Q1. What is AI-powered incident response in 2026, and how is it different from SOAR, AI-washed MDR, and an AI SOC?
AI-powered incident response in 2026 is the use of agentic AI to autonomously detect, investigate, triage, and contain threats across the full NIST SP 800-61r3 lifecycle, with human Tier 3 and Tier 4 analysts as the final decision-makers. Unlike SOAR’s brittle if-then playbooks, or “AI-washed” MDR (Managed Detection and Response) that simply renames legacy detection, true agentic IR reasons over data, executes containment in under two minutes, and delivers up to 99% noise reduction.
A 2026 Microsoft Security paper, “Incident response for AI: same fire, different fuel,” frames the shift well. The fire is still containment, eradication, and recovery. The fuel is now agentic reasoning, prompt-injection blast radius, and machine-speed lateral movement.
See how the UnderDefense Agentic AI SOC investigates, triages, and resolves real alerts.
The AI-washing window is real, and most buyers are walking into it
Most traditional MDR vendors took their old SOAR (Security Orchestration, Automation, and Response) playbooks, slapped an “AI” sticker on the box, and re-shipped the same product. That is not agentic IR. That is a rebrand.
In our internal testing across 500+ customer environments, AI on its own gave the correct answer in roughly 30% of security cases. So we run AI as an assistant, not a decision-maker on our Agentic AI SOC platform. Tier 3 and Tier 4 humans still hold the kill switch.
“The biggest win for me was getting actual control over our security alerts. Before the guys from UD stepped in, we were getting bombarded with alerts from all our security tools. Their team cleaned up our configurations and got the noise under control within the first week.”
— Verified User in Marketing and Advertising, UnderDefense G2 Verified Review
A concrete example, so you can see the difference on Monday morning
Picture a credential-spray alert at 2 a.m. SOAR runs a fixed flowchart: enrich IP, check geolocation, escalate to a human. Total time to a useful triage report is often 30 to 60 minutes.
An agentic IR loop reasons. It pulls Okta logs, correlates with EDR (Endpoint Detection and Response) telemetry, queries the SIEM (Security Information and Event Management), and pings the user on Slack: “Did you just sign in from Lisbon?” Two minutes later, the analyst has a structured report and a one-click containment action through our MDR service. That is the difference between a black box and a blue team.
A 4-question litmus test to spot AI-washed vendors
Use this on your next vendor call. If they fail two or more, walk.
- Can you show me the agent reasoning trace for a real alert from last week, without redacting it?
- What is your alert-to-triage SLA, in minutes, with a public benchmark?
- Can a human Tier 3 analyst override or roll back any autonomous action?
- If the answer is “our model handles that,” and they cannot show the data behind the decision, that is a black box.
We rebuilt our own SOC around agentic AI before we sold it to anyone else. The hardened veterans on our team describe it as “putting on the Iron Man suit.” The suit augments the analyst. It does not replace the analyst. For more on this debate, see our take on does AI kill or save SOC.
Q2. Why have human-speed SOCs already lost the race against agentic-AI attackers?
Threat actors now run agentic reconnaissance, exploit chains, and social-engineering loops at machine speed, while defenders triaging at human pace average 30 to 60 minute alert delays. The 2024 Verizon DBIR found that 68% of breaches involved a non-malicious human element, and Mandiant’s M-Trends 2024 reports a global median dwell time of 10 days, with intrusion-to-encryption windows now collapsing toward minutes. If your SOC still moves at human speed on manual investigation, you have already lost the race.
Weaponized efficiency is the real story, not the LLM hype
Attackers are using AI to become faster, more automated, and less skilled. The barrier to entry for sophisticated attacks has collapsed. A junior operator with a Claude API key, a Cobalt Strike fork, and a list of stolen credentials can now do work that used to require a small team.
That changes the math for a CISO defending a 1,000 to 10,000 employee enterprise. You are no longer competing against one human attacker on the other side of the bridge call. You are competing against a script that runs at the speed of an API call, all night, for the cost of a coffee. Less theater, more throughput. Less black box, more blue team. Time is the currency of the cloud, and seconds are enough to steal valuable data.
The Zimbra memcache exploit, and why business hours are a gift to attackers
In 2022, attackers exploited a memcache flaw in the Zimbra email suite. The pattern we caught was specific: activity ran from 1 a.m. to 3 a.m. local time, when the customer’s in-house admins were asleep.
A 9-to-5 SOC, or even a hand-off MSSP (Managed Security Service Provider) without strong night coverage, would have lost a full eight-hour head start every single night. Our SOC service with 24/7 autonomous monitoring caught it because the agent never blinks, and the on-call human only got paged when containment needed authorization.
That is the operational reality. Manual SOCs are not bad at their jobs. They are just outnumbered, out-clocked, and out-automated. For deeper context, see our breakdown of continuous security monitoring.
Q3. How does agentic AI automate the full detection, triage, investigation, and containment lifecycle?
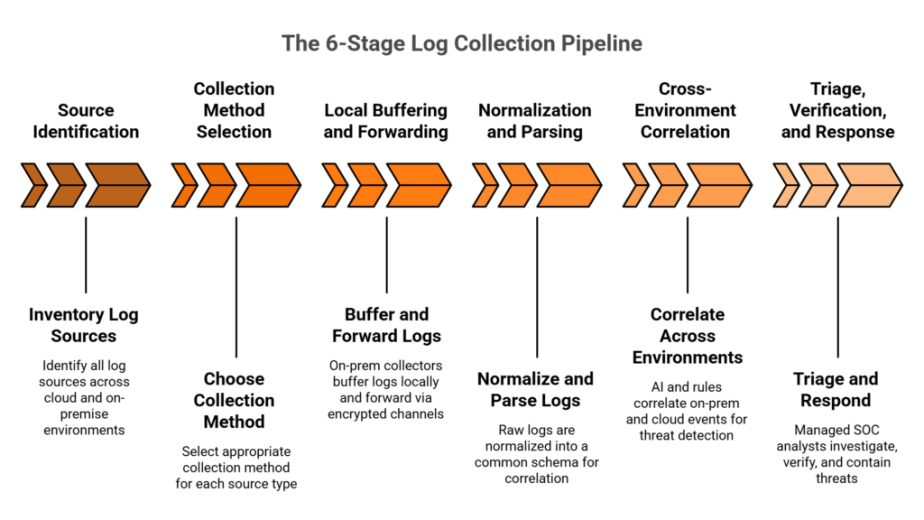
Agentic AI runs the mechanical work of incident response. It correlates SIEM, EDR, identity, and cloud telemetry, enriches alerts with threat intelligence, runs hypothesis-driven investigation, and triggers containment actions like credential wipes, password resets, and forced logouts in under two minutes. Unlike a deterministic SOAR flowchart, an agentic playbook is a reasoning loop that adapts when attackers deviate, while human Tier 3 and Tier 4 analysts authorize destructive actions.
Step 1, detection: behavior baselines beat signature lists
Detection in 2026 is mostly anomaly and behavior modeling, with signatures as a backstop. A 2025 peer-reviewed study by Mahesh et al. in Computer Fraud & Security found that decision-tree triage models, layered on top of SIEM and EDR feeds, cut false positives by 15 to 25% and analyst manual effort by up to 80%.
You do not need a black-box LLM (Large Language Model) to reach those numbers. Explainable models, version-controlled, are enough. For practical SIEM context, see our guide on understanding SIEM.
Step 2, triage versus investigation grunt work
Most vendors still confuse triage with investigation. Triage is “is this real, and how bad is it?” Investigation is the grunt work: querying the SIEM, pulling logs, correlating across identity, endpoint, and cloud, and writing the timeline.
Agentic AI is genuinely good at investigation grunt work. It can produce a structured timeline in seconds that a Tier 1 analyst would take 45 minutes to draft.
Step 3, containment with a 2-minute Alert-to-Triage SLA, and ChatOps for the human edge
Containment is where the 2-minute Alert-to-Triage SLA matters, with a 15-minute escalation for critical incidents. Credential wipe, forced logout, password reset, and host isolation should be one-click actions, with a clear audit trail.
We use ChatOps, which simply means we ping the user on Slack, Teams, or SMS to ask “Did you just run this command from a personal laptop?” That breaks the fourth wall, closes the context gap, and prevents a containment action that would lock out a real engineer at 3 a.m. The full reasoning trace is observable inside the WarRoom platform.
SOAR vs. agentic AI, side by side
| Dimension | SOAR Playbook | Agentic AI Playbook |
|---|---|---|
| Trigger | Rule match | Goal statement |
| Branching | Pre-defined if-then | Reasoning, adapts to findings |
| Adaptability | Breaks on attacker deviation | Re-plans on new evidence |
| Governance | Static version control | Detection-as-code, CI/CD, audit trail |
| Typical alert-to-triage | 30 to 60 minutes | Under 2 minutes |
| Best for | Compliance-mandated deterministic flows | Investigation, enrichment, low-risk containment |
The F3EAD model is the operational backbone
We run agentic IR on the F3EAD model: Find, Fix, Finish, Exploit, Analyze, and Disseminate. AI handles Find, Fix, and most of Exploit and Analyze. Humans own Finish (the destructive action) and Disseminate (the lessons-learned write-up that actually changes the next quarter’s detections).
Detection-logic-as-code, written in Python, version-controlled in Git, and shipped through a CI/CD pipeline, gives you the governance you need to run AI in production without losing your audit trail. If your current vendor cannot show you their detection rules in a git repo, that is a flag. For more, see our walkthrough of SOC automation.
Q4. How much can AI realistically cut MTTR, false positives, and SOC cost, and what does the math look like?
Peer-reviewed studies show AI-driven incident response reduces MTTR (Mean Time to Respond) by 40 to 60%, false positives by 15 to 25%, and manual analyst effort by up to 80%. Customers add hard-dollar ROI through ingestion tuning that cuts SIEM data volume by 50 to 90%. The most defensible numbers come from explainable CART (Classification and Regression Tree) and Random-Forest triage models, not black-box LLMs, meaning the ROI does not require betting the SOC on an unmeasurable agent.
What the primary research actually measured
A 2025 meta-analysis in IJIRSS reviewed 150 studies on AI in cybersecurity software. AI cut response times by up to 45% across the sample, and Random Forest plus SVM (Support Vector Machine) intrusion-detection models lifted accuracy by 17 to 35% over signature baselines.
The 2024 IBM Cost of a Data Breach report adds the dollar context. Organizations with extensive AI and automation in their SOC saved an average of $1.76 million per breach, and shaved 108 days off the detection-and-containment cycle. For a deeper view of the metrics that actually matter, see our breakdown of SOC metrics (MTTD, MTTR).
Here is the methodology table, so you can calibrate against your own SOC.
| Metric | Source | Result | What it measures |
|---|---|---|---|
| MTTR reduction | Mahesh et al. 2025 | 40 to 60% | Time from alert to containment |
| False positive reduction | Mahesh et al. 2025 | 15 to 25% | Volume of low-quality alerts |
| Analyst effort | Mahesh et al. 2025 | Up to 80% drop | Manual investigation hours |
| Breach cost savings | IBM 2024 | $1.76M per breach | Total incident cost |
| Detection IDS accuracy | IJIRSS 2025 | +17 to 35% | True-positive rate |
Ingestion economics: unlimited data is a liability, not a feature
Here is the contrarian take that surprises most CISOs. Unlimited SIEM ingestion, sold as a feature, is actually a liability. Without custom detection engineering on top, it is just dumpster diving in expensive logs.
We use ingestion tuning to cut SIEM data volume by 50 to 90% on customer environments. That is hard-dollar savings on Splunk, Sentinel, or Elastic licensing, and not a soft “efficiency gain.” 💰 Pair that with a 2-minute Alert-to-Triage SLA and the math compounds: less data, faster triage, fewer analyst hours, and smaller breach cost. For more on the licensing math, see our managed SIEM pricing guide.
“UnderDefense is surprisingly affordable considering the level of protection we get. Their proactive threat hunting and rapid response have saved us from incidents that could have been incredibly costly.”
— Verified User, Program Development UnderDefense G2 Verified Review
The $300k accidental discovery, and the 4-year tuning treadmill
One of our customers signed up for our MDR pricing tier and recovered the entire annual cost in 90 days. Not from a ransomware save, but from an accidental discovery. The agent flagged a payroll anomaly that turned out to be a $300k internal fraud scheme. A malware-focused detection stack would have missed it entirely, because it was not malware, it was abuse.
⚠️ Compare that to a prospect we spoke with last quarter, who admitted they had been tuning their EDR for four years and still were not “done.” That is the operational debt agentic IR removes, because the agent does the tuning loop on every alert, not once a quarter.
“Before MaxiMDR, we were slightly overwhelmed with alerts and often unsure of how to prioritize or respond to them. Now, not only do we get alerts, but we also get clear guidance on how to handle them. The most notable outcome has been the drastic reduction in response time to potential threats. Also, false positives have become a rarity.”
— Valeriia D., Marketing Specialist UnderDefense G2 Verified Review
For a deeper dive on how this looked in practice, see our case study where MDR reduced MTTR to 9 min for a US government organization.
Q5. How do you defend against adversarial AI, prompt injection, weaponized agents, and Shadow AI in production?
Adversarial-AI defense in 2026 means treating every AI agent as an identity. You sandbox agent execution, interrogate agent intent before sensitive actions, monitor what tools like Claude, Cursor, and Copilot actually do in production, and log every prompt and tool call for forensic replay. Banning ChatGPT does not stop usage. It only creates Shadow AI blind spots a CISO cannot see.
Microsoft’s 2026 paper on AI incident response, “Same fire, different fuel,” lays out the new harm categories cleanly. The fire (containment, eradication, and recovery) is familiar. The fuel is new: prompt injection, model exfiltration, training-data poisoning, and agent hijack. For broader context, see our take on AI in cybersecurity.
The contrarian truth: a measurable biased model is safer than an “unbiased” one
Most security buyers ask the wrong AI question. They ask, “is this model unbiased?” The right question is, “can I measure where this model is wrong, and can I adjust it?”
A measurable, biased model is governable. You can test it, log its mistakes, and tune it. An “unbiased” model is unmeasurable, which means it is unmanageable. AI is whatever machines have not done yet, so anything calling itself unbiased is usually just hiding its assumptions.
Patent-cited governance: interrogation and sandboxing as architecture
Two recent patents are worth your attention if you build agent governance. Eve Security filed an “Interrogation-as-a-Service” pattern in 2026 that requires agents to declare intent before executing sensitive actions. Samesurf was granted a 2025 patent for sandboxed isolation of agent execution in cloud-browser containers.
Together, these give you the two architectural primitives most production AI deployments are missing today. Interrogation answers, “what is this agent about to do, and why?” Sandboxing answers, “if it goes wrong, what is the blast radius?” Our MDR for AI applies the same primitives to govern agents in customer environments.
A practical AI-agent governance checklist for Monday morning
If you run Copilot, Cursor, or any custom agent in production, work through this list this week.
✅ Inventory every agent, including identity, scope, and toolset.
✅ Issue each agent its own service principal with least-privilege RBAC (Role-Based Access Control).
✅ Log every prompt, tool call, and response for at least 90 days.
✅ Sandbox agent execution where the action touches production data.
✅ Require human authorization for destructive actions (delete, transfer, and escalate).
❌ Do not block ChatGPT at the firewall and call it done. That just pushes usage to personal devices.
Shadow AI is the bigger CISO blind spot
Banning AI tools is a security risk, not a control. When you block ChatGPT, employees keep using it on personal phones. Now the prompts and the data leave your network without any logging.
In our work with mid-market and enterprise customers, the safer move is sanctioned AI with monitoring. Give people an enterprise tier with logging on. You get the productivity, you keep the visibility, and you stop paying for a Shadow AI economy you cannot see. A virtual CISO engagement is often the fastest way to get this policy written and approved.
What I think we will see in the next 18 to 24 months is that AI-agent governance becomes its own subdiscipline, somewhere between IAM (Identity and Access Management) and DLP (Data Loss Prevention). Treat agents like people with permissions, not like features. For early warning signs to watch for, see our piece on AI SOC red flags.
Q6. How do you migrate from SOAR to agentic AI in 90 days without breaking production SecOps?
Migrate in four governed phases. First, inventory your SOAR (Security Orchestration, Automation, and Response) playbooks and tag each as deterministic-keep, agentic-replace, or retire. Second, shadow-run agentic investigation alongside SOAR for 30 days. Third, cut over high-volume, low-risk use cases first (phishing triage and IOC enrichment). Fourth, keep deterministic playbooks for compliance-mandated flows. Decommission only after 60 days of clean parallel data, and explicit Tier 3 sign-off.
Phase 1, weeks 1 to 2: inventory and tag every playbook
Pull a list of every active SOAR playbook. For each one, answer three questions: what is the trigger, what is the success rate, and what is the failure mode?
✅ Deterministic-keep: compliance flows, ticket creation, and audit logging.
✅ Agentic-replace: phishing triage, IOC (Indicator of Compromise) enrichment, and identity-anomaly investigation.
❌ Retire: anything that has not run in six months, or that has under a 50% success rate.
For deeper context on this prep work, see our walkthrough of SOC automation.
Phase 2, weeks 3 to 6: shadow-run before you cut over
Run the agentic playbook in parallel with the SOAR playbook for 30 days. The agent does not take action. It just produces a recommendation, and an analyst compares it against what SOAR did.
You are looking for two things. First, agreement rate (does the agent reach the same conclusion as your seasoned Tier 2). Second, drift events (cases where the agent pulled in context SOAR missed). Agreement above 90%, with drift events that catch real signal, is your green light. The reasoning trace is observable inside the WarRoom platform.
Phase 3, weeks 7 to 10: cut over low-risk, high-volume work first
Start with phishing triage and IOC enrichment. These are high-volume, low-blast-radius, and easy to roll back. Do not start with anything that touches production identity or destructive containment.
⚠️ Define rollback criteria before you cut over. If the agent produces three false-positive containments in a week, you revert to SOAR for that use case automatically. No debate, and no bridge call. Our phishing playbook is a useful baseline for the first cutover.
Phase 4, weeks 11 to 13: govern, audit, and decommission
After 60 days of clean parallel data, you can decommission the replaced SOAR playbook. Keep deterministic playbooks for anything compliance-mandated, like SOC 2 evidence collection or ticket lifecycle.
Get explicit Tier 3 analyst sign-off before decommissioning. Document the agent’s reasoning trace, audit log, and rollback path in your IR runbook, so an auditor or a new hire can replay the decision six months later. For a structured starting point, use our IR plan template.
Risks to plan for, and the M365 E5 audit nobody runs
Three risks: agent drift (model behavior changes silently after a vendor update), audit gaps (you cannot replay an agent decision), and rollback failure (you cannot revert an autonomous containment). NIST SP 800-61r3 explicitly calls out evidence preservation across the IR lifecycle, so plan for these on day one.
One last move that costs nothing. Before you buy any new agentic tool, run an M365 E5 entitlement audit. Most enterprises already own automated investigation, attack-disruption, and identity-protection features inside their existing Microsoft license. AI is whatever machines have not done yet, and you are probably overpaying for a “new” feature you already shipped. Our MDR for Microsoft 365 team runs this audit as part of onboarding.
The 4-year EDR tuning treadmill is the cautionary tale. One prospect we spoke with had been tuning their EDR (Endpoint Detection and Response) for four years and still was not done. Agentic IR closes that loop because the agent retunes on every alert, not once a quarter.
Q7. How does AI-powered IR map to NIST SP 800-61r3, NIS2, GDPR Article 33, and SEC 8-K Item 1.05 disclosure?
NIST SP 800-61 Revision 3, published April 2025, replaces the legacy four-phase model with a community profile aligned to CSF 2.0, and embeds incident response into enterprise risk management. AI-powered IR must produce explainable, auditable evidence to satisfy NIS2’s 24-hour early warning, GDPR Article 33’s 72-hour notification, and the SEC’s 8-K Item 1.05 four-business-day materiality disclosure. Black-box agents that cannot show their work fail every one of these tests.
Mapping the lifecycle to AI capability and required evidence
This is the table I would put on a CISO’s wall. Each row is a phase, the AI capability that accelerates it, and the evidence artifact a regulator will ask for. For a broader regulatory view, see our compliance roadmap 2025.
| NIST 800-61r3 Phase | AI Capability | Required Evidence Artifact |
|---|---|---|
| Govern | Agent inventory, policy-as-code | Agent registry, RBAC matrix |
| Identify | Detection-as-code in Git, asset graph | Version history, asset map |
| Protect | Automated hardening, M365 E5 attack disruption | Config baseline, change log |
| Detect | Agentic correlation across SIEM, EDR, identity | Reasoning trace, alert timeline |
| Respond | Autonomous containment with human authorization | Action log, rollback record |
| Recover | Lessons-learned automation, detection updates | Updated runbook, board summary |
The disclosure clocks every CISO should know cold
⏰ NIS2 (EU Directive 2022/2555) requires an early warning to your CSIRT within 24 hours, an incident notification within 72 hours, and a final report within one month. GDPR Article 33 requires personal-data-breach notification to the supervisory authority within 72 hours. The SEC’s Final Rule 33-11216 requires 8-K Item 1.05 disclosure within four business days of materiality determination, not detection.
That distinction matters more than buyers think. The four-day clock starts when the materiality call is made. If your AI cannot timestamp when correlation completed and when the materiality threshold was crossed, your General Counsel cannot defend the timing. I have sat in two of those calls. The audit log is the difference between a clean filing and a second 8-K. Our compliance services team helps customers wire these timestamps into the IR runbook.
Why black-box AI fails the disclosure test
AI accelerates evidence collection because it timestamps every step. When the alert fired, when correlation completed, when containment executed, and who authorized destructive action.
A black-box vendor that cannot replay the agent’s reasoning fails this. ✅ UnderDefense Agentic AI SOC exposes every AI and human action in an audit log a regulator can read. ❌ Several legacy MDRs cannot replay closed cases for a CSIRT. Show, do not tell.
Sovereign deployment matters more than buyers think
For 1,000 to 10,000 employee enterprises operating across the EU, UK, US, or regulated verticals, telemetry jurisdiction is a board-level question. We deploy UnderDefense Agentic AI SOC on-premises, hybrid, or in a sovereign cloud through the UnderDefense Agentic AI SOC platform, so telemetry stays inside the customer’s jurisdiction. That posture matters less for a 200-person SaaS, but it matters a lot for a German hospital group, a UK financial services firm, or a US federal contractor. For a real example, see our German healthcare MDR case.
Q8. What AI-specific incident-response tabletop scenarios should you run in 2026?
Run four AI-specific tabletops this quarter. First, prompt-injection compromise of a customer-facing agent. Second, credential theft via a hijacked Copilot session. Third, data exfiltration through Shadow AI on personal devices. Fourth, deepfake-driven wire fraud against finance. Each scenario should test detection, containment SLA, evidence preservation, and 8-K materiality determination, not just communications.
Scenario 1: prompt injection on a customer-facing agent
Setup. Your retail support chatbot, built on a Claude API, receives a customer message containing a hidden instruction that tells the agent to dump prior order history and PII. Microsoft’s 2026 paper documents this exact pattern as a top-five harm category.
Success criteria.
✅ Detection within 5 minutes via prompt-log monitoring.
✅ Containment by isolating the agent’s API key and rotating credentials.
✅ Evidence: full prompt and tool-call log preserved for 90 days.
✅ Materiality determination logged with timestamp and decision-maker.
❌ Failure: the agent completes the dump before logs are reviewed.
Scenario 2: hijacked Copilot session and credential theft
Setup. A developer installs a malicious VS Code extension. The extension reads the local .env file through a Copilot tool call and exfiltrates AWS access keys at 2 AM. The Zimbra-style night-only pattern is exactly the behavior 24/7 autonomous monitoring catches inside our MDR service.
Success criteria.
✅ Detection via abnormal Copilot tool-call telemetry within 10 minutes.
✅ ChatOps validation: SOC pings the developer on Slack to confirm intent.
✅ Containment: AWS keys revoked, IAM (Identity and Access Management) roles audited, and MFA reset.
⚠️ Materiality call: was customer data accessed? If yes, the four-business-day SEC clock starts.
Scenario 3: Shadow AI on personal devices
Setup. A finance analyst pastes a draft earnings memo into ChatGPT on a personal phone, two weeks before the earnings call. SANS 2025 SOC Survey data shows Shadow AI is now the top unmonitored data-egress channel for mid-market and enterprise teams.
Success criteria.
✅ Detection via DLP (Data Loss Prevention) egress monitoring or sanctioned-AI usage analytics.
✅ Containment: legal-hold on the analyst’s account, and a vendor-side deletion request to OpenAI.
✅ Lessons learned: the team rolls out an enterprise AI tier with logging, not a ban.
❌ Failure: the team blocks ChatGPT at the firewall and creates a bigger blind spot.
Scenario 4: deepfake-driven wire fraud against finance
Setup. A finance manager receives a Teams call from a deepfaked CFO authorizing a $4M wire to a “new vendor.” The voice is convincing. The Verizon DBIR has tracked the rise of synthetic-media social engineering for two years running. For tabletop reference material on the human-channel side, see our piece on business email compromise.
Success criteria.
✅ Detection via the M&M Network test: any wire over a threshold requires a second channel verification.
✅ Containment: wire held, and the real CFO contacted on a known channel within 15 minutes.
✅ Evidence: call recording, Teams metadata, and approval workflow preserved.
❌ Failure: the wire goes out because the second-channel policy was never written.
Scoring rubric and the post-tabletop action checklist
Score each scenario across five axes: detection time, containment time, evidence completeness, communication clarity, and materiality call. Use a 1 to 5 scale per axis. A passing score is 20 of 25.
After every tabletop, do three things on the same week.
- Update the runbook with what broke, in plain language.
- File a NIST SP 800-61r3 lessons-learned record with the IR program owner.
- Add at least one detection-as-code rule to Git, version-controlled, with an owner.
If the materiality call is in scope, our incident response team can run the exercise alongside your IR program owner.
The ChatOps “fourth wall” technique
The most underused tabletop move is breaking the fourth wall. Instead of letting the SOC guess intent, ping the affected user directly on Slack or Teams in the middle of the exercise. Ask, “did you just run this command?” or “did you just authorize this wire?”
Working with hundreds of customer environments, what I have noticed is that ChatOps validation cuts investigation time in half on identity-driven incidents. It is the cheapest control most SOCs have not turned on yet. For more on the human-channel SOC pattern, see our piece on conversational SOCs.
Q9. What does a Governed Autonomous SOC maturity model look like, and where are you on it today?
A Governed Autonomous SOC operates at four tiers. Tier 1 is SOAR-assisted. Tier 2 is AI-copilot. Tier 3 is agentic-investigation. Tier 4 is bounded autonomy with human authorization on destructive actions. Each tier is defined by measurable controls (detection-as-code coverage, containment SLA, observability depth, and human sign-off rules), not by vendor marketing language.
The four tiers, in plain language
Think of this as a ladder, not a leap. You climb one rung at a time, and you keep humans in the loop until the controls earn the next rung. For the foundational metrics, see our breakdown of SOC metrics (MTTD, MTTR).
| Tier | Capability | Measurable Controls | Human Role |
|---|---|---|---|
| 1. SOAR-Assisted | Deterministic playbooks, ticket routing | Playbook coverage %, MTTR baseline | Tier 2 runs every action |
| 2. AI-Copilot | LLM summarizes alerts, drafts queries | Time-to-context, analyst hours saved | Tier 2 reviews every output |
| 3. Agentic Investigation | Agent pulls logs, correlates, recommends | Agreement rate vs. Tier 2, audit log completeness | Tier 3 approves containment |
| 4. Bounded Autonomy | Agent contains low-risk threats automatically | 2-minute Alert-to-Triage SLA, rollback success rate | Tier 3 authorizes destructive actions only |
A 10-question self-assessment for Monday morning
Score yourself yes or no. Eight or more “yes” answers means you are ready for the next tier. For a deeper architecture view, see our walkthrough of building a SOC.
- Are detection rules version-controlled in Git?
- Do you have a documented MTTR (Mean Time To Respond) baseline by alert type?
- Can you replay any agent decision from the last 90 days?
- Is every AI action logged with prompt, tool call, and output?
- Do you have a written rule for which actions require human sign-off?
- Can you roll back any autonomous containment in under 5 minutes?
- Do you measure agent agreement rate against Tier 2 analysts?
- Is your containment SLA written and tracked?
- Do you tune detections from agent feedback at least monthly?
- Can a new analyst replay a closed case end-to-end?
Where most teams get stuck
Working with hundreds of security teams, what I have noticed is that most stall between Tier 2 and Tier 3. The reason is rarely technology. It is governance.
Teams have a copilot that drafts queries, but no rule for when the agent can act on its own. Without that rule, every “agentic” claim is just a faster human in the loop. NIST CSF 2.0’s community profiles give you the scaffolding to write those rules in a way auditors will accept. SANS 2025 SOC Survey data also shows that mature SOCs measure agent decisions against analyst baselines before granting autonomy. Our SOC service writes and operates these governance rules with customer teams.
The Iron Man image, and why human-ally matters
The right mental model for Tier 4 is the Iron Man suit. The suit does not replace Tony. It augments him. When the suit acts on its own, it does so inside boundaries Tony set.
That is exactly how we built concierge response on the UnderDefense Agentic AI SOC platform. The agent does the investigation grunt work, and a Tier 3 analyst owns the destructive call. Less theater, more throughput. Less black box, more blue team. For more on this debate, see our piece on does AI kill or save SOC.
Q10. AI SOC vs. traditional MDR vs. legacy MSSP, which 7 providers actually deliver agentic IR in 2026?
Score every provider on six axes: genuine agentic investigation vs. alert parroting, autonomous containment SLA in minutes, observability into every AI and human action, deployment flexibility (cloud, on-prem, sovereign), ingestion economics, and transparent pricing. Only providers that score across all six belong on a 2026 shortlist. Most legacy MDRs and MSSPs fail on observability and containment speed.
The six-axis scorecard
| Axis | What to test | Pass bar |
|---|---|---|
| Agentic Investigation | Does the agent pull logs and correlate, or just summarize? | Structured report in seconds |
| Containment SLA | Time from alert to containment action | Under 2 minutes |
| Observability | Can you replay every AI and human action? | Full audit log, no black box |
| Deployment | Cloud, on-prem, hybrid, sovereign | At least three options |
| Ingestion Economics | SIEM volume reduction technique | 50% to 90% cut without losing fidelity |
| Pricing Transparency | Public per-endpoint pricing | Listed on the website |
The 7 providers, in order
- UnderDefense Agentic AI SOC. Strengths: vendor-agnostic across 250+ tools, 2-minute Alert-to-Triage SLA with 15-minute escalation for critical incidents, ChatOps user verification, on-prem and sovereign deployment, and transparent $11 to $15 per endpoint per month MDR pricing. Gaps: smaller brand than the giants, so still earning recognition in some procurement processes. Ideal buyer: 1,000 to 10,000 employee enterprise that wants to keep its existing SIEM and EDR.
- Arctic Wolf. Strengths: large partner network, and mature SMB playbooks. Gaps: limited remediation depth, and partner experience can be uneven.
“We received little value from ArcticWolf. The product offered little visibility… Anything you want to look at or changes you need to make in the product must go through their engineering team.”
— Matt C., Manager, Cybersecurity Services Arctic Wolf, G2 Verified Review
- CrowdStrike Falcon Complete. Strengths: best-in-class endpoint telemetry, and fast triage. Gaps: endpoint-focused, requires Falcon platform commitment, and weaker context outside the agent. Ideal buyer: organizations standardizing on Falcon and willing to accept the lock-in. For more, see our take on CrowdStrike vs SentinelOne.
- ReliaQuest GreyMatter. Strengths: SIEM-agnostic, and a decent automation library. Gaps: heavier services overlay than the agentic claim suggests.
- Expel. Strengths: clean UI, strong cloud and SaaS coverage, and responsive analysts. Gaps: limited environmental knowledge retention, and GovCloud gaps.
“Despite the capabilities of the technical platform… there is still a limit to the environmental, organizational knowledge inherent in the service. This leads to a fairly frequent need for engagement with our internal team.”
— Verified User, Computer Software Expel, G2 Verified Review
- Red Canary. Strengths: strong threat-hunting team, and solid CrowdStrike integration. Gaps: detection gaps in pen tests, and methodology rigidity.
“Over the past few years, we’ve undergone several external penetration tests, and during these assessments, Red Canary was not able to identify the malicious activity while the tests were ongoing.”
— Verified User, Insurance Enterprise Red Canary, G2 Verified Review
- Rapid7 MDR. Strengths: vulnerability management bundle, and broad portfolio. Gaps: limited integration depth, and support friction. For competitor context, see our piece on Rapid7 alternatives 2026.
“Rapid7 is a tool that does the job, however lacks in several aspects such as integrations, default rule set and asset association.”
— Himanshu K., IT Security Operations Engineer Rapid7, G2 Verified Review
The contrarian note: pay-to-play recommendation schemes
A few VC-backed startups quietly pay CISOs to put their name on shortlists. I have seen it. If a vendor leads with a paid recommendation rather than a live agent demo, walk away.
Show, do not tell. Ask any provider to run a live investigation against your own data, and watch the audit log fill in real time. That is the only honest scorecard that matters. For the broader buyer view, see our MDR buyers guide.
Why observability and deployment posture decide the winner
Most managed SOCs triage alerts behind a black box. ✅ UnderDefense exposes every AI and human action in the audit log. ❌ Several legacy MDRs cannot replay closed cases for a regulator. ✅ UnderDefense Agentic AI SOC deploys on-premises or sovereign for GDPR and NIS2 jurisdictions. ❌ Cloud-mandatory platforms move telemetry out of region by default.
For a deeper switching view, see our piece on why businesses switch providers.
Q11. What should a CISO and SOC team actually do on Monday morning to start AI-powered IR?
Spend week one auditing M365 E5 and existing SIEM and EDR entitlements, baselining current MTTR, and listing the top five alert types that consume analyst hours. Spend week two piloting agentic investigation on phishing and identity alerts, defining a 2-minute Alert-to-Triage SLA, and drafting a Tier 3 sign-off rule for destructive actions. Report results to the board with a single chart: MTTR before vs. after.
Week one: audit, baseline, and pick your five
Before you buy anything new, find what you already own. AI is whatever machines have not done yet, and most enterprises are sitting on unused automation inside Microsoft, their SIEM, and their EDR. For the licensing math, see our managed SIEM pricing guide.
✅ Run an M365 E5 entitlement audit. Turn on attack disruption and automated investigation if licensed.
✅ Pull MTTR by alert type from the last 90 days.
✅ Pick the top five alert types that eat analyst hours. Phishing and identity anomalies usually win.
✅ Agree on one observable success metric (MTTR cut, analyst hours saved, or false-positive reduction).
Week two: pilot, set the SLA, write the sign-off rule
Now you put the agent to work, but on a short leash. Pilot on phishing triage and identity alerts, both high-volume and low-blast-radius. Our incident response team can run the pilot in parallel with your in-house Tier 2.
✅ Set a 2-minute Alert-to-Triage SLA for the pilot scope.
✅ Run the agent in shadow mode for the first 5 days.
✅ Cut over after agreement rate with Tier 2 hits 90%.
✅ Write a one-page Tier 3 sign-off rule for destructive actions.
✅ Build a single board chart: MTTR before, MTTR after.
A conversational invitation, not a demo pitch
If you want a thinking partner on this, tell us what you are building through our contact us page. Send the alert types, the SIEM, and the constraints. We will tell you honestly which week-one wins are sitting in your existing stack, and where a pilot would actually pay back.
The Iron Man suit only works when the operator inside it is sharp. Agentic AI is the same. Bring your reality, your tradeoffs, and your skepticism. We will bring the playbooks, the audit logs, and the experience of running this across hundreds of environments. For a preview of the budget conversation, see our 2026 cybersecurity budget playbook.
Before you commit to any vendor on this list, see how UnderDefense Agentic AI SOC resolves a real incident on your stack.
What I’m Thinking About Next
The question I am sitting with right now is whether the SOC of 2027 still has a Tier 1 role at all, or whether Tier 1 quietly becomes the agent, and every human starts at what we call Tier 2 today. If that happens, the hiring market and the training pipeline both break, and we have not built the muscle to retrain analysts at that scale.
My current read is the safer path is bounded autonomy with human authorization, not full automation. I could be wrong. If you are running a SOC at 1,000 to 10,000 employees and you have a different read, I want to hear it. Drop me a note, or push back in the comments. The best ideas in this space come from operators, not analysts.
References
Research Papers
- Mahesh, S., et al. “Automated Incident Response Using AI-Based Decision Trees” Computer Fraud & Security, 2025.
- Patel, R., et al. “AI integration in cybersecurity software: Threat detection and response” International Journal of Innovative Research and Scientific Studies (IJIRSS), 2025.
- Microsoft Security Research. “Same Fire, Different Fuel: AI Incident Response in 2026” Microsoft, 2026.
- SANS Institute. “2025 SOC Survey” SANS, 2025.
Patents
- Eve Security. “Interrogation-as-a-Service for AI Agentic Risk Control.” Assignee: Eve Security. Filed: 2026.
- Samesurf. “Patented Security Boundaries for Agentic AI.” Assignee: Samesurf. Filed: 2025.
Official Docs / Indian Statutes
- NIST. “SP 800-61 Revision 3: Incident Response Recommendations and Considerations for Cybersecurity Risk Management” Published: April 2025.
- Microsoft Security. “Incident response for AI: same fire, different fuel” Published: April 2026.
- European Union. “Directive (EU) 2022/2555 on measures for a high common level of cybersecurity across the Union (NIS2)” Published: December 2022.
- European Union. “Regulation (EU) 2016/679, Article 33: Notification of a personal data breach to the supervisory authority (GDPR)” Published: 2016.
- US Securities and Exchange Commission. “Final Rule 33-11216: Cybersecurity Risk Management, Strategy, Governance, and Incident Disclosure (Item 1.05 of Form 8-K)” Published: July 2023.
- Gartner. “Market Guide for Managed Detection and Response Services” Published: 2025.
- Forrester. “The Forrester Wave: Managed Detection and Response, Q2 2025” Published: 2025.
Datasets
- Verizon. “2024 Data Breach Investigations Report (DBIR),” 2024.
- Mandiant. “M-Trends 2024,” 2024.
- IBM Security. “Cost of a Data Breach Report 2024,” 2024.
Blogs
- Vectra AI. “Incident response automation: from SOAR to agentic AI.” Published: April 2026. [Secondary source]
- UnderDefense. “Massive Infection through 0-day in the Zimbra Email Suite.” Published: 2022. [Secondary source]
- Verified User in Marketing and Advertising. “UnderDefense G2 Verified Review.” [Secondary source]
- Valeriia D. “UnderDefense G2 Verified Review.” [Secondary source]
- Verified User, Program Development. “UnderDefense G2 Verified Review.” [Secondary source]
- Matt C. “Arctic Wolf G2 Review.” [Secondary source]
- Verified User, Computer Software. “Expel G2 Review.” [Secondary source]
- Verified User, Insurance Enterprise. “Red Canary G2 Review.” [Secondary source]
- Himanshu K. “Rapid7 G2 Review.” [Secondary source]
1. What is AI-powered incident response in 2026, and how is it different from SOAR or AI-washed MDR?
We define AI-powered incident response as the use of agentic AI to autonomously detect, investigate, triage, and contain threats across the full NIST SP 800-61r3 lifecycle, with human Tier 3 and Tier 4 analysts holding the final kill switch on destructive actions. Unlike SOAR’s brittle if-then playbooks, agentic IR reasons over data. It pulls Okta logs, correlates with EDR telemetry, queries the SIEM, and pings the user on Slack to confirm intent before acting. The result is a structured triage report in under two minutes and up to 99% noise reduction. Most “AI-washed” MDRs simply rebrand legacy SOAR with an AI sticker. We run AI as an assistant, not a decision-maker, because in our internal testing across 500+ environments, AI alone gave the correct answer in roughly 30% of cases. See our Agentic AI SOC platform for how the agent reasoning trace is exposed end-to-end for auditors and analysts.
2. How much can AI realistically cut MTTR, false positives, and SOC cost?
Peer-reviewed studies show AI-driven incident response reduces MTTR (Mean Time to Respond) by 40 to 60%, false positives by 15 to 25%, and manual analyst effort by up to 80%. The 2024 IBM Cost of a Data Breach report adds dollar context: organizations with extensive AI and automation in their SOC saved an average of $1.76 million per breach and shaved 108 days off the detection-and-containment cycle. We add hard-dollar ROI through ingestion tuning that cuts SIEM data volume by 50 to 90%. That is real savings on Splunk, Sentinel, or Elastic licensing, not a soft “efficiency gain.” Pair that with a 2-minute Alert-to-Triage SLA and 15-minute escalation for critical incidents, and the math compounds: less data, faster triage, fewer analyst hours, and smaller breach cost. For licensing math, see our managed SIEM pricing guide.
3. How does agentic AI automate the full detection, triage, investigation, and containment lifecycle?
Agentic AI runs the mechanical work of incident response. It correlates SIEM, EDR, identity, and cloud telemetry, enriches alerts with threat intelligence, runs hypothesis-driven investigation, and triggers containment actions like credential wipes, password resets, and forced logouts in under two minutes. We run agentic IR on the F3EAD model: Find, Fix, Finish, Exploit, Analyze, and Disseminate. AI handles Find, Fix, and most of Exploit and Analyze. Humans own Finish (the destructive action) and Disseminate (the lessons-learned write-up). Detection-logic-as-code, written in Python, version-controlled in Git, and shipped through a CI/CD pipeline, gives us the governance to run AI in production without losing the audit trail. For a deeper view, see our piece on SOC automation.
4. How do we defend against adversarial AI, prompt injection, and Shadow AI in production?
We treat every AI agent as an identity. We sandbox agent execution, interrogate agent intent before sensitive actions, monitor what tools like Claude, Cursor, and Copilot actually do in production, and log every prompt and tool call for forensic replay. Banning ChatGPT does not stop usage; it only creates Shadow AI blind spots a CISO cannot see. The safer move is sanctioned AI with logging on. Practical controls: inventory every agent with identity, scope, and toolset; issue each agent its own service principal with least-privilege RBAC; log prompts and tool calls for at least 90 days; sandbox where actions touch production data; and require human authorization for delete, transfer, or escalate operations. The contrarian truth is that a measurable, biased model is safer than an “unbiased” one, because measurable means governable. See our MDR for AI for how we govern agents in customer environments.
5. How do we migrate from SOAR to agentic AI in 90 days without breaking production SecOps?
We migrate in four governed phases. In weeks 1 to 2, we inventory every SOAR playbook and tag each as deterministic-keep, agentic-replace, or retire. In weeks 3 to 6, we shadow-run agentic investigation alongside SOAR for 30 days. The agent only recommends; analysts compare against SOAR output, looking for >90% agreement and useful drift events. In weeks 7 to 10, we cut over high-volume, low-risk use cases first (phishing triage and IOC enrichment), with rollback criteria defined upfront. In weeks 11 to 13, after 60 days of clean parallel data, we decommission replaced playbooks with explicit Tier 3 sign-off and retain deterministic playbooks for compliance-mandated flows. Before buying anything new, we run an M365 E5 entitlement audit to surface automation customers already own. For a structured starting point, use our IR plan template.
6. How does AI-powered IR map to NIST SP 800-61r3, NIS2, GDPR Article 33, and SEC 8-K Item 1.05?
NIST SP 800-61 Revision 3, published April 2025, replaces the legacy four-phase model with a community profile aligned to CSF 2.0. AI-powered IR must produce explainable, auditable evidence to satisfy NIS2’s 24-hour early warning, GDPR Article 33’s 72-hour notification, and the SEC’s 8-K Item 1.05 four-business-day materiality disclosure. The clock distinction matters. The SEC four-day clock starts when the materiality call is made, not when detection happens. If your AI cannot timestamp when correlation completed and when the materiality threshold was crossed, your General Counsel cannot defend the timing. Black-box vendors that cannot replay agent reasoning fail every one of these tests. Sovereign deployment also matters, especially for EU and UK customers. See our compliance services for how we wire timestamps into the IR runbook.
7. What does a Governed Autonomous SOC maturity model look like?
A Governed Autonomous SOC operates at four tiers. Tier 1 is SOAR-assisted with deterministic playbooks. Tier 2 is AI-copilot, where an LLM summarizes alerts and drafts queries while analysts review every output. Tier 3 is agentic investigation, where the agent pulls logs, correlates, and recommends, and Tier 3 humans approve containment. Tier 4 is bounded autonomy, where the agent contains low-risk threats automatically with a 2-minute Alert-to-Triage SLA, and humans authorize destructive actions only. Each tier is defined by measurable controls: detection-as-code coverage, containment SLA, audit log completeness, and human sign-off rules. Most teams stall between Tier 2 and Tier 3, and the reason is rarely technology; it is governance. Without a written rule for when the agent can act on its own, every “agentic” claim is just a faster human in the loop. For the operating layer behind Tier 4, see our WarRoom platform.
8. What should a CISO and SOC team actually do on Monday morning to start AI-powered IR?
Spend week one auditing M365 E5 and existing SIEM and EDR entitlements, baselining current MTTR, and listing the top five alert types that consume analyst hours. Phishing and identity anomalies usually win. Agree on one observable success metric (MTTR cut, analyst hours saved, or false-positive reduction). Spend week two piloting agentic investigation on phishing and identity alerts, defining a 2-minute Alert-to-Triage SLA, and drafting a one-page Tier 3 sign-off rule for destructive actions. Run the agent in shadow mode for the first 5 days, and cut over only after agreement rate with Tier 2 hits 90%. Report results to the board with a single chart: MTTR before vs. after. For the budget framing conversation, see our 2026 cybersecurity budget playbook.
The post AI-Powered Incident Response: The Complete Guide to Automated Detection, Triage, and Containment in 2026 appeared first on UnderDefense.