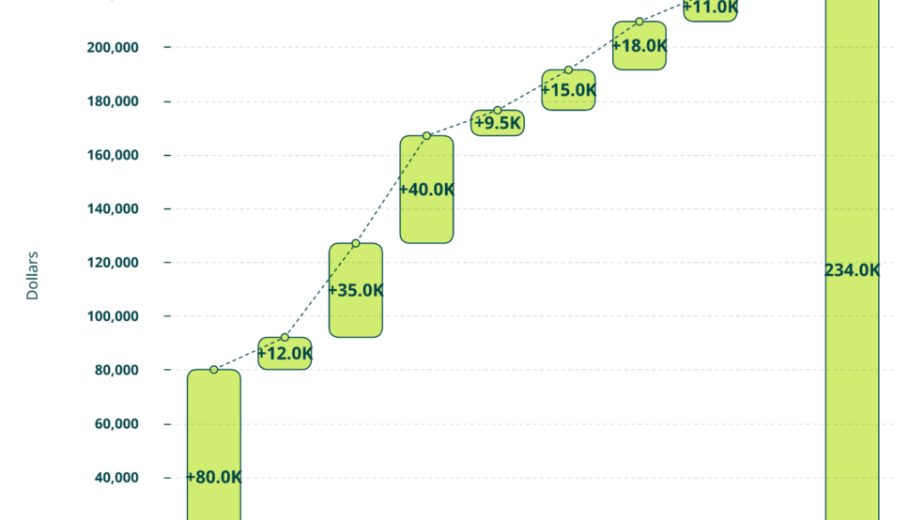
Q1. What Is AI-Powered Threat Intelligence, and Why Does the Old Definition No Longer Work?
AI is whatever machines have not done yet. I keep quoting that line in CISO meetings because it explains why most teams overspend on shiny AI threat intel modules while ignoring twelve features they already own inside M365 E5. So let me draw a line in the sand: AI-powered threat intelligence in 2026 is not a feed, a dashboard, or a smarter score. It is an agent that does work.
AI-powered threat intelligence is the use of agentic AI, large language models, and machine learning to autonomously collect, correlate, enrich, and act on threat data at machine speed. Unlike classical TI (Threat Intelligence), which delivers static IOC (Indicator of Compromise) lists for human analysts to chase, modern AI-TI continuously investigates alerts end to end, maps activity to MITRE ATT&CK, and surfaces only verdict-ready cases. That definition is consistent with the JUCS 2025 taxonomy paper “Advancing the Threat Intelligence with AI,” which maps AI techniques onto the TI lifecycle and concludes the highest-value stages are enrichment and correlation, not raw collection.
See how the UnderDefense Agentic AI SOC investigates, triages, and resolves real alerts.
Classical TI vs. AI-TI in one breath
Classical threat intelligence buys you a list. Someone has to read it, pivot through SIEM (Security Information and Event Management), check identity logs, and decide. AI-TI flips that. The platform reads the list, opens the case, pulls the user history, checks the OAuth (Open Authorization) grant, and writes back a verdict with reasoning. The analyst confirms or overrides. That is the shift, and the rest is detail.
If you want the longer view on how this changes day-to-day operations, our take on AI in cybersecurity walks through what works and what quietly breaks.
A concrete example from a 2 a.m. bridge call
A 4,000-person SaaS company we work with got an alert at 2:14 a.m.: suspicious OAuth grant to a new third-party app from a finance director’s account. Without an agent, that ticket would sit until 7 a.m., then take a Tier 2 analyst about 45 minutes to investigate. With agentic enrichment, the agent pulled the user’s last 30 logins, geo-IP, MFA (Multi-Factor Authentication) history, and the app’s reputation, and pinged the user on Slack: “Did you just grant ContractPilot access to your inbox?” The user said no. The grant was revoked in under two minutes. That is not a faster dashboard, but a different operating model.
Where AI-TI sits in your stack
AI-TI is an orchestration layer, not a replacement for your SIEM, EDR (Endpoint Detection and Response), or XDR (Extended Detection and Response). I tell every CISO the same thing: keep your data, keep your existing tools, and put the agent on top. If a vendor tells you that you have to rip out Splunk or Sentinel to get the AI benefit, that is a lock-in pitch, not a threat intel strategy. Our Agentic AI SOC platform was built around exactly this principle.
“The biggest win for me was getting actual control over our security alerts. Before the guys from UD stepped in, we were getting bombarded with alerts from all our security tools. Their team cleaned up our configurations and got the noise under control within the first week.”
— Verified User, Marketing and Advertising UnderDefense G2 – Verified Review
Q2. Why Has Human-Speed Threat Intelligence Already Lost the Race to Agentic Attackers?
Attackers have weaponized agentic AI to compress reconnaissance to exploitation from weeks to minutes, while internal SOCs (Security Operations Centers) still triage thousands of daily alerts by hand. Human-speed defense is structurally beaten. The fix is an agentic AI SOC that auto-enriches every alert, pivots across SIEM, EDR, identity, and SaaS logs, validates suspicious activity via ChatOps, and produces an auditable investigation trail, a fundamentally different operating tempo than monitoring-only MDR (Managed Detection and Response).
The situation, in numbers
The 2025 Verizon DBIR documented a 34 percent year-over-year rise in vulnerability exploitation as an initial access vector, and a continued spike in stolen-credential abuse. Mandiant M-Trends 2025 reported the global median dwell time dropped to 10 days, but ransomware dwell time is now measured in hours, not days. The MJCS 2026 systematic review on AI-powered cyber threats catalogued LLM-generated phishing, deepfake voice, and polymorphic malware as production attacker tooling, not lab curiosities.
Now look at the defender side. A 4,000-alert day is normal for a 5,000-person enterprise. A Tier 1 analyst, on a good day, closes maybe 80 alerts. The math does not work. That is not a hiring problem, but a physics problem. Our breakdown of SOC metrics like MTTD and MTTR shows exactly where the gap opens.
The complication
A prospect told me last quarter they had been tuning their legacy EDR for four years and were still not done. Four years. Meanwhile their adversaries are spinning up new infrastructure in an afternoon with an agentic recon tool. Human-speed defense against machine-speed offense is the operational debt that AI-powered automation has to retire.
The architectural answer
An agentic AI SOC does three things a legacy MDR service does not:
- It auto-enriches every alert with context from SIEM, EDR, identity, and SaaS in under two minutes.
- It “breaks the fourth wall” by pinging the affected user directly on Slack or Teams to validate the activity.
- It writes every reasoning step into an audit log a human can inspect.
That is the Iron Man Suit for a Tier 1 analyst. The human still owns the verdict, and the agent owns the grunt work.
Agentic AI SOC vs. legacy MDR
| Capability | UnderDefense Agentic AI SOC | Arctic Wolf | CrowdStrike Falcon Complete | ReliaQuest GreyMatter |
|---|---|---|---|---|
| Auto-enrichment across SIEM, EDR, identity | Yes, every alert | Partial, ticket-based | Endpoint-centric | Partial |
| Alert-to-Triage SLA | Under 2 minutes, 15-minute critical escalation | 30 to 60 minutes typical | Varies | Varies |
| ChatOps user verification | Native Slack and Teams | Limited | No | Limited |
| Transparent reasoning trail | Observable per alert | Black-box escalation | Limited visibility | Limited |
| Vendor lock-in | None, runs on your SIEM | Push to proprietary stack | Falcon-centric | Proprietary |
The complaints write themselves when an MDR is opaque or under-delivers:
“We received little value from ArcticWolf. The product offered little visibility when we were using it. Anything you want to look at or changes you need to make in the product must go through their engineering team.”
— Matt C., Manager, Cybersecurity Services Arctic Wolf – G2 Verified Review
“Log collectors show working, however when asked to provide logs for an investigation no logs could be provided. Analysts provide little context, and when asked for more information in the investigation nothing is ever provided or even communicated.”
— CISO, Manufacturing, $3B-$10B Arctic Wolf – Gartner Peer Insights Review
On the other side, here is what observable, fast, ChatOps-driven response feels like:
“The real game-changer is their seamless integration with Slack. We’ve tackled potential threats directly from our Slack channels, regardless of the hour. It’s like having a security command center right in our daily chat tool.”
— Alexander B., CEO, Small-Business UnderDefense G2 – Verified Review
Q3. How Does the AI-Powered Threat Intelligence Lifecycle Actually Work End-to-End?
The AI-TI lifecycle runs in five stages: collection (OSINT, dark web, telemetry, ISACs), normalization (STIX 2.1 / TAXII), enrichment (agentic correlation across SIEM, EDR, identity), scoring (MITRE ATT&CK + CISA KEV), and dissemination (ChatOps, board reports). Wrap that with the F3EAD loop, Find, Fix, Finish, Exploit, Analyze, Disseminate, so every incident generates fresh intel for the next cycle instead of dying inside a closed ticket. This staged view is consistent with the JUCS 2025 AI-TI taxonomy.
Stage 1: Collection
Pull from OSINT, dark-web forums, telemetry from your EDR and SIEM, ISAC (Information Sharing and Analysis Center) feeds, and commercial intel. AI helps here mostly with deduplication and signal extraction. The deliverable is a normalized event stream, not a bigger pile of logs.
Stage 2: Normalization
Translate everything to STIX 2.1 (Structured Threat Information eXpression) and ship it over TAXII (Trusted Automated Exchange of Intelligence Information). This is boring plumbing and the reason most TI programs fail quietly. If your feeds do not normalize, your agents have nothing to correlate. For a deeper read on the plumbing layer itself, see our walkthrough on understanding SIEM.
Stage 3: Enrichment
This is where agentic AI earns its money. The agent pivots across identity, endpoint, network, and SaaS logs and writes a case file in plain language. One client of ours had a major dark-web feed from Flashpoint that produced exactly zero value for months because nobody piped it into the SIEM. Lifecycle orchestration matters more than feed volume.
Stage 4: Scoring
Every enriched event gets mapped to a MITRE ATT&CK technique and cross-checked against the CISA KEV (Known Exploited Vulnerabilities) Catalog. That gives you a defensible priority order instead of CVSS guesswork.
Stage 5: Dissemination
Push verdicts where humans actually live: Slack, Teams, the ticketing system, and a clean monthly board report. If your intel dies inside a SIEM tab nobody opens, it is not intel
Wrap it with F3EAD
The U.S. Joint Pub 2-0 F3EAD model gives this lifecycle a feedback loop: Find, Fix, Finish, Exploit, Analyze, and Disseminate. The “Exploit” phase, in our context, means treating every closed incident as a new intel source. That is how a SOC compounds learning instead of resetting every week.
[Collection] → [Normalization] → [Enrichment] → [Scoring] → [Dissemination]
↑ ↓
└────────────── F3EAD feedback loop ─────────────────────────┘Q4. What Are the Highest-ROI Use Cases for AI-Powered Threat Intelligence in 2026?
The highest-ROI AI-TI use cases are: automated IOC and identity enrichment, NLP (Natural Language Processing)-driven dark-web and brand monitoring, phishing and BEC (Business Email Compromise) triage, CISA KEV-prioritized vulnerability scoring, proactive threat hunting, executive protection, insider and payroll-fraud correlation, and AI agent governance for Copilot, Claude, and Cursor in production. Each maps to a MITRE ATT&CK technique and a measurable outcome, minutes-to-triage, false-positive reduction, or dollars saved, not a feature checkbox.
I will rank these by the dollars or hours I have actually seen them return.
1. Automated IOC and identity enrichment
The agent enriches every alert with user history, geo-IP, device posture, and asset criticality. Maps to MITRE T1078 (Valid Accounts). Outcome: Alert-to-Triage time drops from 30 to 45 minutes per alert to under 2 minutes, with a 15-minute escalation SLA for critical incidents.
2. NLP-driven dark-web and brand monitoring
LLMs parse dark-web forum chatter and flag stolen credentials, ransomware extortion mentions, or executive name drops. Maps to T1589 (Gather Victim Identity Information). Outcome: detect credential leaks before they are weaponized.
3. Phishing and BEC triage
The agent parses the email, scores the sender, checks the URL, and writes a verdict. Maps to T1566 (Phishing). Outcome: 90 percent of phishing reports closed without a human reading them. Our guide on business email compromise covers the playbook end to end.
4. CISA KEV-prioritized vulnerability scoring
Cross-reference your CVE list with CISA’s Known Exploited Vulnerabilities Catalog to rank what attackers are actually exploiting today. Maps to T1190 (Exploit Public-Facing Application). Outcome: patch the 30 vulns that matter, not the 3,000 that do not.
5. Proactive threat hunting
The agent runs hypothesis-driven queries against your data at off-hours and writes a findings report. Maps to TA0043 (Reconnaissance). Outcome: per the SANS 2025 SOC Survey, mature hunt programs find threats 4x faster than reactive triage. If you are building one from scratch, our notes on building a SOC are a useful starting point.
6. Executive protection
Continuous monitoring of exec emails, phone numbers, and social handles across the dark web and impersonation sites. Maps to T1593 (Search Open Websites). Outcome: catch CEO impersonation before the wire transfer.
7. Insider and payroll-fraud correlation
This one surprised us. A customer’s MDR service paid for itself in three months by catching a $300,000 payroll-fraud scheme that a malware-only TI feed would have missed. The agent flagged an unusual change to bank-account details inside a finance SaaS, correlated it with a recent password reset from a non-corporate IP, and stopped the transfer. Maps to T1078.004 (Cloud Accounts). Outcome: direct, hard-dollar ROI.
8. AI agent governance for Copilot, Claude, and Cursor
This is the new domain. Autonomous coding agents are now reading source, writing pull requests, and calling production APIs. We monitor what those agents do, who approved them, and which data they touched through the WarRoom platform. Maps to T1059 (Command and Scripting Interpreter) and emerging MITRE ATLAS techniques for AI systems. Outcome: visibility into a layer most SOCs do not even watch yet.
“Their proactive threat hunting and rapid response have saved us from incidents that could have been incredibly costly.”
— Verified User in Program Development, Mid-Market UnderDefense G2 – Verified Review
“Now, not only do we get alerts, but we also get clear guidance on how to handle them. This has significantly reduced our response time. False positives have become a rarity, ensuring that our team’s focus remains on genuine threats.”
— Valeriia D., Marketing Specialist UnderDefense G2 – Verified Review
A fair counterpoint for vendors that promise hunting and under-deliver:
“Over the past few years, we’ve undergone several external penetration tests, and during these assessments, Red Canary was not able to identify the malicious activity while the tests were ongoing.”
— Verified User, Insurance, Enterprise Red Canary – G2 Verified Review
Q5. Which AI Threat Intelligence Platforms Should You Evaluate, and How Do They Compare?
The credible 2026 shortlist puts UnderDefense platform first for vendor-agnostic agentic AI SOC with transparent investigation, followed by Recorded Future and Mandiant for strategic intel depth, Microsoft Defender Threat Intelligence for E5-bundled coverage, CrowdStrike Falcon Intelligence for endpoint-tight integration, and ThreatConnect, Anomali, or Cyware for TIP (Threat Intelligence Platform) orchestration. The right choice depends less on feed volume than on whether the platform genuinely automates investigation or only forwards enriched alerts.
I have been telling buyers the same thing for two years: most “AI threat intelligence” demos are renamed products, not rebuilt outcomes. The disqualifier is simple. Ask the vendor to triage one of your own alerts end to end on a live call, with the agent’s reasoning visible the whole way. If they cannot, move on. Gartner’s 2024 Market Guide for Security Threat Intelligence Products and Services made the same point in vendor-neutral language: differentiation has shifted from data volume to automated analysis and integration depth. For a wider field view, our running list of MDR vendors to consider in 2025 sets the same bar.
How the credible platforms stack up
| Platform | Agentic depth | Transparency | Integration breadth | Pricing model | Best-fit scenario |
|---|---|---|---|---|---|
| ⭐ UnderDefense Agentic AI SOC | Agentic AI SOC, full case automation | Observable reasoning per alert | Vendor-agnostic, 250+ tools | Transparent, $11 to $15 per endpoint per month | 1,000 to 10,000 employee orgs keeping their SIEM |
| Recorded Future | Heavy ML enrichment, light agentic | Good strategic reporting | Broad integrations | Enterprise, opaque | Strategic intel and exec briefings |
| Mandiant Advantage | Frontline threat research, light agentic | Strong analyst reports | Google Cloud heavy | Enterprise, opaque | IR-driven intel and APT tracking |
| Microsoft Defender TI | Co-pilot enrichment | Native to Defender | Microsoft stack | Bundled in E5 | Microsoft-centric shops |
| CrowdStrike Falcon Intelligence | Endpoint-tight automation | Strong on endpoint | Falcon-centric | Premium, opaque | Falcon EDR customers |
| ThreatConnect | TIP orchestration, scripting | Workflow visibility | Broad TIP integrations | Module-based | Mature internal intel teams |
| Anomali | ML scoring on feeds | Decent | Wide | Tiered | Feed-heavy SOCs |
| Cyware | TIP plus SOAR-lite | Workflow visibility | Wide | Tiered | ISAC and sharing groups |
Scenario-based picks
✅ Mid-market to enterprise (1,000 to 10,000 employees) keeping Splunk or Sentinel: UnderDefense Agentic AI SOC.
✅ Pure strategic intel for board and exec teams: Recorded Future or Mandiant.
✅ Microsoft-only stack with E5: start with Defender TI, then add a vendor-agnostic agent on top.
❌ Not recommended: any platform that cannot show you the agent’s reasoning on your own alert during the demo. For honest, side-by-side comparisons of the major endpoint plays, see our CrowdStrike vs. SentinelOne breakdown.
What buyers say when the model breaks
“We received little value from ArcticWolf. The product offered little visibility when we were using it. Anything you want to look at or changes you need to make in the product must go through their engineering team.”
— Matt C., Manager, Cybersecurity Services Arctic Wolf – G2 Verified Review
“Lack of true remediation in the response, costing us significantly in resources and introducing risks in security.”
— VP of Technology, Services Arctic Wolf – Gartner Peer Insights Review
And the contrast from a vendor-agnostic, observable workflow:
“The platform itself is straightforward, it pulls in data from all our existing security tools, so we didn’t have to rip and replace anything. When they escalate something, they include the context we need to understand the issue quickly.”
— Verified User, Marketing and Advertising UnderDefense G2 – Verified Review
See an agentic SOC triage an alert end-to-end in under 2 minutes.
Most vendors will show you dashboards. We will show you the agent’s reasoning chain on one of your own alerts, observable, auditable, and mapped to MITRE ATT&CK.
Q6. How Do You Spot “AI Washing” Using a Maturity Model and Buyer Evaluation Rubric?
Use a 5-level AI-TI maturity model, Reactive feeds, ML-assisted triage, Co-pilot enrichment, Agentic investigation, and Autonomous response with human governance, to locate any vendor on a single axis. Pair it with a 7-item scoring rubric: observable reasoning, MITRE ATT&CK mapping, ChatOps verification, audit trail, vendor-agnostic integration, ingestion tuning, and a sub-2-minute Alert-to-Triage SLA (Service Level Agreement). Anything labeled “AI” that cannot demo 5 of 7 on your own data is AI-washing.
I have sat through more than 40 “AI SOC” demos in the last year. Two passed this rubric. Most failed at item one. So let me give you the exact questions I ask, the exact answers that disqualify a vendor, and a worked scoring example you can hand to a Tier 2 engineer. For more warning signs, our piece on AI SOC red flags covers the patterns I keep seeing.
The 5-level AI-TI maturity model
Most platforms live between Level 1 and Level 3. Honest read: no vendor should be operating at Level 5 in production without a documented human-in-the-loop.
| Level | Name | Litmus test on the demo |
|---|---|---|
| 1 | Reactive feeds | Static IOC (Indicator of Compromise) lists, manual lookup |
| 2 | ML-assisted triage | Risk scores on alerts, human decides every case |
| 3 | Co-pilot enrichment | LLM summarizes context, analyst still pivots and acts |
| 4 | Agentic investigation | Agent pivots across SIEM, EDR, and identity, writes a verdict |
| 5 | Autonomous response with governance | Agent acts on low-risk classes, humans review and govern |
The 30 percent ceiling that nobody puts on the slide
Internal testing across our environments suggests current LLMs return the correct verdict in roughly 30 percent of high-stakes security cases. That is why AI should collect context. Humans should decide. A measurable, biased model is safer than an “unbiased” one because you can correct what you can measure. If a vendor cannot show you their accuracy distribution by alert class, they cannot govern their own model. The deeper take is in does AI kill or save your SOC team.
The 7-item buyer rubric (score 0, 1, or 2 each)
Hand this to your engineer. Score every vendor on a 0 to 14 scale. Anything under 10 is AI-washing.
| # | Rubric item | What “2” looks like in the demo |
|---|---|---|
| 1 | ✅ Observable reasoning | Click any alert, see the agent’s full reasoning chain |
| 2 | ✅ MITRE ATT&CK mapping | Every detection auto-tagged with technique IDs |
| 3 | ✅ ChatOps verification | Live Slack or Teams ping to an end user during the demo |
| 4 | ✅ Audit trail | Exportable JSON of every agent action, with timestamps |
| 5 | ✅ Vendor-agnostic | Runs on your existing Splunk, Sentinel, or Chronicle |
| 6 | ✅ Ingestion tuning | Shows a 50 to 90 percent log volume cut with no detection loss |
| 7 | ⏰ Sub-2-minute SLA | Triages a real alert end-to-end during the demo |
A worked scoring example
Real scorecards from three demos I sat through last quarter (anonymized, normalized):
| Item | Vendor A (Falcon-tight EDR-MDR) | Vendor B (Legacy MDR rebrand) | Vendor C (Agentic AI SOC) |
|---|---|---|---|
| Observable reasoning | 1 | 0 | 2 |
| ATT&CK mapping | 2 | 1 | 2 |
| ChatOps verification | 0 | 0 | 2 |
| Audit trail | 1 | 0 | 2 |
| Vendor-agnostic | 0 | 1 | 2 |
| Ingestion tuning | 1 | 0 | 2 |
| Sub-2-minute SLA | 1 | 0 | 2 |
| Total | 6/14 | 2/14 | 14/14 |
Less theater, more throughput. Less black box, more blue team. If the demo cannot survive this scorecard on your own alert data, the badge says “AI” but the engine is still 2018.
Q7. How Does Threat Intelligence Automation Lower SIEM Costs and Produce Quantified ROI?
High-fidelity TI usually inflates SIEM bills because every new feed adds telemetry. Threat intelligence automation reverses that by applying ingestion tuning to cut log volume 50 to 90 percent, treating detections as version-controlled Python code shipped via CI/CD (Continuous Integration / Continuous Deployment), and routing only verdict-ready events to expensive storage. Pair that with IBM’s $4.88M average breach cost and SANS-documented analyst hours saved, and AI-TI funds itself within a single quarter.
Why classic TI raises SIEM cost instead of lowering it
Every new feed pushes more logs. More logs push more SIEM ingest. Splunk and Sentinel bills go up. CFOs blame security. I have watched this loop break three programs in the last year. The fix is upstream, not downstream. Our managed SIEM pricing guide walks through where the real money goes.
The two mechanisms that change the math
- Ingestion tuning. Drop noisy log sources, dedupe heartbeats, summarize verbose events, and ship only what your detections actually use. We typically cut volume 50 to 90 percent without losing fidelity on real detections.
- Detection-as-code. Write detections as Python or Sigma in a Git repo. Version them. Test them in CI. Deploy via pipeline. Treat them like software, because they are. The 4-year EDR tuning treadmill one prospect described to me was a direct symptom of having no version control on detections. The same pattern shows up in our notes on SOC automation.
90-day payback math, illustrated
The IBM 2024 Cost of a Data Breach Report put the global average cost at $4.88 million, and organizations using security AI and automation extensively saved an average of $2.22 million per breach versus those that did not. The SANS 2024 SOC Survey documented that mature automation programs cut alert handling time by 50 to 70 percent. For a worked CFO view, our 2026 cybersecurity budget piece pulls these levers together.
| Lever | Conservative impact | Notes |
|---|---|---|
| 💰 SIEM ingestion cut 50 to 90 percent | $100K to $1M per year on a typical $1M Splunk bill | Direct CFO line item |
| ⏰ Analyst hours saved | 20 to 40 hours per analyst per week | Reinvest into hunt and detection engineering |
| 💸 Breach cost avoidance | Up to $2.22M per breach | IBM 2024 data |
“UnderDefense Agentic AI SOC helped us save money on security by automating tasks and making things run smoother.”
— Julia K., Marketing Manager UnderDefense G2 – Verified Review
“Their proactive threat hunting and rapid response have saved us from incidents that could have been incredibly costly.”
— Verified User in Program Development UnderDefense G2 – Verified Review
Q8. How Do You Align AI-Powered Threat Intelligence with MITRE ATT&CK, NIST CSF 2.0, and SEC / NIS2 Reporting?
Modern AI-TI earns its keep by mapping every detection to a named adversary technique and a reportable control. Use MITRE ATT&CK as the operational vocabulary, the Lockheed Martin Kill Chain for strategy, and the Diamond Model for analyst methodology, the Adversary Intelligence Trifecta. Target the top of the Pyramid of Pain (TTPs (Tactics, Techniques, and Procedures), not hashes). Align outputs to NIST CSF 2.0 and produce evidence that satisfies SEC 8-K Item 1.05, EU NIS2, ISO 27001, SOC 2 Type II, and HIPAA without manual narration.
Operationalize with the Adversary Intelligence Trifecta
Three frameworks, three jobs. Lockheed Martin’s Kill Chain gives you strategy. MITRE ATT&CK v15 gives you the operational vocabulary every detection should map to. The Diamond Model gives analysts a method to track activity threads across adversary, capability, infrastructure, and victim. Pair this with the Pyramid of Pain. Aim your AI agents at the “Tough!” tier, TTPs, not hash values or IPs that rotate hourly. Our overview of the 2025 compliance roadmap ties these technical mappings back to audit reality.
Close the loop with F3EAD
Every incident should produce new intel for the next cycle. The F3EAD model (Find, Fix, Finish, Exploit, Analyze, Disseminate) from U.S. joint doctrine gives you the loop. In practice, the “Exploit” phase is where your closed tickets become rules, queries, and watchlists for next week. The same loop is the backbone of a tested IR plan template.
Map outputs to the reports your board reads
NIST CSF 2.0 added the Govern function in 2024, which is where most boards now expect AI-TI evidence to live. SEC Item 1.05 of Form 8-K requires public companies to disclose material cybersecurity incidents within four business days of determining materiality. EU NIS2 imposes a 24-hour early warning and 72-hour incident notification on essential and important entities. For sector-specific framing, see our EU Cyber Resilience Act readiness piece.
| Output from AI-TI | NIST CSF 2.0 | SEC 8-K Item 1.05 | EU NIS2 | ISO 27001 / SOC 2 / HIPAA |
|---|---|---|---|---|
| Auto-mapped MITRE ATT&CK detections | Detect.AE, Detect.CM | Material incident evidence | Article 23 reporting | A.5.25 incident assessment |
| Verdict-ready case files with reasoning | Respond.AN | Disclosure narrative | Incident handling proof | Audit evidence for IR |
| ChatOps user verification logs | Govern.OV, Detect.CM | Timeline reconstruction | Early warning timestamps | Access control evidence |
| Ingestion-tuned, version-controlled detections | Identify.IM, Protect.PS | Reasonable controls argument | Risk management measures | Change-management proof |
A blunt note on compliance theater
LLM-generated answers to security questionnaires are creating mutually assured compliance theater, where neither side is actually measuring posture. ⚠️ Do not let your AI-TI program become a narrative engine. Insist on measurable controls, signed evidence, and reproducible queries that any auditor can rerun.
Q9. What Does a Proven 30/60/90 Day AI Threat Intelligence Implementation Playbook Look Like?
A proven 90-day rollout has three phases. Days 1 to 30: inventory existing TI feeds and M365 E5 entitlements, audit OAuth (Open Authorization) consent logs for Shadow IT, and baseline alert volume. Days 31 to 60: deploy agentic enrichment on top of the existing SIEM, apply ingestion tuning, codify the top 20 detections, and enable ChatOps verification. Days 61 to 90: hit a sub-2-minute Alert-to-Triage SLA with 15-minute escalation for critical incidents, publish board-ready reports mapped to NIST CSF 2.0, and run a purple-team validation.
I keep this playbook on a single page because every CISO I send it to says the same thing: “I do not need a 60-slide deck, I need to know what we do on Monday.” So here it is. For the wider strategic picture, our MDR buyers guide sits next to this on my desk.
Days 1 to 30: Inventory and baseline
- Run an M365 E5 entitlement audit. Most enterprises already own 12 or more intelligence features they have never turned on. See our breakdown for MDR for Microsoft 365.
- Pull OAuth consent logs from Entra ID, and build a free Shadow IT inventory. CISA’s SCuBA guidance gives you the baseline queries.
- Inventory every TI feed you pay for, and confirm where each one lands in the SIEM.
- Baseline alert volume, dwell time, and analyst hours per week.
- Pick three noisy detections to retire, and three high-value detections to harden.
Expected outcome: a one-page reality check showing what you already own, what you do not use, and where your team spends its hours.
Common pitfall: skipping the OAuth audit. Almost every customer we onboard finds at least one risky third-party grant they did not know existed. Our writeup on external attack surface management covers the discovery patterns.
Days 31 to 60: Deploy agentic enrichment and detection as code
- Deploy an agentic enrichment layer on top of your existing SIEM (Splunk, Sentinel, or Chronicle), no rip-and-replace.
- Apply ingestion tuning to drop 50 to 90 percent of useless telemetry.
- Rewrite your top 20 detections as version-controlled Python or Sigma, shipped via CI/CD (Continuous Integration / Continuous Deployment).
- Enable ChatOps verification so the agent can ping users directly on Slack or Teams.
- Wire every enriched alert into a MITRE ATT&CK mapping.
Expected outcome: a Tier 1 analyst gets the Iron Man Suit. Routine cases close in under two minutes, with the agent doing the pivoting and the human owning the verdict. The SANS 2024 SOC Survey notes that mature automation programs cut alert handling time by 50 to 70 percent. The deeper read on this shift is in our SOC automation checklist.
Common pitfall: trying to codify 200 detections at once. Pick 20 that cover 80 percent of alert volume, and ship them first.
Days 61 to 90: SLA, governance, and purple team
- Lock a sub-2-minute Alert-to-Triage SLA (Service Level Agreement) for all auto-enriched cases, with 15-minute escalation for critical incidents. Our notes on SLAs in cybersecurity explain why those two numbers must stay distinct.
- Stand up a monthly board-ready report mapped to NIST CSF 2.0 functions.
- Run a purple-team exercise against the agentic workflow. Have your red team try to fool the enrichment logic. The 10,000-employee attack simulation is a useful template.
- Tune feedback into the F3EAD loop so closed incidents become next week’s detections.
- Set quarterly governance checkpoints with the CISO, CTO, and CFO.
Expected outcome: a measurable jump in MTTR (Mean Time to Respond), a documented ROI for the CFO, and a defensible board narrative aligned to CISA’s Zero Trust Maturity Model 2.0.
Common pitfall: declaring victory at day 90, and then walking away. The whole point of F3EAD is that you keep the loop running.
Get the 30/60/90 Playbook scoped to your stack, free.
Send us your current SIEM, EDR, and identity stack. We will return a tuned 90-day rollout, an ingestion-cost projection, and three detections rewritten as code, before you commit to anything.
Q10. What Are the New Risks of AI-Powered Threat Intelligence Itself, and How Do You Govern Them?
AI-powered threat intelligence introduces its own attack surface. Agents can be prompt-injected through email bodies, SaaS tickets, or log lines. Feeds can be poisoned by adversaries who know you ingest them. LLMs (Large Language Models) can hallucinate plausible-but-wrong IOCs (Indicators of Compromise) and CVEs. Banning tools like ChatGPT removes CISO visibility, and creates Shadow AI on personal devices. The governance fix is observable agent reasoning, signed feeds, human-in-the-loop on destructive actions, continuous red-teaming of the agents, and a tested kill switch.
Three failure modes I have seen this year
Three failure modes show up in almost every honest agentic pilot. I will name them, then tell you what we did about each.
1. ⚠️ Prompt injection through user-controlled content. A pen-tester on our team embedded a hidden instruction in a customer support ticket body. The agent enriching the ticket followed the instruction, and tried to query an internal asset DB. We caught it because the agent’s reasoning was observable. The OWASP Top 10 for LLM Applications 2025 lists prompt injection as risk number one, and the lab cases match what we see in production. The UnderDefense Agentic AI SOC platform is designed around exactly this observability requirement.
2. ⚠️ Poisoned threat feeds.
Free and even paid TI feeds can be tampered with. If your scoring trusts the feed blindly, the attacker can steer your detections away from their own infrastructure. We saw a real version of this when a public feed briefly carried bogus indicators that would have suppressed a real C2 (Command and Control) domain. The fix was signed feeds, and a quality-score gate before any feed influences detection logic. Our list of top threat detection tools walks through what to look for here.
3. ⚠️ Hallucinated IOCs and CVEs.
LLMs invent plausible IP addresses, hashes, and CVE numbers. Twice this year I have seen agents reference CVEs that do not exist. MITRE’s ATLAS knowledge base catalogues adversarial ML cases that make this risk concrete, not theoretical. The fix is to constrain agent outputs to validated sources (CISA KEV, NVD, your own asset DB), and to reject any IOC the agent cannot link to a primary record.
Why banning consumer AI tools backfires
I have not met a CISO yet who banned ChatGPT and got the result they wanted. Usage does not drop, but visibility does. Employees switch to phones, personal Gmail, or a free Claude tab on a home laptop. That is Shadow AI, and it is a bigger intel blind spot than the “risk” the ban was trying to close. Time is the currency of the cloud, and a ban only slows down defenders. Our take on MDR for AI covers this in more depth.
The pragmatic move: license a sanctioned LLM, log usage centrally, and write detections on the OAuth grants that show up when employees connect personal accounts to corporate SaaS. The same theme runs through our piece on conversational SOCs.
A governance checklist you can run on Monday
The NIST AI Risk Management Framework and its Generative AI Profile give you the structural bones. Add the operational layer below.
| Control | What “good” looks like in production |
|---|---|
| ✅ Observable reasoning | Every agent decision logged with inputs, tools called, and chain of thought |
| ✅ Signed and quality-scored feeds | TI feeds delivered over signed channels, with a gate on quality metrics |
| ✅ Human-in-the-loop on destructive actions | Isolate, disable, revoke, and wire-block require analyst sign-off |
| ✅ Quarterly red-team of the agent | Adversarial testing of the agent, not just your network |
| ✅ Measurable bias profile | Document where the model is wrong by alert class, then fix it |
| ✅ Tested kill switch | Documented procedure to take an agent out of production in under 60 seconds, drilled monthly |
| ✅ Output constraints | Reject any IOC, CVE, or asset reference the agent cannot link to a primary record |
A 60-second kill switch story
Last quarter, an early version of our enrichment agent started over-quarantining mailboxes after a feed update changed scoring weights. A junior analyst hit the kill switch (a documented Slack command tied to a feature flag) in 38 seconds. The agent went read-only. We rolled back the weights, ran a postmortem, and shipped a regression test. The point is not that the bug happened. The point is that we had a kill switch, drilled it, and it worked. If your vendor cannot show you the equivalent on their platform, you do not have governance, but hope. Our incident response practice drills exactly these moments.
What I’m Thinking About Next
The thing keeping me up is not whether agentic AI defenders will arrive in time. They will. The question is whether the governance keeps pace. I am watching two signals over the next 18 to 24 months. First, how many SOCs let agents take destructive actions (isolate, disable, revoke) without a human in the loop, and how that compares to incident counts. Second, whether the SEC and EU regulators start asking for AI agent audit trails in 8-K and NIS2 filings, the way they ask for log retention today. If you are sitting on either side of that question, I would genuinely like to compare notes. Reply, push back, or send me your worst alert from last week.
Before you commit to any vendor on this list, see how UnderDefense Agentic AI SOC resolves a real incident on your stack.
References
Research Papers
- Verizon. “2024 Data Breach Investigations Report” Verizon DBIR.
- SANS Institute. “2024 SANS SOC Survey” SANS Reading Room.
- IBM Security and Ponemon Institute. “Cost of a Data Breach Report 2024” IBM Reports.
Official Docs / Indian Statutes
- MITRE. “ATT&CK Framework v15” MITRE ATT&CK.
- MITRE. “ATLAS (Adversarial Threat Landscape for AI Systems)” MITRE ATLAS.
- NIST. “Cybersecurity Framework 2.0” Published: 2024. NIST CSF.
- NIST. “AI Risk Management Framework and Generative AI Profile (NIST AI 600-1)” NIST AI RMF.
- CISA. “Zero Trust Maturity Model 2.0” CISA Publications.
- CISA. “Secure Cloud Business Applications (SCuBA) Project” CISA SCuBA.
- U.S. Securities and Exchange Commission. “Form 8-K Item 1.05, Cybersecurity Incident Disclosure Rule” SEC Final Rules.
- European Union. “Directive (EU) 2022/2555 (NIS2)” EUR-Lex.
- Gartner. “Market Guide for Security Threat Intelligence Products and Services, 2024” Gartner Research.
- OWASP. “Top 10 for Large Language Model Applications, 2025” OWASP LLM Top 10.
- U.S. Joint Chiefs of Staff. “Joint Publication on F3EAD (Find, Fix, Finish, Exploit, Analyze, Disseminate)” Joint Doctrine Publications.
- Lockheed Martin. “Cyber Kill Chain Framework” Lockheed Martin Cyber.
Blogs
- UnderDefense. “MAXI Platform” UnderDefense Platform. [Secondary source]
- UnderDefense. “AI in Cybersecurity: How to Innovate While Keeping Data Safe” UnderDefense Blog. [Secondary source]
- UnderDefense. “Does AI Kill or Save Your SOC Team” UnderDefense Blog. [Secondary source]
- UnderDefense. “AI SOC Red Flags” UnderDefense Blog. [Secondary source]
- UnderDefense. “Top 6 Managed Detection and Response (MDR) Providers” UnderDefense Blog. [Secondary source]
- UnderDefense. “Managed SIEM Pricing Guide” UnderDefense Blog. [Secondary source]
- UnderDefense. “Ultimate Guide to Regulatory Compliance” UnderDefense Blog. [Secondary source]
- UnderDefense. “MDR Buyers Guide” UnderDefense MDR Buyers Guide. [Secondary source]
- UnderDefense. “CrowdStrike vs SentinelOne: Who Is Building the Better AI SOC Brain” UnderDefense Blog. [Secondary source]
- G2. “UnderDefense MAXI Verified Reviews” G2 Reviews. [Secondary source]
- G2. “Arctic Wolf Verified Reviews” G2 Reviews. [Secondary source]
- Gartner Peer Insights. “Arctic Wolf Managed Detection and Response Services Reviews” Gartner Peer Insights. [Secondary source]
1. What is AI-powered threat intelligence in 2026, and how is it different from classical threat intelligence?
We define AI-powered threat intelligence as the use of agentic AI, large language models, and machine learning to autonomously collect, correlate, enrich, and act on threat data at machine speed. Classical TI hands an analyst a static IOC (Indicator of Compromise) list and walks away. AI-TI flips that. The agent opens the case, pulls identity history, checks OAuth grants, maps activity to MITRE ATT&CK, and writes back a verdict with reasoning that a human can audit. The shift is operational, not cosmetic. In a 4,000-alert day, no human team can manually pivot through SIEM, EDR, and SaaS logs on every alert. Practical outcomes we measure:
-
Alert-to-Triage time drops from 30 to 45 minutes down to under 2 minutes.
-
15-minute escalation SLA on critical incidents.
-
Audit-grade reasoning logged per case.
Our take on the broader operational shift is in AI in cybersecurity. We treat AI as a force multiplier on the analyst, never as a replacement for the verdict.
2. How do we tell a real agentic AI SOC apart from an "AI-washed" legacy MDR?
We use a 7-item rubric on every demo: observable reasoning, MITRE ATT&CK auto-mapping, ChatOps user verification, exportable audit trail, vendor-agnostic integration, ingestion tuning, and a sub-2-minute Alert-to-Triage SLA. Any vendor that cannot score at least 10 of 14 on your own alert data is AI-washing. The single most useful disqualifier is observable reasoning. If the demo cannot show the agent’s full chain of thought on a real alert, the AI claim is brochure copy. We also pair the rubric with a 5-level maturity model:
-
Level 1 reactive feeds.
-
Level 2 ML-assisted triage.
-
Level 3 co-pilot enrichment.
-
Level 4 agentic investigation.
-
Level 5 autonomous response with human governance.
Most platforms live between Levels 1 and 3, even when they sell at Level 5. Our companion piece on AI SOC red flags walks through the patterns we keep seeing in opaque vendor demos.
3. How does AI-powered threat intelligence actually lower SIEM costs?
Most TI programs raise SIEM (Security Information and Event Management) bills because every new feed pushes more telemetry into expensive storage. We invert that with two levers.
-
Ingestion tuning: drop noisy log sources, dedupe heartbeats, and summarize verbose events. We typically cut log volume 50 to 90 percent without losing detection fidelity.
-
Detection-as-code: write detections as version-controlled Python or Sigma rules, test in CI, deploy via pipeline. That kills the 4-year EDR tuning treadmill we still see at most mid-market shops.
The IBM 2024 Cost of a Data Breach Report found that organizations using security AI and automation extensively saved an average of $2.22 million per breach. The SANS 2024 SOC Survey documented 50 to 70 percent cuts in alert handling time for mature programs. For a CFO-friendly view of the math, see our managed SIEM pricing guide.
4. Which AI threat intelligence platforms should we shortlist in 2026?
Our credible 2026 shortlist starts with Under Defence MAXI for vendor-agnostic agentic AI SOC, then Recorded Future and Mandiant Advantage for strategic intel depth, Microsoft Defender Threat Intelligence for E5-bundled coverage, CrowdStrike Falcon Intelligence for endpoint-tight integration, and ThreatConnect, Anomali, or Cyware for TIP orchestration. The decision rule is rarely feed volume. It is whether the platform genuinely automates investigation or only forwards enriched alerts to your inbox. Scenario picks we use in real buyer calls:
-
Mid-market or enterprise (1,000 to 10,000 employees) keeping Splunk or Sentinel: Under Defence MAXI.
-
Microsoft-only stack with E5: Defender TI plus a vendor-agnostic agent on top.
-
APT-driven intel work: Mandiant Advantage or Recorded Future.
Our wider field view sits in top managed detection and response providers.
5. How do we align AI-powered threat intelligence with NIST CSF 2.0, SEC 8-K, and EU NIS2?
We map every AI-TI output to a named adversary technique and a reportable control. The operational vocabulary is MITRE ATT&CK v15. The strategic frame is the Lockheed Martin Kill Chain. The analyst method is the Diamond Model. Together they form the Adversary Intelligence Trifecta. On the regulatory side, three deadlines matter:
-
NIST CSF 2.0 introduced the Govern function in 2024, where boards now expect AI-TI evidence.
-
SEC Item 1.05 of Form 8-K requires public companies to disclose material cyber incidents within four business days.
-
EU NIS2 imposes a 24-hour early warning and 72-hour incident notification on essential and important entities.
AI-TI earns its keep by producing auto-mapped detections, verdict-ready case files, ChatOps verification logs, and version-controlled detection code, all auditable. Our overview of the regulatory compliance roadmap ties technical mappings back to audit reality.
6. What does a proven 30/60/90 day AI threat intelligence rollout look like?
We run a three-phase playbook that any 1,000 to 10,000 employee enterprise can execute on its existing SIEM. Days 1 to 30, inventory and baseline:
-
M365 E5 entitlement audit to surface features you already own.
-
OAuth consent log pull for free Shadow IT discovery.
-
Baseline alert volume, dwell time, and analyst hours per week.
Days 31 to 60, deploy and codify:
-
Agentic enrichment layer on top of your existing SIEM, no rip-and-replace.
-
Ingestion tuning to cut log volume 50 to 90 percent.
-
Rewrite the top 20 detections as version-controlled code with CI/CD.
Days 61 to 90, SLA and governance:
-
Lock a sub-2-minute Alert-to-Triage SLA with a 15-minute critical escalation.
-
Publish monthly board reports mapped to NIST CSF 2.0.
-
Run a purple-team validation against the agent.
Our full MDR buyers guide walks through the same arc.
7. What are the new risks of AI-powered threat intelligence itself, and how do we govern them?
AI-TI introduces its own attack surface. Three failure modes show up in almost every honest pilot we run.
-
Prompt injection through user-controlled content (email bodies, support tickets, log lines).
-
Poisoned threat feeds that steer detections away from real adversary infrastructure.
-
Hallucinated IOCs and CVE numbers that look plausible but do not exist.
Banning consumer LLMs backfires. Usage does not drop, only visibility does, and users push corporate data to personal devices. Shadow AI then becomes a bigger blind spot than the original risk. Our governance baseline includes:
-
Observable reasoning on every agent decision.
-
Signed and quality-scored feeds.
-
Human-in-the-loop on destructive actions (isolate, disable, revoke).
-
Quarterly agent red-teaming and a measurable bias profile.
-
A 60-second kill switch, drilled monthly.
For the production-grade view of how we run this layer, see the MAXI platform.
8. How does an agentic AI SOC compare to a legacy MDR like Arctic Wolf or CrowdStrike Falcon Complete?
We see three architectural differences that matter operationally.
-
Auto-enrichment scope: an agentic AI SOC pivots across SIEM, EDR, identity, and SaaS on every alert. Endpoint-centric MDR sees only endpoints. Pure-play MDR sees only alerts.
-
User verification: agentic platforms ping affected users on Slack or Teams to validate suspicious activity. Legacy MDR escalates a ticket and waits.
-
Vendor lock-in: an agentic AI SOC runs on your existing Splunk, Sentinel, or Chronicle. Many legacy MDR contracts force a proprietary stack.
The outcome difference is speed plus context. We target a sub-2-minute Alert-to-Triage with 15-minute escalation on critical incidents. Most human-only managed SOCs operate at 30 to 60 minute triage windows. For honest, side-by-side competitive views, see our CrowdStrike vs SentinelOne breakdown.
The post What Is AI-Powered Threat Intelligence? Use Cases, Platforms, and a Proven Implementation Playbook appeared first on UnderDefense.