Q1. What Is an AI-Powered SOC, and Why Do Best Practices Matter in 2026?
The Fragmented Reality: Alerts Everywhere, Understanding Nowhere
Here’s the state of security operations in most organizations right now. You’re running CrowdStrike on endpoints, Splunk for log aggregation, Okta for identity, separate AWS and Azure consoles, and maybe Zscaler on the network edge. Each tool generates alerts. None of them talk to each other in a way that actually helps your analysts. The result? Alerts everywhere, understanding nowhere.
An AI-powered SOC is a security operations center where artificial intelligence handles machine-speed enrichment, triage, correlation, and, at advanced maturity levels, autonomous response actions, while human analysts retain decision authority over high-stakes and novel threats. The evolution looks like this:
- Traditional SOC (2010s): Manual, alert-driven, every ticket investigated from scratch
- Rule-Augmented SOC (mid-2010s): SIEM correlation rules, basic playbooks, partial automation
- AI-Assisted SOC (2020s): ML-powered anomaly detection, NLP enrichment, automated context collection
- AI-Driven / Autonomous SOC (2024–2026): Agentic AI, multi-system reasoning, graduated auto-containment with human oversight
Most teams are stuck somewhere between stage one and two. And the gap is widening: 70% of SOC teams admit critical alerts get ignored due to sheer volume.
Why the Status Quo Fails: Two Broken Models
The traditional approaches fail in two distinct ways.
❌ Traditional MDR providers, such as Arctic Wolf and ReliaQuest, act as opaque alert factories. They detect threats, generate tickets, and escalate them back to your team without actionable context, organizational understanding, or direct response capability.
❌ Legacy MSSPs provide monitoring without intelligence: checkbox coverage based on rigid playbooks that haven’t been updated since the last audit cycle.
Meanwhile, threat actors have weaponized agentic AI. Reconnaissance that maps your infrastructure in minutes. Adaptive malware that rewrites itself to evade defenses. Phishing campaigns generated at scale with perfect targeting. The traditional model, where human analysts respond to alerts at human speed, cannot match this pace.
“We received little value from ArcticWolf. The product offered little visibility… anything you want to look at or changes you need to make must go through their engineering team.”
— Matt C., Manager, Cybersecurity Services Arctic Wolf – G2 Verified Review
The Synthesis: Detection Without Response Is Noise
The critical architectural shift is this: detection without response is noise, and response without context is risk. In the AI era, the competitive advantage isn’t having security tools but having a system that can reason across them. The AI SOC + Human Ally model represents the new standard. AI handles the investigation grunt work: context collection, log enrichment, multi-system correlation, and user verification at scale. Experienced analysts provide judgment on novel threats, business context, and high-stakes containment decisions.
This is not about replacing analysts. It’s about augmenting them with machine-speed investigation so they focus on what humans do best.
How We Built UnderDefense MAXI for This Reality
We built UnderDefense MAXI purpose-built for this model. Agentic AI automates the mechanical steps analysts do manually: automated context collection, multi-system correlation, and structured investigation reports delivered in seconds.
- ✅ Vendor-agnostic integration across 250+ tools: it works with your existing CrowdStrike, Splunk, SentinelOne, Microsoft Defender, and Okta.
- ✅ ChatOps user verification via Slack, Teams, email, and SMS, because many behavioral alerts require asking the user “Did you do this?” and no other provider does this at scale.
- ✅ 2-minute alert-to-triage SLA and 15-minute escalation for critical incidents.
- Every investigative step is observable and auditable, with no black boxes.
- Detection Logic as Code: detections written in Python, versioned, unit-tested, and deployed via CI/CD.
⭐ The Proof Point
While traditional MDR tells you “suspicious login detected, please investigate,” we tell you who logged in, confirm with the user directly, and contain the threat before your team wakes up. This approach delivers documented response times 2 days faster than CrowdStrike OverWatch, zero ransomware cases across all MDR clients in 6 years, and 830% ROI over 3 years.
Q2. The 5-Level AI SOC Maturity Framework: Where Does Your Organization Stand?
Why Most Organizations Fail: Jumping From Level 1 to Level 5 Overnight
Most organizations attempt to leap from a manual SOC to fully autonomous AI in a single budget cycle, and fail. The failure mode is predictable: they buy a platform, flip the switch, watch analysts distrust the outputs, and end up with expensive shelfware that the team works around. A phased maturity framework gives security leaders a roadmap with measurable milestones, the kind of artifact that actually justifies budget allocation to CFOs and boards.
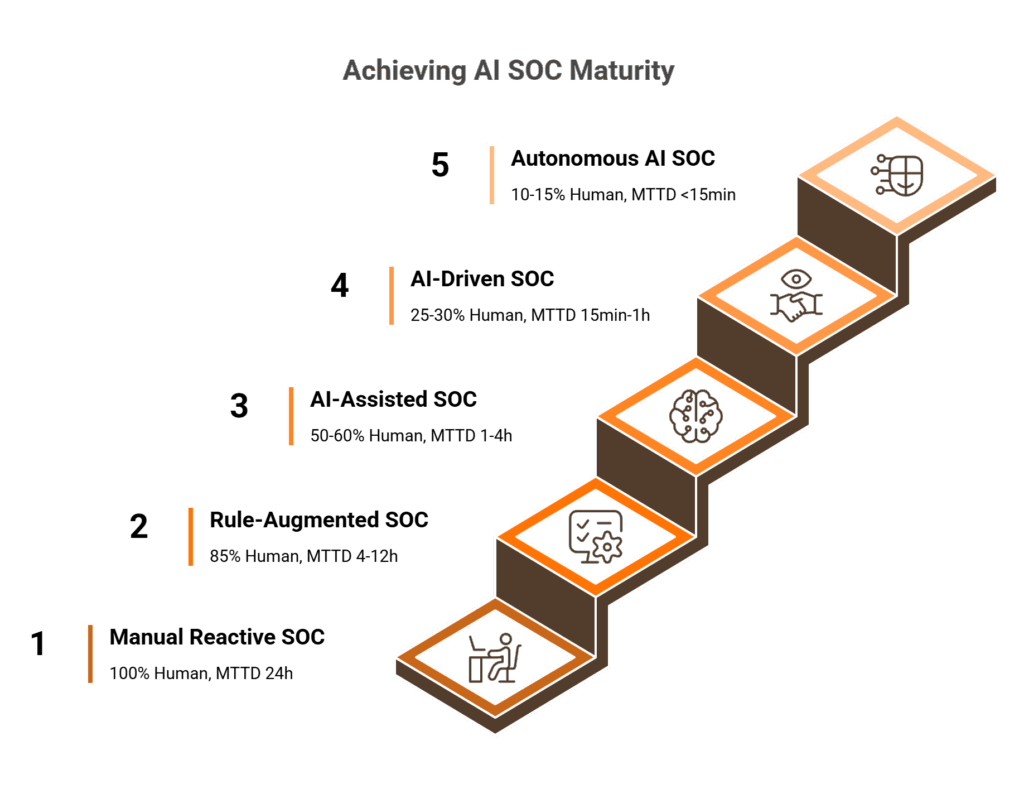
The 5-Level AI SOC Maturity Ladder
| Level | Name | Capabilities | Human Involvement |
|---|---|---|---|
| 1 | Manual / Reactive SOC | No AI; alert-driven triage; analysts investigate every alert manually | 100% |
| 2 | Rule-Augmented SOC | SIEM correlation rules; basic playbooks; partial automation of known-pattern alerts | 85% |
| 3 | AI-Assisted SOC | AI-driven enrichment; prioritized triage; ML anomaly detection; analysts decide on AI-surfaced recommendations | 50-60% |
| 4 | AI-Driven SOC | AI performs multi-system investigation and correlation; executes pre-approved containment actions; analysts handle exceptions and novel threats | 25-30% |
| 5 | Autonomous AI SOC with Human Oversight | AI manages routine incident lifecycle end-to-end; continuous MITRE gap analysis; humans focus on strategy, threat hunting, and novel attack patterns | 10-15% |
KPI Thresholds and Trust Gates Per Level
Each level has specific KPI thresholds that must be met before advancing. You don’t get to skip the gates.
| Level | MTTD | MTTR | Automation Rate | Trust Gate to Advance |
|---|---|---|---|---|
| 1 | >24h | >4h | <10% | Log completeness >90% |
| 2 | 4–12h | 1–4h | 10–30% | Data normalization verified; FP rate measured |
| 3 | 1–4h | 15min–1h | 30–60% | AI accuracy >90%; analyst override rate <15%; FP rate <10% |
| 4 | 15min–1h | 5–15min | 60–85% | Autonomous action success rate >98%; rollback time <2min |
| 5 | <15min | <5min (routine) | >85% | Zero critical false negatives over 30-day window; rollback success >99% |
⭐ Self-Assessment: Where Are You Today?
Answer honestly. This is how you figure out your current level and what it takes to advance:
- Level 1: “Do your analysts manually investigate every alert from scratch?”
- Level 2: “Do you have SIEM rules, but analysts still triage most alerts?”
- Level 3: “Does your AI enrich and prioritize, but analysts make all response decisions?”
- Level 4: “Does your AI execute containment for known patterns without analyst approval?”
- Level 5: “Does your AI manage the full detect-investigate-contain-remediate lifecycle for routine incidents?”
These levels map directly to NIST CSF Detect/Respond functions and MITRE ATT&CK technique coverage percentages. Level 3 requires at least 60% technique coverage, while Level 5 demands 90%+ with validated detection depth.
How UnderDefense Accelerates Maturity
UnderDefense MAXI is designed to accelerate organizations from Level 1 to Level 3 within 30 days of onboarding, with custom detection tuning across 250+ integrations, agentic AI that automates context collection and multi-system correlation, and phased trust calibration that advances toward Level 4–5 based on documented analyst confidence thresholds. The 30-day onboarding includes MITRE Caldera-based adversary simulation to validate coverage at your actual maturity level, not a claimed percentage but a proven one.
Q3. How Should Security Leaders Phase AI SOC Deployment, Calibrate Trust, and Define Human-AI Collaboration?
The 4-Phase Trust Calibration Model
Trust isn’t declared. It’s earned through measurable outcomes. Here’s the deployment model we’ve refined across hundreds of implementations:
| Phase | Name | Duration | What AI Does | Human Involvement |
|---|---|---|---|---|
| 1 | Shadow Mode | 2–4 weeks | AI runs parallel; outputs compared but not actioned | 100%, analysts validate every AI output |
| 2 | Advise Mode | 4–8 weeks | AI generates prioritized recommendations with full reasoning chains | 80%, analysts approve/reject every recommendation |
| 3 | Semi-Autonomous | 8–12 weeks | AI executes low-risk containment (block IPs, disable accounts, revoke tokens) with analyst notification | 40%, analysts review within 15-min window |
| 4 | Autonomous with Escalation | Ongoing | AI handles routine incident lifecycle; escalates novel/high-severity cases | 15%, analysts focus on strategy and edge cases |
Specific Trust Gates Between Phases
You don’t advance because a calendar says so. You advance because the numbers say it’s safe:
- Phase 1→2: Log completeness >95%; data normalization verified across all sources
- Phase 2→3: AI recommendation accuracy >90%; analyst override rate <15%; false positive rate <10%
- Phase 3→4: Autonomous action success rate >98%; rollback execution time <2 minutes; zero critical false negatives over 30-day window
The feedback loop in Phases 2–3 is non-negotiable. Every AI decision gets analyst scoring, whether agree, disagree, or modify, and that data continuously improves the model. This is the mechanism that earns trust.
Human-AI Collaboration Boundaries
Clear boundaries prevent confusion when it’s 2 AM and an incident is unfolding:
✅ AI handles: Enrichment, triage, alert prioritization, known-pattern containment, user verification at scale, and structured investigation reports
✅ Humans handle: Novel threat assessment, business-context judgment, high-severity containment (network segment isolation, production system changes), executive communication, and regulatory response
⚠️ Explainable AI (XAI) is non-negotiable. Analysts must see every step the AI took: what it queried, what logs it pulled, what enrichment it performed, and why it reached its conclusion. If analysts can’t audit AI decisions, trust collapses and override rates approach 100%, negating all ROI.
Analyst Training for the AI Era
Roles shift from “alert triage operator” to “AI-augmented threat hunter and decision-maker.” Training must cover:
- Interpreting AI investigation outputs and reasoning chains
- When to override AI recommendations and how to provide effective feedback
- Detection engineering skills, including writing rules, testing with adversary simulation
- Strategic threat hunting using AI-surfaced pattern analysis
This isn’t about making analysts redundant. It’s about elevating them from Tier 1 triage to Tier 3–4 strategic work.
“UnderDefense has changed our approach to cybersecurity. At first, we hired them for managed SIEM service, but after they demonstrated the value of MDR, our management was motivated to act on it.”
— Yaroslava K., IT Project Manager UnderDefense – G2 Verified Review
How We Deploy This at UnderDefense
Our 30-day onboarding follows this exact phased model, starting with custom detection tuning in shadow mode, progressing to AI-enriched triage with analyst validation, and scaling autonomous containment only after documented trust thresholds are met. Every step is observable and auditable. Our concierge Tier 3–4 analyst team handles escalations within the 15-minute critical incident SLA, meaning your internal team reviews confirmed incidents, not raw alerts.
Q4. What Are the Data Quality, Detection Engineering, and Feedback Loop Foundations Every AI SOC Requires?
Data Quality: The Non-Negotiable Prerequisite
AI models are only as good as the data they ingest. Every impressive AI SOC demo falls apart the moment you feed it incomplete, unnormalized, or stale telemetry. Here’s the 5-point data readiness checklist:
- Log completeness: Are all critical sources (endpoint, cloud, identity, network, SaaS, and email) feeding the detection layer? Common blind spots include SaaS application logs, identity provider events, and cloud control plane logs.
- Log normalization: Are events from different vendors mapped to a common schema (OCSF, ECS)? Without normalization, AI cannot correlate across sources.
- Enrichment pipelines: Are raw logs enriched with threat intelligence, geo-IP, asset criticality, and user context before AI processing?
- Data freshness: Is log ingestion latency <5 minutes? Stale data means stale detections.
- Data governance: Are retention policies, access controls, and privacy requirements (GDPR, data residency) documented and enforced?
Detection Engineering: The Highest-Leverage Activity
When AI handles 80%+ of routine triage, analysts gain time for detection engineering, and this is where the real value compounds. Detection-as-code means writing detection rules in flexible languages (Python, SIGMA), version-controlling them in Git, unit-testing against known attack samples, and deploying via CI/CD pipelines. This provides better detection along with the governance foundation for confidently using AI in production.
The virtuous cycle looks like this:
AI triages alerts → Analysts gain time for detection engineering → New detections catch more threats → AI model improves from expanded training data → Repeat
Threat Intelligence and Visibility Gaps
AI SOCs must operationalize threat intelligence, including IOCs, TTPs, and threat actor profiles, within detection and response workflows, not just display feeds in a dashboard. Comprehensive visibility requires coverage across five domains:
✅ Endpoint (typically strong)
✅ Cloud infrastructure (usually adequate)
⚠️ Identity / IAM (often gaps in federated identity and OAuth)
⚠️ SaaS applications (frequently a blind spot)
⚠️ Network (traffic analysis, DNS, and lateral movement)
Most organizations have strong endpoint and cloud coverage but persistent blind spots in SaaS and identity, exactly where modern attackers operate.
Three Feedback Loops That Make AI Smarter Over Time
- Analyst scoring loop: Every AI triage recommendation gets analyst accept/reject/modify scoring that retrains the model
- Detection efficacy loop: Track which detections produce true vs. false positives; auto-tune thresholds; retire noisy rules
- Playbook adaptation loop: Response playbooks evolve based on incident outcomes. If a containment action consistently requires rollback, the playbook auto-adjusts the trigger threshold
Adaptive playbooks go beyond static SOAR workflows. They incorporate AI-learned patterns to adjust response actions based on context: isolate immediately for high-criticality assets, investigate first for development endpoints.
“Their team cleaned up our configurations and got the noise under control within the first week. Now when we get an alert, we know it’s something worth looking into.”
— Verified User, Marketing and Advertising UnderDefense – G2 Verified Review
How UnderDefense Builds These Foundations
UnderDefense MAXI integrates with your existing SIEM, EDR, and cloud logs, preserving your data investments, while adding the enrichment, normalization, and AI correlation layers on top. Detection Logic as Code means your detections are written in Python, versioned, unit-tested, and deployed via CI/CD. During the 30-day onboarding, we build custom detections tuned to your environment, cutting 99% of noise and delivering only confirmed, validated offenses.
Q5. How Does MITRE ATT&CK Mapping Strengthen an AI SOC, and How Do You Validate It With Red-Teaming?
Why MITRE ATT&CK Mapping Is Non-Negotiable
MITRE ATT&CK provides a common language for objectively measuring detection coverage, enables vendor-neutral comparison between AI SOC platforms, and identifies blind spots before attackers exploit them. Without it, you’re guessing. Here’s the 3-step operational mapping process:
- Inventory all detection rules (SIEM correlation, EDR detections, and AI-driven anomaly detections) and map each to specific MITRE ATT&CK techniques and sub-techniques
- Generate a coverage heat map showing detection depth per technique: “Alert-Only” (fires but no enrichment), “AI-Enriched” (detection + automated context + risk scoring), and “Auto-Response” (triggers autonomous containment)
- Run quarterly gap analysis comparing your coverage against TTPs used by threat actors relevant to your industry
Where Blind Spots Persist
Most AI models train on high-volume, well-labeled attack data, such as phishing and malware execution, but remain under-represented on stealthy post-compromise techniques:
| Category | Status | Typical Coverage | Key Techniques |
|---|---|---|---|
| Initial Access | ✅ Over-covered | 80%+ | T1566 Phishing, T1190 Exploit Public-Facing App |
| Execution | ✅ Over-covered | 75%+ | T1059 Command and Scripting Interpreter |
| Credential Access | ⚠️ Under-covered | 35–50% | T1003 OS Credential Dumping, T1558 Kerberoasting |
| Lateral Movement | ⚠️ Under-covered | 30–45% | T1021 Remote Services, T1563 Session Hijacking |
| Defense Evasion | ❌ Under-covered | 25–40% | T1070 Indicator Removal, T1036 Masquerading |
| Persistence | ⚠️ Under-covered | 40–55% | T1053 Scheduled Task/Job, T1547 Boot Autostart |
AI-Driven Continuous Gap Analysis
AI transforms MITRE mapping from a quarterly manual exercise into a continuous posture improvement engine. A well-instrumented AI SOC can continuously compare triggered detections against the coverage map, flag techniques with zero detections over 90 days (coverage decay detection), recommend detection rules to close gaps based on industry threat intelligence, and simulate detection effectiveness through automated adversary emulation using tools like MITRE Caldera and Atomic Red Team.
Red-Teaming: Validating Effectiveness, Not Just Coverage
Coverage percentages are meaningless without validation. Here’s the 3-tier validation model:
- Automated adversary simulation (MITRE Caldera, Atomic Red Team): run known ATT&CK techniques against your AI SOC and measure detection rate + response time per technique. ⏰ Cadence: quarterly
- Tabletop exercises: walk through complex, multi-stage attack scenarios with your SOC team to test AI + human coordination under pressure. Cadence: semi-annually
- Full red-team engagement: authorized offensive testing that validates end-to-end detection, investigation, and response against realistic attacker behavior. Cadence: annually
“Their team is proactive in identifying and addressing threats, providing 24/7 oversight.”— Oleg K., Director Information Security UnderDefense – G2 Verified Review
How UnderDefense Validates Coverage
We achieve 96% MITRE ATT&CK coverage through agentic AI combined with dedicated detection engineering. During onboarding, we run MITRE Caldera-based adversary simulations to validate coverage in your specific environment, not just claim a percentage but prove it against your actual telemetry and configuration. Ongoing quarterly simulations ensure coverage doesn’t decay.
Q6. What Does a Graduated Autonomous Response Trust Ladder Look Like in Practice?
The 5-Tier Autonomous Response Trust Ladder
Autonomous response without graduated trust is reckless. Here’s the framework that maps specific actions to trust tiers, each with explicit prerequisites and rollback criteria:
| Tier | Action | Rollback Criteria | Trust Prerequisite |
|---|---|---|---|
| 1 | Block known-bad IOCs (IPs, domains, and file hashes) | Auto-revert if >0.1% legitimate traffic disrupted within 5 min | Threat intel feed validated for 30 days |
| 2 | Account and token actions (disable accounts, revoke OAuth, and force MFA) | Auto-re-enable if user verifies legitimacy via ChatOps within 15 min | Identity correlation accuracy >95% |
| 3 | Endpoint isolation via EDR API | Restore connectivity upon analyst override (pre-staged rollback) | Asset criticality mapping complete |
| 4 | Multi-step containment playbooks (isolate + revoke sessions + block lateral movement + quarantine email) | Execute full rollback playbook in sequence | Playbook tested via simulation 3+ times |
| 5 | Full incident lifecycle (detect → investigate → contain → remediate → report) | Revert to analyst-managed handling | 90-day track record with <1% false action rate at Tier 4 |
Rollback Safety: The Non-Negotiable Principle
Every autonomous action must have a documented, tested reversal path. ⚠️ Untested rollbacks are worse than no automation, because you’re adding risk, not reducing it. Mandate quarterly rollback testing for all active tiers.
The concept of blast radius containment is critical: autonomous actions at Tier 3+ should never impact more than one network segment or user group without human confirmation.
Real-World Scenario: Credential Compromise at 2:41 AM
Here’s how the trust ladder works in practice. Detection: UnderDefense MAXI flags impossible travel, where user Jane Doe authenticates from New York and Singapore within 2 hours.
At Tier 2: AI auto-disables Jane’s account, revokes all active OAuth tokens, and sends a ChatOps message via Slack: “Did you log in from Singapore at 2:41 AM?”
❌ Jane confirms no → escalate to Tier 3 (isolate Jane’s endpoint) + Tier 4 (block lateral movement from Jane’s recent access paths, and revoke sessions across connected SaaS)
✅ Jane confirms yes → re-enable account, and log false positive for model retraining
At Tier 5: the entire sequence executes autonomously with an incident report generated. The analyst reviews it in the morning, not at 2 AM.
“Before MAXI, constantly keeping an eye on our expanding cloud assets was the norm. With MAXI’s MDR, it’s like having a magnifying glass over every server.”— Lesia P., Product Marketing Manager UnderDefense – G2 Verified Review
How UnderDefense Deploys the Trust Ladder
We operate at Tier 1–3 autonomously from day one. Tier 4 progression is based on documented trust thresholds achieved during the 30-day onboarding. Our 15-minute escalation SLA for critical incidents means Tier 3–4 actions always have human validation within the containment window. ChatOps user verification resolves Tier 2 actions without analyst involvement: we ask the user directly, so your team doesn’t have to.
Q7. What Are the 7 Most Dangerous AI SOC Anti-Patterns, and How Do You Fix Them?
The Scenario Nobody Talks About
Your CISO approved the AI SOC rollout six months ago. The vendor promised 90% alert reduction. Instead, your analysts now distrust the AI’s outputs, manually re-investigate its recommendations, and your actual MTTR has increased, because nobody calibrated trust before flipping the switch. You haven’t deployed an AI SOC. You’ve deployed expensive shelfware that your team works around.
This is the cumulative consequence of anti-pattern thinking. Here are the seven deadliest.
The 7 Named Anti-Patterns
| # | Anti-Pattern | Root Cause | Consequence | Fix |
|---|---|---|---|---|
| 1 | The Big Bang Deploy | Executive pressure for immediate ROI | Analyst distrust; override rates near 100% | 4-phase shadow → advise → semi-auto → autonomous model |
| 2 | The Black-Box Blitz | Vendor provides outputs without reasoning chains | AI investment delivers zero value; MTTR increases | Mandate XAI, making every AI step observable and auditable |
| 3 | The Alert Firehose Fallacy | Confusing noise reduction with threat coverage | False negatives go undetected; real threats slip through | Track false negative rate; validate with adversary simulation |
| 4 | The Accountability Outsource | Misunderstanding AI as replacement vs. augmentation | Analyst headcount cut; novel threats go unaddressed | Define human-AI boundaries; maintain strategic analyst capacity |
| 5 | The Tool-First Trap | Vendor-driven purchasing before operational readiness | AI built on bad data produces bad outcomes | Complete data readiness checklist before any AI deployment |
| 6 | The MITRE Checkbox | Marketing-driven coverage claims vs. operational reality | Coverage claims are fiction; real gaps exploited | Validate via Caldera/Atomic Red Team; classify detection depth |
| 7 | The ROI Mirage | Board pressure for financial metrics over security effectiveness | Cost reduction achieved but detection quality degrades | Balanced scorecard: operational + security + business + AI metrics |
⚠️ Deep-Dive: The #1 Trust Destroyer, “The Black-Box Blitz”
This is the single most destructive anti-pattern because it poisons the human-AI relationship that the entire AI SOC depends on. When analysts cannot see why the AI made a decision, including what data it queried, what enrichment it performed, and what reasoning led to its conclusion, they override it 100% of the time.
The math is brutal: your AI investment delivers zero value, your analysts are doing double work (their investigation plus reviewing AI outputs they don’t trust), and MTTR actually increases. The fix is non-negotiable. Every AI investigative step must be observable and auditable.
“Analysts provide little context, and when asked for more information in the investigation nothing is ever provided or even communicated.”— CISO, Manufacturing Arctic Wolf – Gartner Verified Review
“The platform’s high-fidelity alerts and automated enrichment help us quickly identify and address threats.”— Verified User, Computer Software UnderDefense – G2 Verified Review
How We Prevent Every Anti-Pattern by Design
Every investigative step in UnderDefense MAXI is observable and auditable. Analysts see exactly what the AI queried, what logs it pulled, and why it reached its conclusion. This transparency is why our analyst override rate drops below 5% within 60 days, because trust is earned through explainability, not forced through automation. We invest a full 30 days in onboarding: building customized detections, validating with MITRE Caldera simulations, and running shadow mode before any autonomous action is enabled.
⭐ This phased, transparent approach has maintained zero ransomware cases across 500+ MDR clients for 6 years, because we avoid every anti-pattern on this list by design, not by accident.
Q8. How Do You Measure AI SOC Performance, and What ROI and Compliance Metrics Matter to the Board?
The 4-Category AI SOC Metrics Framework
Metrics without structure are just dashboards nobody reads. Here’s the framework that gives CISOs board-ready data and CFOs the numbers they need:
| Category | Key Metrics | What It Answers |
|---|---|---|
| Operational | MTTD, MTTR (alert-to-triage vs. escalation SLA), MTTA, Automation Rate, and Alert-to-Incident Ratio | “How fast and efficient is our SOC?” |
| Security Effectiveness | Kill Chain Coverage (MITRE %), Dwell Time, FP Rate, FN Rate (validated quarterly), and Containment Success Rate | “How well are we actually detecting and stopping threats?” |
| Business Impact | ROI, Cost Per Protected Asset, Cost Per Incident, Analyst Retention Rate, and Analyst Productivity (strategic hrs / total hrs) | “Is this investment justified?” |
| AI-Specific | Model Accuracy (precision/recall), Analyst Override Rate, Learning Curve, and Force Multiplication Factor | “Is the AI earning trust and delivering value?” |
⚠️ A critical distinction: UnderDefense separates the 2-minute alert-to-triage SLA from the 15-minute escalation SLA for critical incidents. “MTTR” as a single number conflates two very different measurements.
💰 The AI SOC ROI Formula, a Worked Example
ROI = [(Analyst Hours Saved × Blended Rate) + (Breach Cost Averted × Probability Reduction) + (Tool Consolidation Savings)] ÷ Total Platform Cost
For a 500-endpoint organization with 3 SOC analysts spending 60% on manual triage:
- Analyst hours recovered: AI reduces manual triage by 80% → 2,880 hours/year → 💸 $172K at $60/hr blended rate
- Breach cost reduction: MTTR improvement from 4h to 30min reduces breach probability ~40% → $1.95M in averted expected cost (based on $4.88M avg. breach cost, IBM 2025)
- Tool consolidation: Unified platform replaces 2 standalone tools → $45K/year
- Platform cost: $15/endpoint/month = $90K/year
⭐ Year 1 net ROI: $2.17M / $90K = significant positive return. Over 3 years: 830% ROI, consistent with documented UnderDefense outcomes.
Compliance Alignment: AI SOC as Evidence Engine
| Framework | Requirement | AI SOC Metric / Capability |
|---|---|---|
| NIST CSF Detect | Continuous monitoring | MTTD, MITRE coverage %, and threat intel integration |
| NIST CSF Respond | Timely response | MTTR, containment success rate, and escalation SLA |
| SOC 2 CC7.2 | Security monitoring | 24/7 monitoring evidence and alert triage documentation |
| SOC 2 CC7.3 | Incident response | Response time documentation and post-incident reports |
| DORA Article 11 | ICT incident management | Detection/response SLAs and incident classification |
| NIS2 Article 21 | Risk management measures | Continuous monitoring evidence and risk assessments |
The key insight: a well-instrumented AI SOC generates compliance evidence automatically as a byproduct of normal operations, not as a separate manual exercise.
“The reports from their platform give us clear evidence of our security controls and incident response capabilities. When auditors or clients ask questions about our security posture, we can pull up exactly what they need to see.”— Verified User, Marketing and Advertising UnderDefense – G2 Verified Review
Board-Ready Reporting Cadence
- Monthly dashboard: MTTD trend, MTTR trend, Automation Rate, Cost Per Incident, and MITRE Coverage %
- Quarterly strategic review: ROI update, Analyst Productivity shift, Compliance Coverage status, and AI-Specific metrics
- Annual: Full ROI audit with CFO-ready cost-benefit analysis
UnderDefense MAXI’s Risk Dashboard provides real-time visibility into all four metric categories, giving CISOs board-ready data without manual report building. Compliance evidence (SOC 2, ISO 27001, and HIPAA) is generated automatically. Forever-free compliance kits are included with MDR.
Q9. What Does an AI SOC Look Like in Action? Use Cases From Phishing Triage to Insider Threat Detection
AI SOC best practices only matter if they translate to real-world operational outcomes. Here are four use cases where AI-driven SOC capabilities replace manual, error-prone workflows with machine-speed detection, investigation, and containment, with measurable before/after metrics at each stage.
✅ Use Case 1: Automated Phishing Investigation and Response
Before: An analyst spends 25 to 45 minutes per phishing alert, manually analyzing email headers, detonating URLs in a sandbox, checking sender reputation, querying threat intel, and verifying with the recipient whether they clicked. At scale, a mid-market company processing 50+ phishing alerts per day loses 20 to 30 analyst hours weekly on triage alone.
After: AI detonates URLs, analyzes headers, correlates sender reputation, and checks threat intel in under 60 seconds. ChatOps verifies directly with the recipient via Slack or Teams: “Did you click this link?” Confirmed phishing triggers auto-quarantine of the email, credential reset, and a similar-message sweep across all mailboxes.
⏰ Before MTTR: 45 min → After MTTR: 3 min
✅ Use Case 2: Behavioral Identity Threat Detection
Before: Impossible travel alerts generate 200+ false positives per week, each requiring manual investigation of user travel patterns, VPN usage, and device fingerprints. Analysts burn hours chasing legitimate business travelers flagged by rigid rules.
After: AI correlates identity alerts with HR travel data, VPN logs, device fingerprints, and historical user behavior baselines. Only verified anomalies, where the user confirms via ChatOps “I am NOT in Singapore,” escalate to an analyst.
⏰ Before: 200 alerts/week → After: 5 to 10 confirmed incidents/week
✅ Use Case 3: Endpoint Malware Triage at Scale
Before: An analyst triages 50 to 100 endpoint alerts daily, manually investigating file hashes, process trees, and registry changes. Each alert consumes 15 minutes of context-switching and tool-hopping between EDR, SIEM, and threat intel platforms.
After: AI auto-enriches file hashes against threat intel, detonates suspicious files in a sandbox, reconstructs the process tree, and classifies severity. The analyst receives a structured investigation report with a recommended action in 90 seconds.
⏰ Before: 15 min/alert → After: 90 seconds/alert
✅ Use Case 4: Correlation-Driven Insider Threat Detection
Before: Insider threat signals, including unusual data access, off-hours activity, and privilege escalation, exist in separate tools (DLP, IAM, UEBA) with no cross-correlation. Threats are detected post-exfiltration, after the damage is done.
After: AI correlates signals across all data sources, builds a behavioral risk score per user, and ChatOps verifies with the user’s manager when anomaly thresholds are exceeded: “Did John need access to the finance database this weekend?” Threats are detected during the reconnaissance and staging phase, not after data leaves the building.
⏰ Before: Detected post-exfiltration → After: Detected during staging
How UnderDefense MAXI Delivers All Four
UnderDefense MAXI delivers all four use cases through a single platform. Vendor-agnostic integration connects your endpoint, identity, email, and cloud telemetry, while agentic AI and ChatOps user verification close alerts that competitors simply escalate back to your team.
UnderDefense detected and contained threats 2 days faster than CrowdStrike OverWatch in documented case studies, because AI-driven detection without human context still leaves gaps only analysts communicating directly with users can close.
“Their team cleaned up our configurations and got the noise under control within the first week. Now when we get an alert, we know it’s something worth looking into.”
— Verified User, Marketing and Advertising UnderDefense – G2 Verified Review
“The platform’s high-fidelity alerts and automated enrichment help us quickly identify and address threats.”
— Verified User, Computer Software, Enterprise UnderDefense – G2 Verified Review
Q10. How Should Security Leaders Compare AI SOC Vendors? An 8-Criteria Evaluation Framework
The Decision Dilemma
Choosing an AI SOC platform means committing to a security architecture that will define your detection and response capability for the next 3 to 5 years. Pick wrong, and you’re locked into a proprietary stack, paying for alert volume without actionable context, or worse: deploying AI that your analysts don’t trust and manually work around, doubling their workload instead of halving it.
❌ The Wrong Way to Decide
Most security leaders choose based on brand recognition (“CrowdStrike is the biggest”), demo impressions (“the AI dashboard looked impressive”), or integration count (“they support our SIEM”). This ignores the critical questions: Can you audit every AI decision? Can they verify alerts directly with your users? Do they actually respond to threats, or just detect and escalate tickets back to your team? The vendor landscape is full of AI SOC platforms that automate the wrong things: triage without context, detection without response, and correlation without explainability.
The Right Evaluation Framework: 8 Criteria
Here’s the objective methodology any buyer should use. Each criterion implicitly separates genuine AI SOC partners from repackaged alert feeds:
- AI Explainability & Auditability — Can you see every step the AI took, what it queried, what enrichment it performed, and why it reached its conclusion? Or is it a black box?
- Vendor-Agnostic Integration — Does it work with your existing SIEM, EDR, cloud, identity, and SaaS tools? Or does it force proprietary stack replacement, abandoning your current investments?
- Human Analyst Access — Do you get direct communication with Tier 3 to 4 experienced analysts? Or ticket-based escalation where alerts come back without answers?
- Response Capability — Can they contain and remediate threats (isolate endpoints, revoke credentials, block lateral movement)? Or just detect and notify?
- User Verification (ChatOps) — Can they verify suspicious activity directly with affected users via Slack, Teams, email, or SMS? Or do they escalate “please investigate” back to your team?
- MITRE ATT&CK Coverage — Documented coverage percentage validated by adversary simulation? Or marketing claims without operational proof?
- 💰 Pricing Transparency — Published, predictable per-endpoint rates? Or opaque “contact sales” with $96K+ median annual contracts?
- Trust Calibration Model — Phased deployment with documented trust gates, shadow mode, and analyst feedback loops? Or “flip the switch on day one”?
Scoring and Comparison
Score each vendor 0 to 2 per criterion (0 = not available, 1 = partial, 2 = fully meets):
| Criterion | UnderDefense MAXI | Arctic Wolf | CrowdStrike Falcon Complete | ReliaQuest GreyMatter | Exabeam |
|---|---|---|---|---|---|
| AI Explainability | ✅ 2 | ⚠️ 1 | ⚠️ 1 | ⚠️ 1 | ⚠️ 1 |
| Vendor-Agnostic Integration | ✅ 2 | ❌ 0 | ❌ 0 | ✅ 2 | ⚠️ 1 |
| Human Analyst Access | ✅ 2 | ✅ 2 | ⚠️ 1 | ❌ 0 | ❌ 0 |
| Response Capability | ✅ 2 | ⚠️ 1 | ✅ 2 | ⚠️ 1 | ⚠️ 1 |
| User Verification (ChatOps) | ✅ 2 | ❌ 0 | ❌ 0 | ❌ 0 | ❌ 0 |
| MITRE ATT&CK Coverage | ✅ 2 | ⚠️ 1 | ✅ 2 | ⚠️ 1 | ✅ 2 |
| Pricing Transparency | ✅ 2 | ❌ 0 | ❌ 0 | ❌ 0 | ❌ 0 |
| Trust Calibration Model | ✅ 2 | ⚠️ 1 | ⚠️ 1 | ⚠️ 1 | ⚠️ 1 |
| Total /16 | 16 | 6 | 7 | 6 | 6 |
Scoring interpretation: 14 to 16 = genuine operational partnership; 10 to 13 = solid, but negotiate gap coverage; below 10 = you’re buying an alert feed, not managed detection and response.
Who Should Choose What
Choose Arctic Wolf if you’re starting from scratch with zero existing security investments and prefer single-vendor simplicity. Choose CrowdStrike if you’re already all-in on Falcon and need Falcon-native MDR. Choose UnderDefense if you want to protect your existing stack investments, need AI decisions you can audit, require transparent predictable pricing, and want analysts who verify alerts directly with users rather than escalating back to your team.
UnderDefense maintains 100% ransomware prevention across 500+ MDR clients over 6 years, $11 to $15/endpoint/month published pricing, and 1% customer churn, because the framework reveals the answer when you apply it honestly.
“We received little value from ArcticWolf. The product offered little visibility when we were using it. Anything you want to look at or changes you need to make in the product must go through their engineering team.”
— Matt C., Manager, Cybersecurity Services Arctic Wolf – G2 Verified Review
“Arctic Wolf provides solid detection and response capabilities, but overly relies on the client’s team for remediation, which really hurts the value of the service.”
— VP of Technology, Services Arctic Wolf – Gartner Verified Review
“UnderDefense is surprisingly affordable considering the level of protection we get. Their proactive threat hunting and rapid response have saved us from incidents that could have been incredibly costly.”
— Verified User, Program Development UnderDefense – G2 Verified Review
Q11. Which AI SOC Platforms Are Security Leaders Evaluating in 2026?
The leading AI SOC platforms security leaders are evaluating in 2026 span four categories: AI-native SOC platforms (UnderDefense MAXI, Intezer, Prophet Security, Radiant Security), MDR-embedded AI (CrowdStrike Falcon Complete, Arctic Wolf), SIEM/XDR-native AI (Microsoft Security Copilot, Google SecOps, Exabeam, Palo Alto XSIAM), and SOAR-evolved AI (Torq Socrates, Swimlane Turbine). UnderDefense MAXI leads in vendor-agnostic integration, AI explainability, and ChatOps user verification.
Selection Criteria That Actually Matter
The AI SOC market has fragmented into platforms that automate different parts of the security operations workflow, and the right choice depends on your existing stack, team size, and operational maturity. What separates top AI SOC platforms:
- Vendor-agnostic integration vs. proprietary stack lock-in
- AI explainability, observable reasoning vs. black-box outputs
- Response capability, full containment vs. detection-only
- Human analyst access, direct Tier 3 to 4 communication vs. ticket-based escalation
- Published pricing and SLAs vs. opaque enterprise quotes
Where Each Platform Fits
Each platform excels in different scenarios: UnderDefense MAXI for organizations protecting existing stack investments with transparent pricing and human analyst concierge support, CrowdStrike for Falcon-native environments, Microsoft Security Copilot for all-in Microsoft shops, and Exabeam for UEBA-focused analytics. The right choice depends on your current security investments, team maturity level, and operational priorities.
This analysis is based on documented response times, G2 Spring 2025 to 2026 rankings, published pricing, MITRE ATT&CK coverage validation, and operational outcomes across 500+ MDR deployments.
Q12. What Does the Future of AI in Security Operations Look Like?
The Trajectory: From AI-Assisted to AI-Autonomous
Most organizations today sit between Level 2 and Level 3 on the AI SOC maturity curve. AI assists with triage and enrichment, but humans still drive investigation and response. The technology frontier, however, is already at Level 5 and beyond. Three architectural shifts will define the next phase of AI SOC evolution: multi-agent collaboration, privacy-preserving cross-organization learning, and natural language interfaces that make SOC expertise accessible to non-specialists. These are not theoretical. They are emerging in production environments today and will become table stakes within 18 to 24 months.
Multi-Agent Architectures and Agentic AI
The current AI SOC model uses a single AI system for triage and enrichment. The next generation deploys multiple specialized AI agents that collaborate: a triage agent that prioritizes alerts, an investigation agent that performs deep-dive analysis, a response agent that executes containment, a detection engineering agent that writes and tests new rules, and a compliance agent that maps actions to regulatory requirements.
These agents communicate through structured protocols, hand off context seamlessly, and can run parallel investigation paths for complex incidents. The practical implication for security leaders: evaluate whether your AI SOC vendor’s architecture supports multi-agent extensibility or is locked to a monolithic model. UnderDefense’s agentic AI architecture is already built on this principle, with multiple specialized agents collaborating within the MAXI platform.
Federated Learning and Conversational SOC Interfaces
The biggest limitation of current AI SOCs is that each deployment learns only from its own data. Federated learning enables AI models to learn from threat patterns across hundreds of organizations without sharing raw data, improving detection accuracy for everyone while preserving data privacy and sovereignty. This is critical for regulated industries (healthcare, financial services) where data cannot leave organizational boundaries.
Simultaneously, natural language interfaces are transforming how analysts interact with SOC platforms. Instead of writing complex queries and parsing dashboards, analysts ask plain-language questions like “Show me all suspicious PowerShell executions from privileged accounts this week” or “What’s the risk score trend for our executive team?” This democratizes SOC expertise, enabling Level 1 analysts to perform Level 2 to 3 analysis through AI-guided conversation, and non-security stakeholders (CTO, CFO) to query security posture directly.
What This Means for Investment Decisions Today
Security leaders don’t need to wait for the future, but they should invest in AI SOC platforms architected for extensibility. Three decision criteria for future-readiness:
- Is the platform’s AI architecture modular/multi-agent capable, or monolithic? Monolithic models require expensive rip-and-replace cycles as capabilities evolve.
- Does the vendor’s detection model improve from cross-customer intelligence (federated learning), or learn only from your data? Collective intelligence compounds detection accuracy over time.
- Does the platform support NLP/conversational interfaces for analyst interaction? Plain-language querying accelerates investigation speed and reduces the training burden for new analysts.
UnderDefense: Built for What’s Next
UnderDefense MAXI is purpose-built on an agentic AI architecture, with multiple specialized agents collaborating across triage, investigation, response, and compliance. Our AI model improves from patterns observed across our entire customer base (500+ organizations), delivering collective intelligence without exposing individual customer data.
The future of security operations is not about replacing humans with AI. It is about giving every analyst the speed of AI and every AI the judgment of an experienced human. That is not a tagline but the operational reality we deliver every day, and the architectural foundation that makes what’s coming next possible.
1. What is an AI-powered SOC, and how does it differ from a traditional security operations center?
An AI-powered SOC is a security operations center where artificial intelligence handles machine-speed enrichment, triage, correlation, and, at advanced maturity levels, autonomous response actions. Human analysts retain decision authority over high-stakes and novel threats.
The key difference lies in how alerts are processed. In a traditional SOC, analysts manually investigate every alert from scratch, creating massive backlogs and alert fatigue. In an AI-powered SOC, agentic AI automates the mechanical investigation steps: context collection, log enrichment, multi-system correlation, and structured report generation.
We built UnderDefense MAXI on the AI SOC + Human Ally model, where AI handles investigation grunt work and experienced analysts provide judgment on novel threats and business-context decisions. The result is 2-minute alert-to-triage and 15-minute escalation for critical incidents, with every investigative step observable and auditable.
The evolution spans four stages: manual reactive SOC, rule-augmented SOC, AI-assisted SOC, and AI-driven autonomous SOC with human oversight. Most organizations remain stuck between stages one and two, while threat actors have already weaponized agentic AI for reconnaissance, adaptive malware, and scaled phishing campaigns.
2. How do you assess your organization's AI SOC maturity level?
We use a 5-level AI SOC maturity framework with specific KPI thresholds at each stage. The levels progress from Manual/Reactive SOC (Level 1, 100% human involvement) through Rule-Augmented (Level 2, 85%), AI-Assisted (Level 3, 50-60%), AI-Driven (Level 4, 25-30%), to Autonomous AI SOC with Human Oversight (Level 5, 10-15%).
Each level has measurable trust gates that must be met before advancing. For example, Level 3 requires AI accuracy above 90%, analyst override rate below 15%, and false positive rate under 10%. Level 5 demands zero critical false negatives over a 30-day window and 99% rollback success.
Self-assessment starts with honest questions: Do your analysts manually investigate every alert? Do you have SIEM rules but analysts still triage most alerts? Does your AI execute containment without analyst approval? These levels map directly to NIST CSF Detect/Respond functions and MITRE ATT&CK technique coverage percentages.
We designed UnderDefense MAXI to accelerate organizations from Level 1 to Level 3 within 30 days, using MITRE Caldera-based adversary simulation to validate your actual maturity level.
3. What is the trust calibration model for phased AI SOC deployment?
Trust calibration is a 4-phase deployment model that earns analyst confidence through measurable outcomes rather than mandating trust overnight. The phases are:
Phase 1, Shadow Mode (2-4 weeks): AI runs in parallel. Outputs are compared but not actioned. Analysts validate every AI output.
Phase 2, Advise Mode (4-8 weeks): AI generates prioritized recommendations with full reasoning chains. Analysts approve or reject every recommendation.
Phase 3, Semi-Autonomous (8-12 weeks): AI executes low-risk containment (block IPs, disable accounts, revoke tokens). Analysts review within a 15-minute window.
Phase 4, Autonomous with Escalation (ongoing): AI handles the routine incident lifecycle. It escalates novel and high-severity cases to human analysts.
Specific trust gates govern transitions. Phase 2 to 3 requires AI recommendation accuracy above 90% and analyst override rate below 15%. Phase 3 to 4 requires autonomous action success rate above 98% and rollback execution time under 2 minutes. Our 30-day MDR onboarding follows this exact model, with our concierge Tier 3-4 analyst team handling escalations within a 15-minute critical incident SLA.
4. What data quality foundations does an AI SOC require before deployment?
AI models are only as good as the data they ingest. Every impressive AI SOC demo falls apart the moment you feed it incomplete, unnormalized, or stale telemetry. We require five data readiness prerequisites before any AI deployment:
Log completeness: all critical sources (endpoint, cloud, identity, network, SaaS, email) must feed the detection layer. Common blind spots include SaaS application logs and cloud control plane logs.
Log normalization: events from different vendors must map to a common schema (OCSF, ECS) so AI can correlate across sources.
Enrichment pipelines: raw logs must be enriched with threat intelligence, geo-IP, asset criticality, and user context before AI processing.
Data freshness: log ingestion latency must stay under 5 minutes, because stale data means stale detections.
Data governance: retention policies, access controls, and privacy requirements (GDPR, data residency) must be documented and enforced.
UnderDefense MAXI integrates with your existing SIEM, EDR, and cloud logs, adding enrichment, normalization, and AI correlation layers on top. During the 30-day onboarding, we build custom detections tuned to your environment, cutting 99% of noise and delivering only confirmed, validated offenses.
5. How do you validate MITRE ATT&CK coverage in an AI SOC with red-teaming?
MITRE ATT&CK mapping without validation is marketing fiction. We use a 3-tier validation model to ensure coverage claims translate to operational reality.
Tier 1, Automated adversary simulation: tools like MITRE Caldera and Atomic Red Team run known ATT&CK techniques against your AI SOC and measure detection rate plus response time per technique. This runs quarterly.
Tier 2, Tabletop exercises: walk through complex, multi-stage attack scenarios with your SOC team to test AI-human coordination under pressure. This runs semi-annually.
Tier 3, Full red-team engagement: authorized offensive testing that validates end-to-end detection, investigation, and response against realistic attacker behavior. This runs annually.
Most AI models over-index on initial access (80% coverage) and execution (75%) but remain severely under-covered on lateral movement (30-45%), defense evasion (25-40%), and credential access (35-50%). These are exactly the post-compromise techniques sophisticated attackers rely on.
We achieve 96% MITRE ATT&CK coverage through agentic AI combined with dedicated detection engineering. During onboarding, we run Caldera-based adversary simulations against your actual telemetry and configuration to prove coverage, not just claim it.
6. What are the most dangerous AI SOC deployment anti-patterns, and how do you avoid them?
We have identified seven named anti-patterns that consistently destroy AI SOC deployments:
The Big Bang Deploy: executive pressure for immediate ROI leads to analyst distrust and override rates near 100%. Fix: use the 4-phase shadow-advise-semi-auto-autonomous model.
The Black-Box Blitz: vendor provides outputs without reasoning chains. AI investment delivers zero value and MTTR actually increases. Fix: mandate explainable AI (XAI), making every AI step observable and auditable.
The Alert Firehose Fallacy: confusing noise reduction with threat coverage. Real threats slip through undetected. Fix: track false negative rate and validate with adversary simulation.
The Accountability Outsource: treating AI as analyst replacement instead of augmentation. Novel threats go unaddressed. Fix: define clear human-AI boundaries.
The Tool-First Trap: purchasing AI before operational readiness. Fix: complete data readiness checklist first.
The MITRE Checkbox: marketing-driven coverage claims without operational proof. Fix: validate via Caldera/Atomic Red Team.
The ROI Mirage: optimizing cost metrics while detection quality degrades. Fix: use a balanced scorecard across operational, security, business, and AI metrics.
Every investigative step in UnderDefense MAXI is observable and auditable, which is why our analyst override rate drops below 5% within 60 days.
7. How do you calculate AI SOC ROI for board-level budget approval?
We use a 4-category metrics framework covering operational, security effectiveness, business impact, and AI-specific measurements. The ROI formula is:
ROI = (Analyst Hours Saved × Blended Rate) + (Breach Cost Averted × Probability Reduction) + Tool Consolidation Savings – Total Platform Cost.
For a 500-endpoint organization with 3 SOC analysts spending 60% on manual triage: AI reduces manual triage by 80%, recovering 2,880 hours/year ($172K at $60/hr blended rate). MTTR improvement from 4 hours to 30 minutes reduces breach probability 40%, averting $1.95M in expected cost. Unified platform replaces 2 standalone tools, saving $45K/year. At $15/endpoint/month ($90K/year platform cost), Year 1 net ROI is $2.17M, and the 3-year ROI reaches 830%.
A critical distinction we enforce: the 2-minute alert-to-triage SLA and 15-minute escalation for critical incidents are separate measurements. Conflating them into a single “MTTR” number obscures real performance.
Board reporting should follow a monthly dashboard (MTTD/MTTR trends, automation rate), quarterly strategic review (ROI update, compliance coverage), and annual full ROI audit cadence.
8. Which AI SOC platforms should security leaders evaluate in 2026, and how do they compare?
The leading AI SOC platforms in 2026 span four categories: AI-native SOC platforms (UnderDefense MAXI, Intezer, Prophet Security, Radiant Security), MDR-embedded AI (CrowdStrike Falcon Complete, Arctic Wolf), SIEM/XDR-native AI (Microsoft Security Copilot, Google SecOps, Exabeam, Palo Alto XSIAM), and SOAR-evolved AI (Torq Socrates, Swimlane Turbine).
We recommend scoring vendors across 8 criteria: AI explainability and auditability, vendor-agnostic integration, human analyst access, response capability, user verification via ChatOps, MITRE ATT&CK coverage, pricing transparency, and trust calibration model. Score each 0-2 (0 = not available, 1 = partial, 2 = fully meets).
In documented evaluations, UnderDefense MAXI scores 16/16, CrowdStrike Falcon Complete scores 7/16, and Arctic Wolf scores 6/16. The primary differentiators are vendor-agnostic integration (works with your existing stack), ChatOps user verification (no other provider does this at scale), and published $11-15/endpoint/month pricing.
Choose Arctic Wolf for zero-investment greenfield environments. Choose CrowdStrike for all-in Falcon shops. Choose UnderDefense for protecting existing stack investments with auditable AI and transparent pricing. For a deeper dive, see our complete SOC-as-a-service provider ranking.
The post AI SOC Best Practices: Autonomous Response, MITRE Mapping, Anti-Patterns & ROI Metrics Guide appeared first on UnderDefense.