that can’t adapt to novel threats, can’t explain its reasoning, and breaks when the LLM API goes down. The stakes are too high for demos and slide decks to be your evaluation method.
❌ The Wrong Way to Decide
Most evaluators accept demos at face value. They don’t ask: What happens if I replay the same alert? What happens if the AI layer is disabled? Is this a proprietary model or a third-party API wrapper? These questions separate procurement from performance. If the vendor can run a compelling demo but can’t answer what’s under the hood, the demo is the product, and production reality will look very different.
The AI Authenticity Test: Questions 29–33
- Q29: Can you demo the product with the AI/ML layer completely disabled? What still functions? This reveals what’s genuinely AI-powered vs. traditional automation with an AI label. If disabling AI breaks everything, you’re dependent on a single point of failure. If nothing changes, the “AI” may be cosmetic.
- Q30: Is your AI a proprietary model, a fine-tuned open-source model, or a wrapper around a third-party LLM API? Each carries different risk profiles. Wrappers around OpenAI or Anthropic mean you inherit their outages, model deprecations, and data handling policies.
- Q31: What happens to detection and investigation if your AI model provider experiences an outage or deprecates the model you depend on? Vendor must have a documented continuity plan, not just “we’ll switch models.”
- Q32: Can you provide a technical architecture diagram showing exactly where AI/ML operates vs. where static rules or SOAR playbooks operate? Genuine AI-native vendors show this instantly. Vendors that rebrand SOAR as “AI” will struggle to produce one.
- Q33: What independent benchmarks, third-party audits, or peer-reviewed research validate your AI’s detection and investigation claims? G2 badges, Gartner recognition, and documented case studies with named customers, not self-published whitepapers.
⭐ Scoring the AI Authenticity Test
| Score | Interpretation |
|---|---|
| 8–10 | Genuine AI-native architecture with documented, auditable AI reasoning |
| 5–7 | Partial AI with significant rule-based components. May still be viable, but probe the boundaries carefully |
| Below 5 | You’re buying automation rebranded as AI. Expect demo-quality performance, not production resilience |
Score each vendor 0–2 per question. Vendors in the 8–10 range can show their work and welcome the scrutiny. Below 5, the “AI” claim doesn’t survive operational testing.
✅ Where UnderDefense Stands
UnderDefense MAXI‘s agentic AI automates context collection, multi-system correlation, and structured investigation, but does so transparently. No proprietary magic. No hidden automation. No “trust-me-it-works.” Observable workflows, reproducible results, and AI that augments analysts rather than replacing them. UnderDefense earned the 2025 Global Infosec Award for MDR, holds 12 G2 badges including Best Support recognition, and was named a 2025 SC Awards finalist: independent validation you can verify, not vendor claims you’re asked to believe.
Q9: Your 33-Question AI SOC Scorecard + 2-Week Proof-of-Value Playbook
You’ve read about what to evaluate. Now here’s the tool that makes evaluation mechanical, not political, not vibes-based, not driven by whoever has the best demo.
📋 Part A: The 33-Question Scorecard
Score each vendor 0 (no/weak), 1 (partial), or 2 (strong). Max = 66.
Pillar 1: Detection Accuracy (Triage Phase)
- ☐ Q1. What is the vendor’s documented false positive rate?
- ☐ Q2. What MITRE ATT&CK coverage can they prove, not claim?
- ☐ Q3. Does detection logic adapt per customer environment?
- ☐ Q4. Can they show alert-to-triage time with production data?
- ☐ Q5. How does the system handle novel, unseen threats?
Pillar 2: Investigation Logic (Investigation Phase)
- ☐ Q6. Are investigations deterministic or non-deterministic?
- ☐ Q7. Replay the same alert. Do you get the same output?
- ☐ Q8. Does the AI collect context across identity, endpoint, cloud, and SaaS?
- ☐ Q9. Is the reasoning chain visible and auditable?
- ☐ Q10. Can a senior analyst override AI conclusions at every step?
Pillar 3: Autonomy Guardrails (Response Phase)
- ☐ Q11. Is written pre-authorization required before autonomous actions?
- ☐ Q12. Are response actions scoped by asset class?
- ☐ Q13. Can you define per-action approval workflows?
- ☐ Q14. Is there a kill switch to halt all autonomous actions?
- ☐ Q15. Does the system verify with affected users before containment?
Pillar 4: Integration Depth (Cross-Cutting)
- ☐ Q16. How many tools does the platform integrate with natively?
- ☐ Q17. Does it replace your SIEM/EDR, or layer on top?
- ☐ Q18. Can integration complete in under 30 days?
- ☐ Q19. Does it support on-prem, cloud, and hybrid?
- ☐ Q20. Do you retain ownership of logs, rules, and AI data?
Pillar 5: Explainability & Compliance (Governance)
- ☐ Q21. Does every AI action produce a human-readable explanation?
- ☐ Q22. Can reports be exported for SOC 2, HIPAA, and ISO 27001 audits?
- ☐ Q23. Is there a complete audit trail of decisions and overrides?
- ☐ Q24. Is compliance evidence collection included, or extra?
Pillar 6: Pricing & TCO (Commercial)
- ☐ Q25. Is pricing published per-endpoint/month?
- ☐ Q26. Are there hidden fees for onboarding, tuning, or compliance?
- ☐ Q27. What is 3-year TCO including SIEM, analysts, and licensing?
- ☐ Q28. Does the contract include data portability?
Pillar 7: AI Authenticity (Validation)
- ☐ Q29. Can you observe the AI’s workflow in real time?
- ☐ Q30. Has the vendor published independent benchmarks?
- ☐ Q31. Does the AI produce different outputs for the same input?
- ☐ Q32. Can they run a purple-team exercise during evaluation?
- ☐ Q33. Is this production AI, or an LLM chatbot on a legacy SIEM?
✅ Score Interpretation
| Score | Assessment | Action |
|---|---|---|
| 50–66 | Enterprise-grade AI SOC candidate | Proceed to POV |
| 35–49 | Gaps exist; investigate before committing | Probe weak pillars |
| Below 35 | Not ready, likely cosmetic AI | Walk away |
📐 Part B: 2-Week POV Playbook
A scorecard shows claims. A POV shows delivery. Require these 8 conditions:
- ⏰ Production environment, not a sandboxed demo
- Your actual SIEM/EDR/identity data sources connected
- Success metrics defined upfront: MTTI, MTTR, TP rate, and FP reduction %
- Daily investigation summaries during POV
- AI conclusions compared against your analysts’ independent verdicts
- Deterministic reproducibility: replay same alert, confirm same output
- At least one purple-team exercise against known TTPs
- All POV data and configs exportable and owned by you
POV Readiness: ✅ 7–8 = confident vendor. ⚠️ 4–6 = caution. ❌ 0–3 = walk away.
How UnderDefense Handles This
We offer a 30-day onboarding that functions as an embedded proof of value: production environment, your stack, your data, documented outcomes from day one. Every investigation is observable. Every metric is measurable.
💰 Download this scorecard as a free, ungated PDF or Google Sheet for your next vendor evaluation.
Q10: Which AI SOC Architecture Fits Your Security Operations Model?
AI SOC platforms fall into three architectural categories, All-AI Autonomous, AI + Human Hybrid, and AI-Augmented Human-Led, each suited to different operational maturity levels, team sizes, and risk tolerances.
What Separates the Three Models
The architecture your organization needs depends on five factors:
- Autonomy level: full autonomous response vs. human-in-the-loop vs. human-led with AI augmentation
- Integration approach: proprietary stack replacement vs. vendor-agnostic layering over existing tools
- Response model: detection-only vs. detection + containment vs. full managed response with user verification
- Pricing transparency: published per-endpoint rates vs. opaque “contact sales” quotes
- Compliance integration: bundled audit evidence and frameworks vs. separate add-on products
How Each Architecture Maps to Your Team
| Architecture | Best For | Strength | Limitation |
|---|---|---|---|
| All-AI Autonomous | Orgs with deep ML expertise wanting full automation | Speed, no human latency | Black-box risk; no org context; hallucination exposure |
| AI + Human Hybrid | Enterprises wanting AI speed with human oversight | Balanced: AI handles volume, humans handle judgment | Requires clear guardrails and handoff protocols |
| AI-Augmented Human-Led | Teams wanting control while eliminating grunt work | Human judgment preserved; AI accelerates mechanical tasks | Slower than full autonomy for routine incidents |
Matching Architecture to Reality
Each architecture fits a different scenario. All-AI Autonomous works for organizations with in-house ML engineering capable of governing autonomous systems. AI + Human Hybrid suits enterprises wanting AI speed for triage with human judgment for containment. AI-Augmented Human-Led fits teams that want to maintain control while offloading repetitive investigation work that causes burnout.
The right choice depends on your existing stack, team maturity, and risk posture. If you’re running CrowdStrike, Splunk, and Okta without wanting to replace them, you need a vendor-agnostic architecture, not one that forces proprietary replacement.
📋 Full Provider Breakdown
💸 SOC Cost Calculator
Not sure what building vs. buying costs? Use the UnderDefense SOC Cost Calculator →
This analysis is based on documented response times, G2 reviews, published pricing, and operational outcomes across 500+ security operations deployments.
Q11: How Does the AI SOC + Human Ally Model Score Against All 33 Questions?
Most AI SOC vendors score well on one or two pillars, usually detection and integration, but collapse on autonomy guardrails, explainability, pricing transparency, and AI authenticity. The market rewards vendors good at marketing AI, not operationalizing it.
The False Binary That Breaks Evaluation
Here’s the trap: buyers choose between “all-AI” platforms promising full autonomy with black-box investigation, or “AI-labeled” platforms running static rules with an LLM chatbot on top. Neither delivers what security operations need: AI speed for mechanical investigation combined with human judgment for context, verification, and high-stakes decisions.
The all-AI camp can’t answer “Was that Jane or an attacker?” The AI-labeled camp summarizes alerts you already read. Both leave your team doing the hard work.
The Synthesis: AI SOC + Human Ally
UnderDefense’s model addresses this by design. UnderDefense MAXI‘s agentic AI automates context collection, multi-system correlation, and structured investigation at machine speed. But the AI doesn’t decide; it delivers findings to dedicated concierge analysts who verify with users via ChatOps, apply organizational context, and execute response within pre-approved guardrails.
This isn’t theoretical but an operational reality you can observe. Every investigative step is auditable, every AI conclusion reviewable, and every response action maps to pre-authorized playbooks.
Pillar-by-Pillar Scoring
| Pillar | Score | Evidence |
|---|---|---|
| Detection Accuracy | ✅ Strong | 96% MITRE ATT&CK, 99% noise reduction, 2-minute triage |
| Investigation Logic | ✅ Strong | Deterministic context collection: “AI collects, you decide” |
| Autonomy Guardrails | ✅ Strong | Written pre-authorization, per-asset scoping, ChatOps verification |
| Integration Depth | ✅ Strong | 250+ tools, customer-owned SIEM, 30-day onboarding |
| Explainability | ✅ Strong | Structured reports with full reasoning chain, forever-free compliance kits |
| Pricing & TCO | ✅ Strong | $11–15/endpoint/month published, all-inclusive |
| AI Authenticity | ✅ Strong | Observable workflows, reproducible results, no black boxes |
What This Looks Like at 2:47 AM
UnderDefense MAXI flags a suspicious OAuth grant. Instead of generating a “please investigate” ticket, it collects login history, cross-references identity provider data, checks endpoint behavior, and delivers structured findings to the concierge analyst. The analyst pings the user via Slack: “Did you authorize this app?” Confirmed, case closed. Denied, credentials revoked, session killed, endpoint isolated. You review the report over coffee. That’s the difference.
“Not having to worry about ransomware, alert overload and reporting. They literally took care of all our problems.”
— Arlin O., Enterprise UnderDefense – G2 Verified Review
“It lets me focus on strategy, knowing the day-to-day security is managed effectively.”
— Oleg K., Director Information Security UnderDefense – G2 Verified Review
100% ransomware prevention record across 500+ MDR clients, because detection without human-driven response is just expensive alerting. Read the case study: UnderDefense Detects a Cyberthreat Faster Than CrowdStrike OverWatch →
1. What are the most important questions to ask when evaluating AI SOC vendors?
We recommend structuring your evaluation around 33 questions across seven pillars: Detection Accuracy, Investigation Logic, Autonomy Guardrails, Integration Depth, Explainability & Compliance, Pricing & TCO, and AI Authenticity. Each pillar maps to a specific SOC workflow phase, so you’re testing operational delivery, not just feature lists.
Start with detection: ask for production false positive rates, not lab benchmarks. Move to investigation logic: demand to know whether reasoning is deterministic, non-deterministic, or hybrid, and whether you can replay the same alert and get the same output. Probe autonomy guardrails to understand what the AI can do without human approval. Test integration depth by asking whether your business logic survives a vendor switch. Verify explainability by requiring audit-ready reasoning chains for every investigation. Check pricing transparency by asking what’s explicitly excluded from the base price. Finally, run the AI authenticity test: ask the vendor to demo with the AI layer disabled.
Score each question 0–2 for a max of 66. Vendors scoring 50+ are enterprise-grade candidates. Below 35, walk away. We’ve built this SOC provider evaluation checklist from operational experience across 500+ MDR clients.
2. What is the difference between deterministic and non-deterministic AI in SOC operations?
Deterministic AI produces identical output for the same input every time. It’s coded logic: enrichment queries, rule-based correlation, and structured context collection. Non-deterministic AI (typically LLM-based) uses probabilistic reasoning that may vary between runs, making it better for novel threat investigation but harder to audit.
The distinction matters because compliance frameworks like SOC 2, ISO 27001, and HIPAA require reproducible investigation logic. If an auditor asks “how did the AI reach this conclusion?” and the answer changes with each replay, that’s an audit finding.
We believe the right architecture is hybrid: deterministic for structured investigation phases (enrichment, correlation, and response execution) and non-deterministic for novel or ambiguous scenarios, with guardrails around every LLM output. At UnderDefense, our MAXI platform uses deterministic automated context collection and delivers structured findings to human analysts, eliminating hallucination risk while leveraging AI speed for mechanical work.
3. What autonomy guardrails should an AI SOC platform have?
Autonomy guardrails control what the AI can do without human approval. Without them, you risk isolating the wrong endpoint during production, revoking C-suite credentials before confirming compromise, or blocking a legitimate VPN because a threshold was miscalibrated.
We recommend requiring five governance controls from every vendor:
-
Written pre-authorization required before any autonomous action
-
Response actions scoped by asset class (production servers vs. developer endpoints)
-
Per-action approval workflows configurable by your team
-
A global kill switch to halt all autonomous actions immediately
-
User verification via ChatOps before containment of high-value assets
Ask to see the vendor’s autonomy governance matrix. If they can’t show one, their “agentic AI” is ungoverned automation. We’ve detailed this framework further in our guide on AI SOC promise vs. reality.
4. How do you run a proof of value for AI SOC platforms?
A scorecard evaluates claims. A proof of value (POV) evaluates delivery. We recommend a 2-week POV in your production environment with eight non-negotiable conditions:
-
Your actual SIEM, EDR, and identity data sources connected
-
Success metrics defined upfront: MTTI, alert-to-triage time, TP rate, and FP reduction %
-
Daily investigation summaries during the POV period
-
AI conclusions compared against your analysts’ independent verdicts
-
Deterministic reproducibility testing (replay the same alert, confirm the same output)
-
At least one purple-team exercise against known TTPs
-
All POV data and configurations exportable and owned by you
Score the vendor 0–8 on these conditions. Vendors scoring 7–8 are confident in their product. Below 4, walk away. At UnderDefense, we offer a 30-day onboarding that functions as an embedded proof of value: production environment, your stack, your data, with documented outcomes from day one.
5. How can you detect AI-washing in cybersecurity vendors?
AI-washing happens when vendors label SOAR playbooks or LLM chatbot wrappers as “AI-native” detection. We use a 5-question authenticity test to separate real AI from marketing:
-
Can the vendor demo with the AI/ML layer completely disabled? What still functions?
-
Is the AI a proprietary model, a fine-tuned open-source model, or a wrapper around a third-party LLM API?
-
What happens if the AI model provider experiences an outage or deprecates the model?
-
Can they provide a technical architecture diagram showing exactly where AI/ML operates vs. static rules?
-
What independent benchmarks or third-party audits validate their AI claims?
Score each question 0–2. Vendors scoring 8–10 have genuine AI-native architecture. Below 5, you’re buying automation rebranded as AI. We’ve seen this pattern repeatedly across MDR vendor evaluations, where demo-quality performance masks production-reality gaps.
6. What should an AI SOC RFP template include?
Your AI SOC RFP should go beyond feature checklists. We recommend structuring it around 33 evaluation questions grouped into seven pillars, with scoring criteria and a mandatory proof-of-value requirement.
Each pillar should include weighted scoring:
-
Detection Accuracy (Questions 1–5): Production TP rates, MITRE ATT&CK coverage, FP metrics, confidence scoring, detection improvement loops
-
Investigation Logic (Questions 6–10): Deterministic vs. non-deterministic architecture, reproducibility, hallucination mitigation, fallback plans
-
Autonomy Guardrails (Questions 11–15): Pre-authorization, asset-class scoping, kill switches, user verification
-
Integration Depth (Questions 16–20): API-native vs. syslog, data portability, onboarding timeline
-
Explainability & Compliance (Questions 21–24): Reasoning chains, compliance evidence automation, RBAC, data residency
-
Pricing & TCO (Questions 25–28): Published rates, exclusion lists, overage policies, termination terms
-
AI Authenticity (Questions 29–33): Disable-AI demo, architecture diagrams, independent validation
Download a free, ungated version from our SOC provider evaluation checklist to use in your next procurement cycle.
7. How much does an AI SOC or MDR service cost, and what hidden fees should you watch for?
Transparent providers publish pricing. We publish $11–15/endpoint/month, all-inclusive: 30-day onboarding, custom detection tuning, forever-free compliance kits (SOC 2, ISO 27001, HIPAA), and no alert volume overage charges.
Most vendors hide behind “contact sales” models. Common hidden fees include:
-
Professional services for detection tuning ($10K–$50K annually)
-
Separate compliance modules ($24K/year or more)
-
Alert volume overage charges that spike unpredictably
-
Automatic tier escalation when headcount grows
-
3-year lock-ins with 15% annual price escalators
-
60-day cancellation notice windows buried in contract appendices
Ask every vendor: “What is explicitly NOT included in the base price?” If they can’t enumerate exclusions, those exclusions will surface later. Calculate 3-year TCO including SIEM ingestion, analyst hours, licensing, and data portability costs. Use our SOC cost calculator for a side-by-side comparison.
8. What is the AI SOC + Human Ally model, and how does it compare to full automation?
The AI SOC + Human Ally model pairs agentic AI (for context collection, multi-system correlation, and structured investigation at machine speed) with dedicated human analysts who verify findings, apply organizational context, and execute response within pre-approved guardrails.
Unlike full-automation models, the Human Ally approach eliminates two critical risks: black-box decisions that can’t be audited, and AI hallucinations that lead to wrong containment actions. Unlike AI-labeled platforms that simply summarize alerts, this model offloads mechanical grunt work so analysts focus on judgment calls.
At UnderDefense, this works in practice: MAXI flags a suspicious event, collects login history across identity providers, cross-references endpoint behavior, and delivers structured findings to the concierge analyst. The analyst verifies with the affected user via Slack or Teams. Confirmed legitimate: case closed. Confirmed malicious: credentials revoked, session killed, endpoint isolated, all within a 2-minute alert-to-triage and 15-minute escalation SLA for critical incidents. This model earned us 100% ransomware prevention across 500+ MDR clients.
The post 33 Questions to Ask while evaluating AI SOC Vendors appeared first on UnderDefense.