Q1. What Is AI SOC Explainability, and Why Should You Demand It Before Signing Any Contract?
Every week, another vendor launches an “AI-powered SOC” product. Slick dashboards, bold claims about autonomous detection, promises of fewer alerts and faster response. But here’s the operational question almost nobody asks during procurement: can you show me exactly how your AI reached that conclusion? That question, and the ability to answer it, is what AI SOC explainability actually means. Let me be precise: AI SOC explainability is the ability of every automated investigation to expose its full reasoning chain, evidence sources, confidence scoring, and decision logic in a format your analysts can verify and your auditors can review. If a vendor can’t do that, you’re not buying intelligence. You’re buying a black box with a subscription fee.
⚠️ The “Verdict-Only” Problem
Most legacy MDR providers, including Arctic Wolf, CrowdStrike OverWatch, and ReliaQuest, operate as verdict-only platforms. They tell you what was flagged, but not why. Not how many data sources were queried. Not what hypotheses were tested. Not what evidence supports the conclusion. The result? Your analysts spend 45+ minutes re-investigating what the AI already “decided,” because they can’t see the reasoning and don’t trust the output. That’s not automation but re-work disguised as a service. And when an auditor asks why a specific alert was classified as a true positive, you’re stuck producing justification after the fact instead of pointing to a documented chain of reasoning.
The Shift: Detection Without Explanation Is Noise
Here’s where the industry needs a mindset reset. Detection without explanation is noise. Automation without accountability is risk. Explainability isn’t a checkbox feature you add in version 3.0 but an architectural requirement baked into how the system processes, reasons, and communicates. Think of it as the Trust-Explainability curve: too little explanation breeds analyst skepticism, slow adoption, and shadow re-investigation. The right level of explanation builds calibrated trust, where your team relies on the AI because they’ve verified how it works, not because marketing told them to.
✅ How We Built MAXI Around Glass-Box Investigation
This is why we built UnderDefense MAXI on what I call a “glass-box” investigation philosophy. Every AI-driven investigation shows:
- The full evidence chain across 250+ integrated tools, including SIEM, EDR, identity providers, cloud audit trails, and email gateways
- Hypothesis-driven reasoning with query counts and data-source breakdowns
- Confidence scores per conclusion, not a single opaque “risk score”
- Human analyst verification via ChatOps (Slack/Teams) before escalation
No proprietary magic. No hidden automation. No “trust me, it works.”
Show, Don’t Tell, in Practice
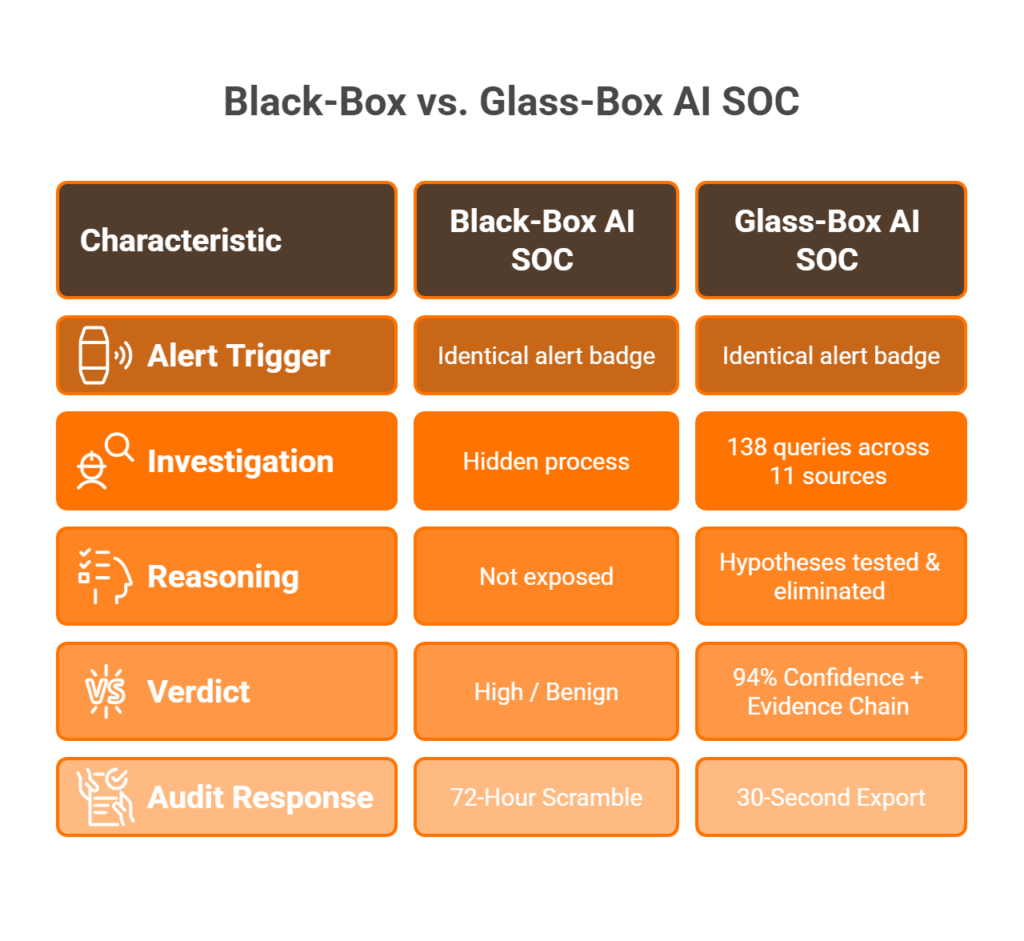
While a traditional MDR provider tells you “suspicious login detected, please investigate,” UnderDefense shows you the 138 queries it ran across 11 data sources, the evidence that confirmed the threat, the user verification via Slack, and the containment action taken, all documented with timestamps your auditor can review tomorrow morning. That’s the difference between a verdict and a defensible conclusion. If you’re evaluating AI SOC vendors right now, put this at the top of your contract checklist: demand a live investigation walkthrough with full reasoning exposed. If they can’t show it, they’re asking you to sign a contract for opacity, and in 2026, that’s a risk your organization shouldn’t accept.
Q2. What Should Investigation Reasoning Visibility Actually Look Like Inside an AI SOC?
Saying “our AI investigates threats” is easy. Showing how it investigates, step by step, query by query, hypothesis by hypothesis, is what separates a transparent platform from a marketing slide. If you’re evaluating AI SOC vendors and you don’t know exactly what investigation reasoning visibility looks like in practice, you’ll end up buying promises instead of proof.
The 6 Components of Genuine Investigation Reasoning
Based on years of building and operating SOCs, here are the six components every AI investigation should expose:
- Initial hypothesis generation from alert context: what did the AI think might be happening, and why?
- Data sources queried, including SIEM logs, EDR telemetry, identity provider records, cloud audit trails, and threat intelligence feeds
- Number and nature of queries executed: not just “we checked,” but how many queries, against which systems, and in what sequence
- Evidence collected and weighted per hypothesis: what data supported each theory, and how much weight did it carry?
- Alternative hypotheses tested and eliminated: did the AI consider that the alert could be benign? What ruled it out?
- Final conclusion with confidence score and supporting evidence chain, not a vague severity label but a documented, auditable determination
If your current vendor can only show you component #6 without #1 through #5, you’re looking at a verdict without reasoning. That’s the definition of a black box.
A Concrete Walkthrough: From Alert to Conclusion
Here’s what a real investigation looks like when reasoning is fully visible. A suspicious OAuth token grant triggers the investigation. The AI queries Azure AD logs, correlates with geographic anomaly data, checks threat intel feeds for known attacker infrastructure, queries the email gateway for phishing indicators, and verifies with the affected user via ChatOps. Conclusion: confirmed business email compromise, confidence 94%, 7 evidence artifacts linked, containment initiated within 12 minutes.
Now contrast that with a black-box output: “Suspicious activity detected. Severity: High. Please investigate.” Same alert, completely different operational outcome. One gives your team a verified, documented resolution. The other gives them a starting point for another 45 minutes of manual work.
✅ Vendor Evaluation Checklist: 5 Steps to Test Reasoning Visibility
Use this during your next vendor demo. Don’t accept screenshots from a marketing deck:
| Step | What to Ask | Red Flag If… |
|---|---|---|
| 1 | Show a real investigation trail from a live or recent environment | They show a canned demo with no timestamps |
| 2 | Count the data sources queried | Fewer than 3 sources or “we can’t disclose” |
| 3 | Verify alternative hypotheses were tested | Only the final conclusion is shown |
| 4 | Confirm confidence scoring is exposed | A single “risk score” with no breakdown |
| 5 | Check that reasoning is exportable for audit | No export or PDF-only without underlying data |
How MAXI Exposes the Full Investigation Graph
UnderDefense MAXI exposes the full investigation graph for every alert: query counts, data sources, evidence artifacts, hypothesis testing, and confidence scores, all visible to analysts in real time and exportable for auditors. Combined with concierge analyst verification via Slack or Teams, every conclusion comes with both machine reasoning and human validation. The reasoning isn’t hidden behind a proprietary layer. It’s there for your team to review, challenge, and learn from, because a system your analysts can’t verify is a system they won’t trust.
Q3. How Do Evidence Trails and Compliance Mapping Protect You During Audits and Breach Investigations?
Evidence trails in an AI SOC serve two masters simultaneously, and most organizations only think about one. First, compliance auditors need documented proof that your security decisions followed a defensible, repeatable process. Second, incident responders need to reconstruct what happened, when, and why, with enough granularity to contain damage and prevent recurrence. When your AI’s decision logic isn’t recorded, both chains break. The audit becomes a scramble, and the incident retrospective becomes guesswork.
⚠️ The Regulatory Landscape Is Closing In
This isn’t theoretical risk. The regulatory frameworks converging on AI accountability are specific, enforceable, and carry real penalties. The EU AI Act (Articles 13–14) mandates decision logging, human override capability, and bias monitoring for high-risk AI systems, with fines reaching up to 7% of global annual revenue for non-compliance. NIST AI RMF’s Govern and Map functions require organizations to document risk identification, measurement, and management processes across the full AI lifecycle. SOC 2 Trust Service Criteria CC7.2–CC7.4 demand evidence of monitoring, incident detection, and response procedures with documented controls. ISO 42001 Clause 6.1.2 requires documented AI management systems with performance monitoring and continual improvement evidence.
Cross-Framework Compliance Mapping Table
This table maps the explainability requirements across four major frameworks. Use it as a procurement checklist and audit preparation tool:
| Framework | Explainability Requirement | Evidence Trail Elements | Penalty for Non-Compliance |
|---|---|---|---|
| EU AI Act | Decision logging, human override capability, bias monitoring | Timestamped AI reasoning, override records, fairness metrics | Up to 7% global annual revenue |
| SOC 2 | Control evidence, monitoring documentation, incident response records | Alert logs, investigation trails, response timestamps, analyst actions | Audit failure, lost customer trust, contract termination |
| NIST AI RMF | Risk identification, measurement, and management documentation | Risk assessments, performance metrics, governance records | Federal contract ineligibility |
| ISO 42001 | AI management system documentation, performance monitoring, continual improvement | System documentation, performance baselines, improvement logs | Certification failure, market access loss |
The Gap Most Vendors Won’t Acknowledge
Here’s the uncomfortable truth: most AI SOC vendors mention “compliance support” in their sales decks but cannot produce evidence trails that satisfy auditors, because their AI reasoning is opaque. When the AI’s decision logic isn’t recorded, the entire evidence chain collapses. Auditors can’t verify that a true positive was correctly identified. They can’t confirm a false negative wasn’t negligently missed. And when the breach post-mortem reveals that your “AI-powered SOC” can’t explain its own decisions, your organization bears the liability, not the vendor hiding behind an NDA.
✅ How UnderDefense Turns Protection Into Audit Evidence
We built evidence generation into the detection workflow itself. It’s not a separate manual process you bolt on before audit season. UnderDefense MAXI generates auditor-ready evidence packages automatically. Every investigation includes timestamped reasoning chains, evidence artifacts, analyst verification records, and containment actions mapped to compliance framework requirements. Combined with forever-free compliance kits for SOC 2, HIPAA, and ISO 27001, audit evidence is produced as a natural byproduct of protection. When your auditor asks “show me the evidence chain for this incident,” you pull up a complete, timestamped record, not a retroactive summary assembled by an analyst working from memory two weeks after the fact. That’s the difference between compliance as a side effect of good security and compliance as a quarterly fire drill.
Q4. What Decision Metrics and Accuracy Benchmarks Should Your AI SOC Expose, and Why Do Most Vendors Dodge the Numbers?
Decision metrics aren’t one-size-fits-all, and any vendor who gives you a single dashboard for the SOC analyst and the CISO is either lazy or hiding something. Different stakeholders need different numbers at different levels of granularity. Here’s what a mature, transparent AI SOC should expose, broken down by role.
Role-Based Decision Metrics Matrix
| Stakeholder Tier | Metrics They Need | Why It Matters |
|---|---|---|
| SOC Analyst (L1-L2) | Confidence scores per alert, evidence artifact count, data sources queried, hypothesis tree, recommended action with reasoning | Enables faster triage and builds trust in AI outputs |
| SOC Manager | Aggregate accuracy rates, false positive/negative ratios, mean investigation depth, analyst override frequency | Tracks operational performance and identifies detection gaps |
| CISO / Security Director | MTTR trends, MITRE ATT&CK coverage %, risk reduction metrics, cost-per-investigation, board-ready dashboards | Communicates security ROI and strategic posture to leadership |
| Auditor / Compliance Officer | Decision logs with timestamps, evidence chain integrity, policy compliance mapping, human oversight records | Ensures regulatory defensibility and audit readiness |
❌ Why Vendors Dodge Accuracy Numbers
Accuracy is the most fundamental metric, yet most vendors avoid publishing benchmarks. They offer vague claims, such as “AI-powered detection” or “99% alert coverage,” without defining precision, recall, false positive rates, or investigation depth. Why? Because publishing invites scrutiny, comparison, and accountability. Arctic Wolf, CrowdStrike, and ReliaQuest publish MTTR SLAs but rarely detection accuracy or investigation depth metrics. This creates what I call “accuracy opacity”: you’re paying for a service whose effectiveness you can’t independently measure.
The Cloud Security Alliance’s AI Explainability Scorecard evaluates systems across five criteria: faithfulness, comprehensibility, consistency, accessibility, and optimization clarity. Vendors who expose only a single “risk score” without underlying metrics are asking you to trust without verifying, the opposite of what a security tool should demand.
✅ Where UnderDefense Stands, With Numbers
When we publish metrics, we mean tested, documented, and available for your review:
- 96% MITRE ATT&CK coverage, tested across techniques, not a marketing claim
- 0.5-hour MTTR for critical incidents across 500+ client environments
- Detection speed 2 days faster than CrowdStrike OverWatch in comparative testing
- 100% ransomware prevention record across 500+ clients
- Tiered dashboards calibrated to each stakeholder: analysts see full investigation graphs, managers track accuracy trends, CISOs get board-ready summaries, and auditors access exportable decision logs
“Not having to worry about ransomware, alert overload and reporting. Getting a clear view of my security posture, where the threats are coming from and how they are handled.”
— Arlin O., Enterprise UnderDefense – G2 Verified Review
“The product offered little visibility when we were using it… Anything you want to look at or changes you need to make in the product must go through their engineering team.”
— Matt C., Manager, Cybersecurity Services Arctic Wolf – G2 Verified Review
“Analysts provide little context, and when asked for more information in the investigation nothing is ever provided or even communicated.”
— CISO, Manufacturing Arctic Wolf – Gartner Peer Review
Any vendor that won’t publish or let you verify their accuracy numbers is asking you to buy a black box. In security, “trust me” isn’t a metric but a red flag. 💰 At $11–15 per endpoint per month, we make these numbers auditable because the economics only work when the results are real.
Q5. Does Your Vendor’s Reporting Pass the Auditor-Ready Test?
Audit documentation is where trust meets evidence. If your AI SOC vendor can’t produce reports that an auditor would accept on first review, you’re not buying transparency but a documentation burden that your team absorbs.
Here’s the test. Score your current vendor against these 8 criteria, honestly. No partial credit.
The 8-Point Auditor-Ready Checklist
☐ Timestamped reasoning chains. Does every investigation report include a full reasoning chain, not just a verdict but the logic path that reached it, with timestamps at each decision point?
☐ Evidence artifact attribution. Are all evidence artifacts (log entries, process trees, and network flows) linked with source attribution and integrity hashes so an auditor can verify nothing was altered post-investigation?
☐ Documented confidence scoring. Is the confidence scoring methodology documented and consistent? Can you explain to an auditor how the AI arrived at 87% confidence versus 62%?
☐ Export in auditor-required formats. Can reports be exported in formats auditors actually require, such as PDF, CSV, and SIEM-compatible JSON, without manual reformatting or screenshots?
☐ Compliance framework control mapping. Does reporting map conclusions to specific compliance controls (SOC 2 CC7.x, ISO 27001 A.16, HIPAA §164.308) automatically, or does your team manually annotate?
☐ Analyst override logging. Are human analyst interventions, overrides, and judgment calls logged with written justification? If an analyst reclassified a “Critical” to “Benign,” can you see why?
☐ False-positive/negative tracking. Does the report include false-positive and false-negative documentation for ongoing accuracy tracking, or do you discover accuracy gaps only after an incident?
☐ Full investigation reproducibility. Can the entire investigation be reconstructed from the report alone? If you handed it to a third-party forensics team, could they trace every step without calling your vendor?
What Your Score Tells You
| Score | Interpretation |
|---|---|
| ✅ 7–8 | Audit-ready. Your vendor treats transparency as architecture, not a feature request. Reports are evidence packages, not summaries. |
| ⚠️ 4–6 | Gaps will create friction. Expect auditors to request supplementary documentation. Your team fills the holes manually, adding hours per audit cycle. |
| ❌ 0–3 | Would not survive scrutiny. You carry the full documentation burden. Your AI SOC produces verdicts; your team produces the evidence trail. |
Where Most Vendors Fall Short
The typical failure pattern: vendors optimize their reporting for dashboards, not auditors. Dashboards look impressive, with clean charts, color-coded severity, and real-time counters. But an auditor doesn’t want a dashboard. They want a chain of custody. They want to see the specific queries run, the data sources consulted, the confidence calculation, and the human decision points.
Most AI SOC vendors score 3–5 on this checklist. They produce verdicts. They show alert counts. But the reasoning infrastructure, the part that makes those verdicts defensible, was never built. It wasn’t on the roadmap because speed metrics, not accountability metrics, drove their product decisions.
How UnderDefense MAXI Approaches Audit-Ready Reporting
We built UnderDefense MAXI‘s reporting architecture around a simple principle: every investigation should produce an evidence package, not a summary. That’s standard output, not a premium add-on or a professional services engagement.
Every MAXI investigation report includes:
- Full reasoning chains with timestamped decision points
- Evidence artifacts with source attribution and integrity verification
- Documented confidence scores with methodology explanation
- Export options in PDF, CSV, and SIEM-compatible formats
- Automatic compliance mapping to SOC 2, ISO 27001, and HIPAA controls
- Analyst verification records from ChatOps interactions
- Accuracy tracking for ongoing false-positive/negative documentation
The goal is straightforward: when an auditor asks “why was this classified as benign?”, the answer takes 30 seconds to pull, not 72 hours to reconstruct.
Next Step
Scored your current vendor below 6? Request a sample investigation report from UnderDefense and compare it against your last audit supplementation effort. The gap between audit-ready documentation and after-the-fact reconstruction is measurable in hours, cost, and risk.
Q6. Why Is an AI SOC That Can’t Explain Its Conclusions a Business Risk, Not Just a Technical Gap?
⏰ The 72-Hour Scramble
It’s Thursday afternoon when your GRC team forwards an urgent request: your cyber insurance carrier wants documentation of how your AI SOC classified a series of alerts as false positives during last month’s incident. Your vendor’s platform shows verdicts, Benign, Benign, Benign, but no reasoning, no evidence trail, and no analyst notes. You have 72 hours to reconstruct what the AI decided and why, or face a coverage dispute on a $2M claim.
This isn’t hypothetical but the operational reality for security leaders running AI SOC platforms that were built for speed, not accountability.
Why This Problem Exists
Most AI SOC vendors optimized for two metrics: alert volume processed and mean time to verdict. Both are speed metrics. Neither requires the AI to document its reasoning at the moment of decision.
The result is what I call decision debt: every unexplained verdict is a liability waiting to be called. The AI was trained to produce classifications, not reasoning chains. And nobody noticed the gap until an auditor, an insurer, or a regulator asked “show me why.”
💸 The Hidden Costs of Unexplained AI Decisions
The business impact extends far beyond technical inconvenience:
- Regulatory fines. The EU AI Act classifies AI-driven security decisions as high-risk. Penalties for non-compliant systems can reach up to 7% of global annual revenue, a material financial exposure for any mid-market company.
- Insurance disputes. Carriers increasingly require documentation of AI decision-making processes. An unexplained false-positive classification during an active incident can trigger coverage disputes, leaving your organization exposed on claims worth millions.
- Board liability. Directors and officers face personal accountability for AI governance failures. When the board asks “how are we governing our AI security decisions?”, “we trust the vendor” is not an acceptable answer.
- Vendor lock-in. Switching from an opaque AI SOC means losing all historical investigation context. Every unexplained verdict becomes an unresolvable gap in your security history; you can’t take reasoning trails with you if they never existed.
- Re-investigation burden. Teams spend 10–15 hours per week re-verifying AI decisions they can’t independently validate. That’s a full-time analyst equivalent spent on trust verification, not threat response.
How UnderDefense Eliminates Decision Debt
We built UnderDefense MAXI around a non-negotiable principle: every AI conclusion is documented at the moment it’s made, not reconstructed after the fact.
When your insurer asks why an alert was classified as benign, you export the investigation report showing the queries run, the evidence artifacts evaluated, the confidence score, and the analyst who verified via ChatOps. The answer takes 30 seconds, not 72 hours. No scramble. No reconstruction. No coverage dispute.
The Contrast
From 72-hour scrambles to 30-second exports: that’s the difference between an AI SOC that explains itself and one that asks you to trust it.
“Their team provided us with clear and detailed insights into security vulnerabilities, along with practical recommendations on how to fix them. This level of transparency made it easy for our team to take action and strengthen our security.”
— Arman N., CTO UnderDefense – G2 Verified Review
“The reports from their platform give us clear evidence of our security controls and incident response capabilities. When auditors or clients ask questions about our security posture, we can pull up exactly what they need to see.”
— Verified User in Marketing and Advertising UnderDefense – G2 Verified Review
“We love the monthly report, we gain valuable insights into security posture and incidents, and share them with the board of directors.”
— Yaroslava K., IT Project Manager UnderDefense – G2 Verified Review
Q7. How Do Explainable AI SOCs Compare to Black-Box Vendors on Key Evaluation Criteria?
The AI SOC market has split into two distinct categories: platforms that treat explainability as core architecture (glass-box), and those that bolt it on as an afterthought or skip it entirely (black-box). When you’re evaluating vendors, you’re not choosing between feature sets but between accountability and opacity.
⚠️ Acknowledging Black-Box Strengths
Let’s be fair. Black-box vendors, including Arctic Wolf, CrowdStrike OverWatch, and ReliaQuest, got a lot of things right. They process alerts at scale. They have large analyst teams. They’ve built brand recognition that makes procurement conversations easier. For organizations that need rapid triage with minimal internal overhead, these platforms deliver real value on the detection side.
But detection isn’t the whole picture.
❌ Where Black-Box Architectures Break Down
The limitations become visible when you move from “what happened?” to “why did the AI decide that?” and “can I prove it to a third party?”
- Verdict-only outputs. Alerts are classified, Critical, High, or Benign, but the investigation reasoning behind those classifications isn’t exposed to the customer. You see the conclusion; you don’t see the work.
- Unpublished accuracy benchmarks. Most black-box vendors don’t publish false-positive rates, detection accuracy, or MITRE ATT&CK coverage metrics in verifiable formats. You’re asked to trust the number on the marketing page.
- Audit trail gaps. When an auditor requests investigation documentation, the customer must reconstruct it from fragmented alert logs, because the vendor’s system never produced a unified evidence package.
- Re-investigation burden. Analysts spend significant time re-verifying AI decisions they can’t independently validate, effectively duplicating work the AI SOC should have documented.
“Analysts provide little context, and when asked for more information in the investigation nothing is ever provided or even communicated. Support incidents are not worked to completion and communication evaporates.”
— CISO, Manufacturing (3B–10B USD) Arctic Wolf – Gartner Review
“We received little value from Arctic Wolf. The product offered little visibility when we were using it… Anything you want to look at or changes you need to make in the product must go through their engineering team.”
— Matt C., Manager, Cybersecurity Services Arctic Wolf – G2 Verified Review
✅ The Glass-Box Alternative
Glass-box AI SOCs expose the full investigation: reasoning chains, evidence artifacts, confidence scoring, and human verification records. This isn’t about having “better AI” but about building accountability into the detection architecture from day one.
Evaluation Criteria: Glass-Box vs. Black-Box
| Evaluation Criterion | Black-Box Vendor (Typical) | Glass-Box: UnderDefense MAXI |
|---|---|---|
| Investigation Reasoning | Verdict only (Critical/Benign) | Full reasoning chain with timestamped decision points |
| Evidence Trail | Limited; fragmented across logs | Complete with source attribution and integrity hashes |
| Accuracy Benchmarks | Not publicly available | 96% MITRE ATT&CK coverage + documented MTTR |
| Auditor-Ready Reports | Manual reconstruction required | Auto-generated evidence packages |
| Human Verification | Escalates “please investigate” to customer | ChatOps direct verification via Slack/Teams/Email |
| Compliance Mapping | Separate product or manual | Built-in mapping to SOC 2, ISO 27001, and HIPAA |
| Pricing Transparency | “Contact sales” | Published $11–15/endpoint/month |
Who Should Choose What
Choose a black-box vendor if you primarily need fast alert triage and your team has the capacity (and willingness) to re-investigate AI decisions independently. These vendors work well for organizations with mature internal SOC teams who treat MDR as a first-pass filter.
Choose UnderDefense if every AI decision must be defensible, auditable, and explainable, if your regulatory environment, insurance requirements, or board governance mandate that you can prove why your security system reached the conclusions it did.
“The platform works really well with our other security tools, which makes things much simpler. And we really appreciate that we can customize the threat detection to focus on our specific needs.”
— Serhii B., CISO UnderDefense – G2 Verified Review
Q8. What 7 Questions Should You Ask Every AI SOC Vendor About Explainability Before You Buy?
The Evaluation Problem
Evaluating AI SOC vendors on explainability is harder than evaluating speed or coverage metrics, because every vendor claims transparency. Brochures say “full visibility.” Demo dashboards show clean interfaces. But claims and dashboards don’t reveal whether the AI can explain its conclusions under scrutiny.
Without the right questions, you discover the explainability gaps after signing, when an auditor asks for evidence, when an insurer requests documentation, or when your team can’t validate a critical decision at 2 AM.
The Wrong Way to Evaluate
Most security leaders evaluate AI SOC vendors on demo dashboards and marketing decks. They ask “Do you use AI?” instead of “Can you show me the reasoning behind this specific investigation?” Feature lists tell you what the system has. They don’t reveal whether it can explain what it did.
🔍 The 7 Questions
Ask every vendor these questions. Insist on live demonstrations, not slide-deck answers.
- “Show me the full investigation reasoning chain for a real alert, not a demo.” You want to see the actual queries run, the evidence evaluated, and the decision logic on a real investigation, not a curated example.
- “How many data sources does your AI query per investigation, and can I see the query log?” The answer reveals integration depth. A system querying 3 sources sees a fraction of what a system querying 40+ sources sees.
- “What is your published false-positive rate, and how is it measured?” If the answer is “proprietary” or “we don’t publish that,” you’re trusting accuracy claims you can’t verify.
- “Can I export a complete investigation report my auditor can independently verify?” Export capability isn’t enough. The report must be self-contained; an auditor should be able to trace every step without calling the vendor.
- “How do you document human analyst overrides of AI conclusions?” AI isn’t perfect. When a human analyst overrides a verdict, that decision must be logged with justification. If overrides aren’t tracked, there’s no accountability feedback loop.
- “What accuracy benchmarks do you publish, and how often are they updated?” Look for specific metrics: MITRE ATT&CK coverage percentage, MTTR for critical incidents, and false-positive rates, with publication dates showing ongoing validation.
- “If I switch providers, can I take my historical investigation data and reasoning trails?” This is the vendor lock-in test. If your investigation history can’t leave the platform, you’re not a customer but a captive.
How to Read the Answers
Any vendor that answers all 7 with specifics, live demonstrations, and exportable documentation treats explainability as architecture, built into the system, not bolted on after the fact.
Any vendor that deflects, generalizes, or responds with “that’s on our roadmap” is selling a black box with a transparency sticker. Move on.
✅ Where UnderDefense Stands
| Question | UnderDefense Response | Score |
|---|---|---|
| Full reasoning chain | Every investigation exposes complete logic path with timestamps | ✅ 2/2 |
| Data source query log | 250+ integrations with visible query logs per investigation | ✅ 2/2 |
| Published false-positive rate | Documented with ongoing measurement methodology | ✅ 2/2 |
| Exportable auditor-ready report | PDF, CSV, and SIEM-compatible self-contained evidence packages | ✅ 2/2 |
| Analyst override logging | Every human override logged with written justification | ✅ 2/2 |
| Published accuracy benchmarks | 96% MITRE ATT&CK coverage, 0.5-hour MTTR, and 30-day validation cycle | ✅ 2/2 |
| Full data portability | Historical investigation data and reasoning trails are yours | ✅ 2/2 |
| Total | 14/14 |
The pattern is straightforward: we built UnderDefense MAXI to answer these questions as standard functionality, because we’ve been on the other side of the table, asking vendors these same questions and watching them deflect.
Q9. Which AI SOC Platforms Actually Deliver on Explainability?
The AI SOC platforms that currently demonstrate meaningful explainability include UnderDefense MAXI, Prophet Security, and Dropzone AI, but architectures, transparency depth, and pricing models vary significantly across vendors.
AI SOC Has Moved Beyond Alert Triage
This market has evolved well past sorting alerts into priority buckets. The real differentiators now are investigation reasoning visibility (glass-box vs. black-box), evidence trail exportability, accuracy benchmark transparency, and whether the vendor actually responds to threats or just surfaces findings for your team to action. When Prophet Security published research showing their AI investigation engine ran 265 queries across 11 data sources to expose a cloud compromise, it set a tangible standard for what “showing your work” looks like in production. But investigation depth alone isn’t the full picture; you also need to ask: who acts on those findings once the AI finishes its analysis?
⚠️ Selection Criteria That Actually Matter
Here’s what separates platforms that deliver on explainability from those that just claim it:
- Investigation reasoning transparency — Does the platform show its full reasoning chain, or just a verdict with a confidence score?
- Evidence trail exportability — Can your auditors pull investigation artifacts in formats they actually accept (timestamped, integrity-hashed, and compliance-mapped)?
- Published accuracy benchmarks — Does the vendor share precision, recall, and false positive rates openly, or hide behind “contact sales”?
- Human analyst access — Do you get direct communication with experienced analysts, or ticket-based escalation queues?
- Pricing transparency — Is the cost published per-endpoint, or do you need three discovery calls to get a ballpark?
How Each Platform Approaches It Differently
Each vendor’s architecture shapes what “explainability” means in practice. UnderDefense delivers glass-box investigation graphs with a human verification layer; analysts contact affected users directly via Slack or Teams to confirm suspicious activity before escalating. Prophet Security focuses on agentic AI that autonomously runs deep, multi-source investigations with natural language reasoning summaries mapped to MITRE ATT&CK. Dropzone AI uses a pre-trained LLM system replicating Tier-1 analyst techniques to triage and investigate autonomously, including interviewing affected users through an interactive AI chatbot.
The right choice depends on your compliance requirements, audit cadence, and one very practical question: how much re-investigation burden can your team absorb? If you need a platform that detects, investigates, and responds with human organizational context, not just surfaces findings, the architecture needs to include both AI speed and dedicated analyst judgment.
This analysis is based on documented response times, G2 Spring 2025 rankings, published pricing data, and operational outcomes across 500+ MDR deployments.
Q10. How Does UnderDefense MAXI Deliver Explainability That Traditional MDR Providers Can’t?
UnderDefense MAXI is built on a glass-box investigation architecture where every AI-driven decision exposes its full reasoning chain, evidence artifacts, confidence scoring, and human verification layer. Explainability here isn’t a feature bolted on after the fact but the foundation the entire platform is built around.
How MAXI’s Explainability Stack Works
Most MDR platforms give you a verdict: “suspicious login detected, please investigate.” MAXI gives you a case file. Here’s what happens under the hood:
- Investigation Graph — A visual representation of every query, data source accessed, and evidence artifact collected. You see the path the AI took, not just where it ended up.
- Hypothesis Engine — MAXI tests multiple hypotheses simultaneously, showing which were eliminated and why. If the AI ruled out a legitimate admin action before confirming credential compromise, you see that reasoning chain.
- ChatOps Verification — Our analysts contact affected users directly via Slack, Microsoft Teams, email, or SMS to verify suspicious activity. Did Jane authorize that OAuth app grant at 2:41 AM? We ask her, persistently but politely, through the tools your organization already uses.
- Evidence Packager — Investigation artifacts compile automatically into auditor-ready formats with timestamps, integrity hashes, and compliance mapping for SOC 2, HIPAA, and ISO 27001.
- Accuracy Dashboard — Real-time precision, recall, false positive rates, and investigation depth metrics visible to analysts, leadership, and auditors, not locked behind vendor-controlled reports.
Why This Changes the Equation
The difference between MAXI and traditional MDR is receiving a case file versus receiving a verdict. With traditional providers, such as Arctic Wolf, ReliaQuest, or CrowdStrike Falcon Complete, you typically get an alert escalation that says “here’s what we found, please investigate.” Your team still does the heavy lifting of re-investigation, context gathering, and response execution.
With MAXI, analysts review confirmed incidents with full context. Auditors get export-ready evidence packages. Your board gets measurable risk reduction metrics, not vendor assurances that “everything is being monitored.”
✅ Earning Trust vs. Asking for It
Think of it as the difference between a doctor who says “you’re fine” and one who shows you the test results, explains the methodology, and documents everything in your medical record. One asks for trust; the other earns it.
We maintain a 100% ransomware prevention record across 500+ MDR clients and documented response times 2 days faster than CrowdStrike OverWatch, because explainable AI that humans can verify moves faster than opaque AI that analysts re-investigate from scratch.
⭐ What Practitioners Are Saying
“The biggest win for me was getting actual control over our security alerts. Their team cleaned up our configurations and got the noise under control within the first week. Now when we get an alert, we know it’s something worth looking into. When they escalate something, they include the context we need to understand the issue quickly.”
— Verified User in Marketing and Advertising UnderDefense – G2 Verified Review
“Not having to worry about ransomware, alert overload and reporting. Getting a clear view of my security posture, where the threats are coming from and how they are handled. They literally took care of all our problems.”
— Arlin O., Enterprise UnderDefense – G2 Verified Review
“They have an exceptionally talented team who is very engaged and provides extra care. If I had to pick a single word, I would call them proactive. They keep us informed, suggesting relevant and cost-effective security improvements and new use cases that enhance our defenses.”
— Yaroslava K., IT Project Manager UnderDefense – G2 Verified Review
Q11. AI SOC Explainability: Frequently Asked Questions
What is AI SOC explainability?
AI SOC explainability is the ability of an AI-driven security operations platform to show exactly how it reached each investigation conclusion, including the data sources queried, hypotheses tested, evidence collected, and reasoning applied. It transforms opaque “alert closed” verdicts into auditable, reproducible investigation chains that analysts, auditors, and executives can independently verify.
Why does AI SOC transparency matter for compliance?
Regulatory frameworks now explicitly require documented decision-making in automated systems. SOC 2 Type II audits demand evidence that security decisions follow consistent, reviewable processes. The EU AI Act (with high-risk AI obligations effective August 2026) requires organizations to ensure AI outputs are explainable and governed by defined policies. ISO 42001 Clause 6.1.3 mandates AI system impact assessments covering explainability, bias, and ethical risks. Without transparent AI SOC operations, audit trails hit dead ends.
What should an AI SOC audit trail include?
A complete audit trail should contain: the original alert with source metadata, all data sources queried during investigation, hypotheses tested and eliminated, evidence artifacts with timestamps and integrity hashes, the final determination with confidence scoring, any human verification steps (e.g., user confirmation via ChatOps), and compliance mapping to relevant frameworks like MITRE ATT&CK, SOC 2, or HIPAA.
How do you measure AI SOC accuracy?
Four metrics matter: precision (percentage of AI-flagged threats that are actual threats), recall (percentage of real threats the AI catches), false positive rate (noise generated per investigation cycle), and investigation depth (number of data sources and queries executed per alert). Demand published benchmarks, not vendor assurances. If a provider won’t share these numbers openly, treat that as a red flag.
What questions should I ask an AI SOC vendor about explainability?
Start with these three from the evaluation framework covered earlier:
- Can you show me the full investigation reasoning chain for a recent alert, not a summary but the actual evidence trail?
- Do you publish precision, recall, and false positive rates? How often are they updated?
- When your AI can’t explain a conclusion, what happens: does it still close the alert, or escalate to a human?
What is the difference between glass-box and black-box AI SOC?
A glass-box AI SOC exposes every investigative step, including queries, evidence, hypotheses, and reasoning, so analysts and auditors can follow the logic independently. A black-box AI SOC delivers verdicts without visible methodology. Under regulatory frameworks like the EU AI Act and ISO 42001, black-box approaches create audit gaps that become compliance liabilities.
Can AI SOC decisions be audited by external auditors?
Yes, if the platform generates exportable evidence trails with timestamps, integrity hashes, and compliance framework mapping. If the vendor’s “audit trail” is a PDF summary rather than a structured evidence package, your auditors will likely require supplemental documentation, which means your team is doing re-investigation work the AI was supposed to eliminate.
What happens when an AI SOC can’t explain its conclusions?
Three risks compound: ⚠️ regulatory (unexplainable automated decisions violate emerging AI governance mandates under the EU AI Act), insurance (cyber insurers increasingly require documented investigation processes for claims), and operational (analysts distrust opaque verdicts and re-investigate manually). Prophet Security’s research confirms this: when AI decisions can’t be explained, analysts second-guess closed alerts and reopen them, turning AI into a bottleneck instead of a force multiplier.
How does UnderDefense MAXI handle AI SOC explainability?
UnderDefense MAXI uses a glass-box investigation architecture with five layers: investigation graphs, a hypothesis engine, ChatOps user verification, automated evidence packaging, and real-time accuracy dashboards. Every AI-driven decision is observable, auditable, and verified by human analysts. See the full deep-dive in Q10 above.
How UnderDefense Simplifies This
UnderDefense builds explainability into the platform’s foundation rather than treating it as an add-on report. With transparent SLAs (2-minute alert-to-triage, 15-minute escalation for critical incidents), 96% MITRE ATT&CK coverage, and a 30-day onboarding that lets you validate these claims firsthand, the platform earns trust through observable outcomes.
1. What is AI SOC explainability, and why does it matter for security leaders?
AI SOC explainability is the ability of an AI-driven security operations platform to expose its full reasoning chain for every automated investigation, including the data sources queried, hypotheses tested, evidence collected, confidence scores assigned, and decision logic applied.
For security leaders, this matters because:
-
Analysts can’t trust what they can’t verify. Without visible reasoning, teams spend 45+ minutes re-investigating every AI verdict.
-
Auditors need documented evidence chains. SOC 2, EU AI Act, and ISO 42001 all require proof that automated decisions followed repeatable, defensible processes.
-
Insurers are tightening documentation requirements. Unexplained AI classifications can trigger coverage disputes on claims worth millions.
We built UnderDefense MAXI on glass-box investigation architecture specifically because detection without explanation is noise, and automation without accountability is risk. Every AI-driven investigation in MAXI shows its full evidence chain, hypothesis testing, and human verification layer.
2. How do you evaluate whether an AI SOC vendor's investigation reasoning is truly transparent?
We recommend testing vendor transparency with a structured five-step checklist during live demos, not marketing presentations:
-
Ask them to show a real investigation trail from a live or recent environment, with timestamps.
-
Count the data sources queried per investigation. Fewer than three is a red flag.
-
Verify that alternative hypotheses were tested and eliminated, not just the final conclusion shown.
-
Confirm that confidence scoring is exposed with methodology, not a single opaque “risk score.”
-
Check that investigation reasoning is exportable in auditor-accepted formats.
If a vendor can only show you what it concluded but not how it got there, you’re looking at a black box. We’ve documented the full 7-question evaluation framework in our AI SOC fact-check guide to help procurement teams run structured vendor assessments.
3. What is the difference between glass-box and black-box AI SOC platforms?
A glass-box AI SOC exposes every investigative step: queries executed, data sources consulted, hypotheses generated and eliminated, evidence artifacts weighted, and confidence scores calculated. Analysts and auditors can follow the logic independently and challenge conclusions.
A black-box AI SOC delivers verdicts (Critical, Benign, High) without showing the methodology behind them. You see the output but not the reasoning.
The operational difference is significant:
-
Glass-box: Investigation takes 12 minutes. Analyst reviews a documented case file. Auditor exports a complete evidence package.
-
Black-box: Analyst receives a verdict, spends 45+ minutes re-investigating. Auditor requests supplemental documentation your team assembles retroactively.
Under the EU AI Act and ISO 42001, black-box approaches create audit gaps that become compliance liabilities. We cover the full comparison, including a criteria-by-criteria evaluation table, in our guide on AI SOC promise vs. reality.
4. What compliance frameworks require AI SOC explainability and audit trails?
Four major frameworks converge on AI accountability requirements that directly impact AI SOC operations:
-
EU AI Act (Articles 13–14): Mandates decision logging, human override capability, and bias monitoring for high-risk AI systems. Fines can reach up to 7% of global annual revenue.
-
SOC 2 Trust Service Criteria (CC7.2–CC7.4): Demands evidence of monitoring, incident detection, and response procedures with documented controls.
-
NIST AI RMF: Requires organizations to document risk identification, measurement, and management processes across the full AI lifecycle.
-
ISO 42001 (Clause 6.1.2): Requires documented AI management systems with performance monitoring and continual improvement evidence.
If your AI SOC can’t produce timestamped reasoning chains, evidence artifacts, and compliance framework mapping automatically, your team carries the full documentation burden before every audit. We provide forever-free compliance kits for SOC 2, HIPAA, and ISO 27001 to help bridge this gap.
5. What accuracy metrics should an AI SOC platform publish openly?
A transparent AI SOC should publish four core metrics, broken down by stakeholder tier:
-
Precision: Percentage of AI-flagged threats that are actual threats (not false positives).
-
Recall: Percentage of real threats the AI successfully catches.
-
False positive rate: Noise generated per investigation cycle, which directly impacts analyst workload.
-
Investigation depth: Number of data sources and queries executed per alert, showing thoroughness.
Most vendors avoid publishing these numbers because transparency invites scrutiny and accountability. They offer vague claims like “AI-powered detection” or “99% alert coverage” without defining the underlying methodology.
We publish our metrics openly: 96% MITRE ATT&CK coverage, 0.5-hour MTTR for critical incidents, and 100% ransomware prevention across 500+ clients. Our SOC metrics and SLAs guide breaks down what each number means and how to benchmark your current provider.
6. What happens when an AI SOC can't explain its own conclusions?
Three risks compound immediately:
-
Regulatory exposure. Unexplainable automated decisions violate emerging AI governance mandates under the EU AI Act. Organizations face fines up to 7% of global annual revenue for non-compliant AI systems.
-
Insurance disputes. Cyber insurers increasingly require documented investigation processes for claims. An unexplained false-positive classification during an active incident can trigger coverage disputes on claims worth millions.
-
Operational decision debt. Every unexplained verdict is a liability waiting to be called. Analysts distrust opaque verdicts and re-investigate manually, spending 10–15 hours per week on trust verification instead of threat response.
We call this “decision debt,” where every undocumented AI conclusion accumulates risk for the organization. The AI was trained to produce classifications, not reasoning chains. And nobody notices the gap until an auditor, insurer, or regulator asks “show me why.” We built UnderDefense MAXI to eliminate decision debt by documenting every AI conclusion at the moment it’s made.
7. How does UnderDefense MAXI deliver explainability that traditional MDR providers can't?
UnderDefense MAXI is built on a glass-box investigation architecture with five layers:
-
Investigation Graph: Visual representation of every query, data source, and evidence artifact collected.
-
Hypothesis Engine: Tests multiple hypotheses simultaneously, showing which were eliminated and why.
-
ChatOps Verification: Our analysts contact affected users directly via Slack, Teams, email, or SMS to verify suspicious activity.
-
Evidence Packager: Compiles investigation artifacts automatically into auditor-ready formats with timestamps, integrity hashes, and compliance mapping.
-
Accuracy Dashboard: Real-time precision, recall, false positive rates, and investigation depth metrics visible to all stakeholders.
The difference is receiving a case file versus receiving a verdict. Traditional providers like Arctic Wolf or CrowdStrike OverWatch escalate “please investigate” to your team. MAXI delivers confirmed, documented, human-verified conclusions. At $11–15 per endpoint per month, we make these results auditable because the economics only work when outcomes are real.
8. Which AI SOC platforms deliver on explainability in 2026?
Three platforms currently demonstrate meaningful explainability, each with distinct architectures:
-
UnderDefense MAXI: Glass-box investigation graphs with human analyst verification via ChatOps. Vendor-agnostic across 250+ tools, published pricing, and automated compliance mapping.
-
Prophet Security: Agentic AI running deep, multi-source investigations with natural language reasoning summaries mapped to MITRE ATT&CK. Investigation-focused with no response layer.
-
Dropzone AI: Pre-trained LLM system replicating Tier-1 analyst techniques with autonomous triage and an interactive AI chatbot for user interviews.
The key differentiators are: who responds to threats (AI only, or AI + human analysts), whether evidence trails are audit-exportable, and whether pricing is published or hidden.
We maintain a comprehensive ranking with explainability scoring in our 12 Best SOC as a Service Providers guide, updated quarterly with G2 data and operational benchmarks.
The post AI SOC Explainability: Evidence Trails, Accuracy Benchmarks, and Decision Accountability appeared first on UnderDefense.