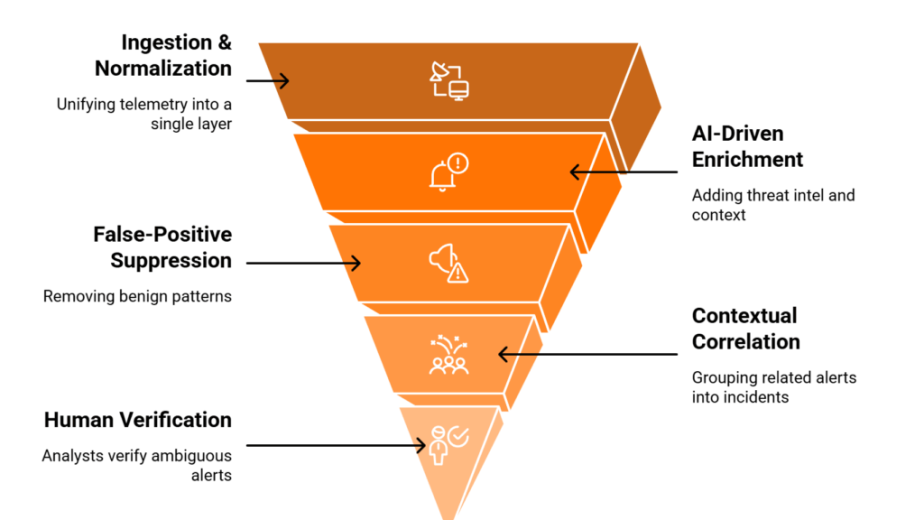
Q1. Why Do You Need an AI SOC Features Checklist in 2026, and What Happens Without One?
The 2026 AI SOC Market Is Flooded, and Most Buyers Are Flying Blind
Every vendor in the AI SOC space right now claims “autonomous detection,” “full MITRE coverage,” and “zero analyst burden.” I’ve sat across the table from enough CISOs and IT Directors to know what happens next: they buy the pitch, deploy the platform, and six months later their team is still triaging the same alert noise, just from a shinier dashboard. Without a structured checklist, you’re comparing marketing decks, not capabilities. You end up paying premium prices for what should be standard features, locked into a vendor’s ecosystem before you even realize the tradeoffs.
The problem isn’t a lack of options, but that the options look identical on the surface. Arctic Wolf, CrowdStrike Falcon Complete, ReliaQuest, Rapid7: they all say the right things in demos. But the operational reality? Most traditional MDR providers sell detection volume, not detection depth. Dashboards full of alerts without contextual investigation. MITRE “coverage” claims without sub-technique mapping. “Automation” that still requires your team to do the actual triage and investigation work. The result is alert fatigue dressed in AI branding.
⚠️ The Real Question Has Changed
Here’s what I’ve seen repeatedly across real client engagements: organizations onboard an AI SOC vendor expecting operational relief, and within 90 days they’re back to square one. The alerts keep flowing. The context is still missing. The “AI” is really just pattern matching running on top of a legacy correlation engine. Your team remains the manual correlation layer between your EDR, your SIEM, your identity provider, and your cloud console, exactly where they were before.
The shift in 2026 isn’t “Does this AI SOC detect threats?” because every vendor clears that bar. The real question is: Can it reason across your stack, hunt proactively, respond at the right automation tier, and prove coverage depth against ATT&CK sub-techniques? That’s what separates a checklist built for 2026 from the generic “top 10 features” listicles that dominated 2024.
The Standard vs. Premium Philosophy
This article is built around a principle we apply at UnderDefense every day: the features most vendors charge extra for, such as threat hunting, compliance automation, and dedicated analyst access, should be standard, not premium upsells. We built the UnderDefense MAXI platform around vendor-agnostic integration with 250+ tools, 96% MITRE ATT&CK coverage, dedicated concierge analysts, and transparent pricing ($11–15/endpoint/month) where detection, response, threat hunting, and compliance automation are all included from day one, not gated behind add-on modules. While traditional AI SOC vendors charge separately for threat hunting, compliance reporting, and analyst access, we include all three as standard, with a documented 2-minute alert-to-triage and 15-minute escalation for critical incidents, plus 100% ransomware prevention across 500+ clients.
✅ What This Checklist Will Help You Do
- Separate must-have AI SOC capabilities from vendor upsells masquerading as features
- Evaluate detection depth beyond surface-level MITRE percentages
- Identify the right automation tier for every SOC task, and where humans must stay in the loop
- Score vendors using a structured framework, not brand recognition or integration count
- Demand proof: observable workflows, auditable decisions, and reproducible outcomes
The goal isn’t to tell you what to buy. It’s to give you the framework so you can see through the noise yourself. Show, don’t tell: that’s the only way this works.
Q2. What Detection Depth Should You Demand, and How Do You Measure MITRE ATT&CK Coverage Beyond a Percentage?
Detection Depth ≠ Detection Count
When a vendor says “95% MITRE ATT&CK coverage,” the first question should be: coverage of what, exactly? The MITRE ATT&CK Enterprise Matrix currently includes 14 tactics, approximately 200–250 techniques, and 400–700+ sub-techniques depending on the version. Technique-level coverage, such as “we detect Credential Dumping,” is broad. Sub-technique coverage, such as “we detect LSASS Memory access via Mimikatz, DCSync, and /proc/kcore reads separately with distinct confidence scoring,” is operational.
Most vendors report technique-level numbers because they’re far easier to inflate. A single broad detection rule can technically “cover” an entire technique while missing the specific sub-technique variants that attackers actually exploit in real-world intrusions. Detection depth means fidelity, confidence scoring, and sub-technique granularity, not checkbox compliance against a marketing-friendly percentage.
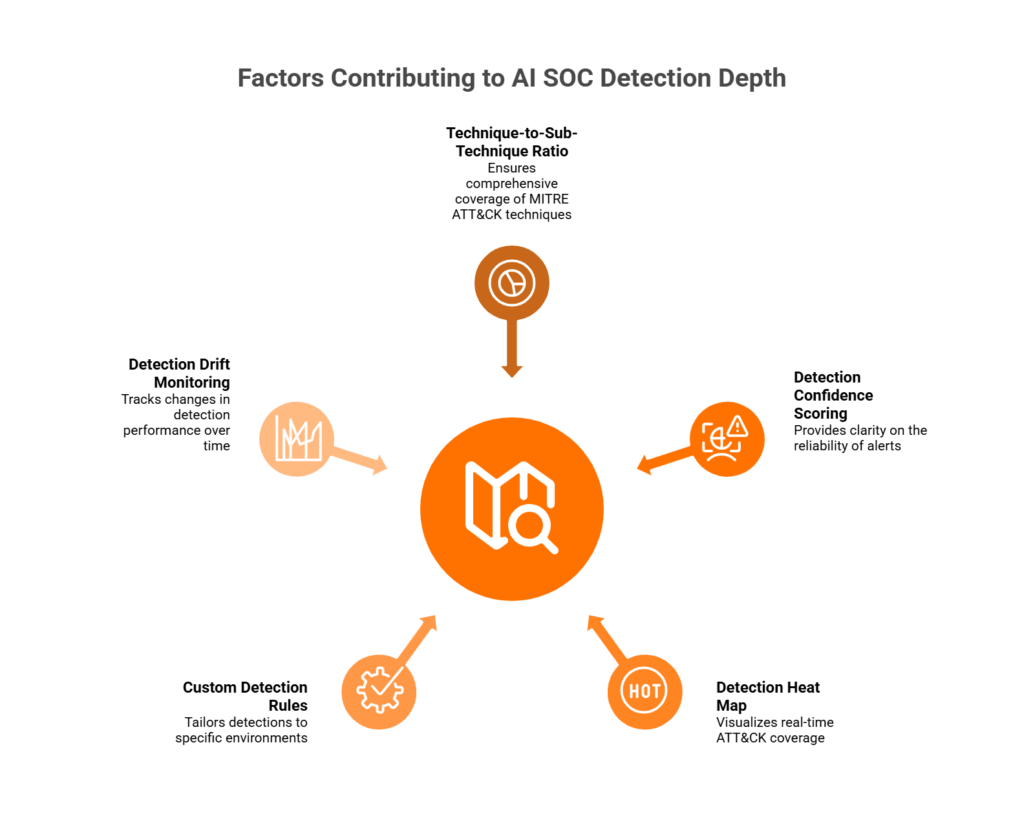
📋 5-Point Detection Depth Scoring Framework
Use this framework when evaluating any AI SOC or MDR provider’s MITRE claims:
- Technique-to-Sub-Technique Ratio — Demand ≥85% technique AND ≥60% sub-technique coverage for your top-5 risk tactics (typically Initial Access, Execution, Credential Access, Lateral Movement, and Defense Evasion). If a vendor can’t break down coverage by tactic, that’s a red flag.
- Detection Confidence Scoring — Every alert should carry a high/medium/low confidence label. If the vendor can’t tell you how confident they are in a detection, the detection is noise, not signal.
- Detection Heat Map — Require a visual ATT&CK coverage dashboard showing exactly where detections exist and where gaps remain. No heatmap = no accountability for what’s actually covered.
- Custom Detection Rules Beyond Out-of-Box — Ask how many custom rules they’ve built for environments like yours. Out-of-box detections are a starting point, not a finish line. Your environment has unique applications, user behaviors, and risk patterns.
- Detection Drift Monitoring — Coverage degrades over time as your environment changes, new tools are added, and threat actors evolve. Demand a mechanism for tracking coverage regression, not just a point-in-time snapshot from onboarding day.
Good vs. Inadequate Detection Depth
| Criteria | ✅ Demand as Standard | ❌ Often Charged Extra |
|---|---|---|
| Sub-technique mapping | Mapped per tactic with confidence scores | “Available in premium tier” |
| Detection heat map | Real-time, accessible in dashboard | Static PDF in quarterly review |
| Custom detection rules | Tuned during onboarding, continuously updated | Requires professional services engagement |
| Confidence scoring | High/med/low per alert with evidence chain | Binary alert/no-alert output |
| Drift monitoring | Automated regression tracking | Manual annual review (if at all) |
How UnderDefense Simplifies This
We built detection depth measurement into the UnderDefense MAXI platform as a standard feature, not a premium report you request quarterly. That means 96% MITRE ATT&CK technique coverage with sub-technique mapping across all 14 tactics, real-time detection heat maps accessible in your dashboard, and continuous coverage tuning by dedicated analysts who know your environment. You don’t need to build a scoring framework from scratch. You can audit ours directly from day one during the 30-day onboarding, validate the claims firsthand, and hold us accountable with the same metrics we’ve outlined above.
Q3. What Automation Tiers Should an AI SOC Offer, and Where Must Humans Stay in the Loop?
The 5-Level AI SOC Automation Maturity Model
Not all automation is created equal, and the word “automated” in a vendor pitch means wildly different things depending on context. Here’s a maturity model to map the full spectrum:
- Level 0, Manual/Reactive: Analyst sees alert, manually investigates, manually responds. No automation. This is where most under-resourced teams live today.
- Level 1, Assisted: AI enriches alerts with context (threat intel, asset info, user history). Humans still make every decision, but with better information.
- Level 2, Semi-Autonomous: AI recommends specific actions (isolate this endpoint, revoke this credential). Humans approve or reject each recommendation.
- Level 3, Autonomous: AI contains low- and medium-severity threats automatically. Humans handle high-severity incidents and edge cases requiring business context.
- Level 4, Predictive: AI hunts proactively based on behavioral anomalies and ATT&CK patterns. Humans govern policy and manage strategic exceptions.
⏰ Task-to-Tier Mapping: What to Demand in 2026
| SOC Task | Target Level | Notes |
|---|---|---|
| Alert triage & enrichment | L3 | Fully automated with human review of exceptions |
| Phishing investigation | L3 | AI analyzes headers, links, attachments; auto-quarantines confirmed phish |
| Endpoint isolation | L2–L3 | Policy guardrails required for production systems |
| Credential revocation | L2 | AI recommends, human approves: too many business-context dependencies |
| Threat hunting hypothesis | L2–L3 | AI generates hypotheses; analysts validate findings |
| Compliance evidence | L3–L4 | Fully automated and audit-ready |
| Incident reporting | L3 | AI drafts report; analyst reviews and publishes |
For 2026, demand at minimum Level 2–3 across all core SOC tasks. Any vendor still operating at Level 0–1 for triage and phishing investigation is selling you a 2020 SOC in a 2026 wrapper.
🛑 Actions That Should NEVER Be Fully Autonomous
This is where the “fully autonomous SOC” narrative breaks down, and where I push back hard on vendors selling zero-human-intervention as a feature. Certain actions require human judgment, full stop:
- Production system shutdown — The business impact of a false positive is catastrophic. Humans must authorize before any production system goes offline.
- Legal/regulatory notification — Breach notification involves legal, PR, and executive stakeholders. AI cannot make this call.
- Cross-environment containment — Isolating an entire network segment affects operations across departments. Requires explicit human impact assessment.
- VIP account actions — Disabling access for C-suite or critical service accounts needs explicit human sign-off with organizational context.
These guardrails should be defined contractually, not left as implicit assumptions buried in terms of service. Ask your vendor specifically: “What actions does your system take without human approval, and what’s the escalation policy for high-impact responses?”
How UnderDefense Handles This
Our UnderDefense MAXI platform operates at Level 3 for triage, phishing, and endpoint containment, with Level 4 predictive hunting running continuously. Human-in-the-loop guardrails for high-impact actions (credential revocation for VIP accounts, network segmentation changes) ensure you maintain control without creating bottlenecks. Our analysts communicate directly with affected users via Slack, Teams, or email to verify suspicious activity before escalating, because the fastest way to close an alert isn’t another automation rule but asking the human involved. All included as standard with our managed detection and response service.
Q4. How Should AI SOC Threat Hunting Work, and When Do You Still Need Human Analysts?
Three Hunting Models, and Why Most Vendors Won’t Tell You Which One They Use
Threat hunting in 2026 splits into three distinct models, and the differences matter more than vendors want to admit:
- Human-Led Hunting — Analyst formulates hypothesis based on threat intelligence, manually investigates, and documents findings. Deep but slow; doesn’t scale for mid-market teams.
- AI-Assisted Hunting — AI generates hypotheses from behavioral anomalies and ATT&CK patterns; human analysts investigate and validate. Scales better while preserving contextual judgment.
- Fully Autonomous Hunting — AI hunts, correlates, and escalates without human involvement. Fast, but consistently misses context-dependent threats like insider activity and supply chain anomalies.
Most vendors claim “AI-powered hunting” without specifying which model, because the answer is often “we run scheduled queries and call it hunting.” That’s not hunting. That’s monitoring with better marketing.
❌ Where Autonomous Hunting Falls Short
Autonomous hunting catches known patterns well: anomalous login times, suspicious process trees, and known C2 communication. But it misses threats requiring organizational context:
- An employee accessing sensitive files at 2 AM due to a project deadline, not a threat, but indistinguishable from exfiltration without business context.
- A third-party vendor using a legitimate admin tool in a way that’s abnormal for your environment but normal for their role.
- A supply chain compromise where malicious behavior looks identical to authorized software updates.
As one experienced CISO shared during a conversation about building resilient security: “I just can’t automate everything. I can’t get to a fully lights-out security stack because we always run into situations that need human analysis… Got to have both to get to a resilient solution.”
That’s the core insight. Automation scales routine work. Humans handle edge cases requiring judgment and organizational knowledge.
✅ The 2026 Standard: Hybrid Hunting
Demand these specifics from any AI SOC provider:
- Continuous cadence — Not quarterly. Continuous, 24/7 hypothesis generation and investigation.
- Documented playbooks — Every hunt follows a documented methodology with MITRE-mapped findings.
- Coverage mapped to YOUR threat landscape — Threat-specific hunting based on your industry, stack, and attack surface.
How UnderDefense Approaches Hunting
We run AI-driven hypothesis generation 24/7 across your entire stack, regardless of which tools you own. But the critical differentiator: our dedicated analysts know your organization. They understand your VIPs, odd-hours teams, authorized integrations, and environment-specific behaviors. When AI flags something, a human analyst with context makes the call. If they need more information, they reach out to the affected user directly via Slack or Teams.
Continuous hunting is included as standard with documented, MITRE-mapped findings reports, not a premium add-on or quarterly PDF. This is part of what makes our SOC as a service approach fundamentally different from providers that gate hunting behind enterprise-tier pricing.
“UnderDefense is surprisingly affordable considering the level of protection we get. Their proactive threat hunting and rapid response have saved us from incidents that could have been incredibly costly.”
— Verified User, Program Development UnderDefense G2 – Verified Review
“What we love most about UnderDefense is their proactive approach. Their experienced SOC engineers work closely with our team, providing continuous monitoring and threat detection.”
— Oleksii M., Mid-Market UnderDefense G2 – Verified Review
“There have been several instances where we expected RC to identify an issue and no alert was surfaced. Because of this, senior leadership feels, at times, that RC isn’t the right partner for us.”
— Mike S., Information Security Manager, VP Red Canary – G2 Verified Review
Q5. What Analyst Support Model Should Your AI SOC Include: Copilot, Virtual Analyst, or Concierge?
Here’s a decision most security leaders get wrong: they pick an AI SOC analyst support model based on the label, not the operational reality behind it. “AI analyst” could mean a chatbot that summarizes alerts, a virtual triage bot that auto-closes low-severity tickets, or a dedicated team that acts autonomously on your behalf 24/7. Choose wrong, and you either overpay for a glorified search bar or discover during a real incident that your “AI analyst” needs you to tell it what to do.
❌ The Wrong Way to Choose
The common mistake is selecting based on marketing language, such as “AI-powered analyst,” “virtual SOC analyst,” or “intelligent copilot,” without asking one critical question: when the alert fires at 2 AM, does this model require my team to do something, or does it handle it?
A copilot that needs prompting, interpreting, and manual action is fundamentally different from a concierge team that acts autonomously around the clock. One adds to your workload. The other removes it.
✅ The Right Framework: 5 Evaluation Criteria
Score each model against these five criteria. They separate real analyst support from re-packaged dashboards:
- Autonomy — Does the model operate independently, or does it require your team to prompt, interpret, and act on its outputs?
- Organizational Context — Does it know your users, VIPs, assets, and business rhythms, or does it treat every alert the same?
- Communication — Can it reach affected users directly via ChatOps (Slack, Teams, email), or does it only generate tickets?
- Response Authority — Can it contain threats (isolate endpoints, revoke credentials), or does it just recommend actions?
- Availability — Is it genuinely 24/7/365 with human backing, or business-hours-only with after-hours automation?
📊 Model Comparison Scorecard
| Criterion | Copilot | Virtual Analyst | Hybrid Staffing | Concierge |
|---|---|---|---|---|
| Autonomy | ❌ Needs prompting | ⚠️ Partial, follows rigid playbooks | ⚠️ Depends on staffing coverage | ✅ Acts independently 24/7 |
| Org Context | ❌ Generic | ❌ No org awareness | ⚠️ Limited to onboarded knowledge | ✅ Learns VIPs, assets, business context |
| Communication | ❌ Dashboard-only | ⚠️ Ticket-based | ⚠️ Email escalation | ✅ ChatOps: Slack, Teams, SMS direct to users |
| Response Authority | ❌ Recommend only | ⚠️ Basic containment | ⚠️ Varies by contract | ✅ Full containment and remediation |
| Availability | ⚠️ Business hours typical | ✅ 24/7 automated | ⚠️ Shift-dependent gaps | ✅ 24/7/365 human + AI |
For mid-market organizations without a 24/7 internal SOC, the concierge model consistently scores highest. It’s the only model where the system that detects the threat can also verify it with the affected user and contain it, without waking your team.
Where UnderDefense Scores
We built our managed detection and response around the concierge model because the other models kept failing the 2 AM test. Here’s what that looks like operationally:
- Tier 3–4 analyst access, not junior analysts reading from runbooks, but experienced IR professionals who understand your environment
- ChatOps verification, our analysts message your users directly through Slack, Teams, or email to confirm suspicious activity
- Full response authority, credential revocation, endpoint isolation, and lateral movement blocking, all executed on your behalf
- Org context retention, we learn your VIPs, your technical users, your critical assets, and your business rhythms during onboarding
- 24/7/365 coverage, with 2-minute alert-to-triage and 15-minute escalation SLAs for critical incidents
“UnderDefense act as an extension of our team, so we don’t need additional resources, ensuring 24/7 protection. It also solved our problem of having separate security tools that didn’t work well together.”
— Inga M., CEO UnderDefense – G2 Verified Review
“Their SOC team is responsive and knows their stuff. When they escalate something, they include the context we need to understand the issue quickly. We’re not wasting time piecing together what happened from different systems anymore.”
— Verified User in Marketing and Advertising UnderDefense – G2 Verified Review
“Despite the capabilities of the technical platform and the strength of the analysts providing the service, there is still a limit to the environmental/organizational knowledge inherent in the service. This leads to a fairly frequent need for engagement with our internal team to get clarification and verification.”
— Verified User in Computer Software, Mid-Market Expel – G2 Verified Review
The gap between “analyst support” and “concierge response” is the gap between getting an alert and getting an answer. Your AI SOC should deliver answers, not homework.
Q6. Can You Trust the AI’s Decisions? Explainability, Case Management, and Evidence Timelines
An AI SOC that can’t explain its reasoning is a liability, not an asset. I say this from experience. I’ve watched organizations deploy opaque detection systems that auto-closed thousands of alerts, only to discover during a post-incident review that the AI had been suppressing genuine threats because nobody could audit its logic. Explainability, auditability, and native case management are the governance triad that separates trustworthy AI SOC platforms from black-box alert engines.
How It Works: Three Pillars of Trust
1. Explainability
The AI must show its reasoning chain for every alert. Which telemetry signals triggered the detection? Which MITRE ATT&CK technique was mapped? What’s the confidence level? What action is recommended, and why? No black-box verdicts. If your AI says “this is malicious” but can’t show its work, you’re trusting a system you can’t verify, and your compliance team won’t accept that.
2. Auditability
Every decision, whether made by AI or a human analyst, needs an immutable log. Investigation records, analyst override decisions with rationale, and AI reasoning trails must be accessible for compliance audits (SOC 2, HIPAA, ISO 27001). When a regulator asks “why did you contain this user’s account at 3:14 AM?”, the answer can’t be “the AI said so.”
3. Native Case Management
Unified evidence timelines, with every alert, enrichment step, user verification, and response action linked in a single case view with timestamps. Not scattered across your SIEM, ticketing system, email threads, and a shared spreadsheet. Incident review shouldn’t be archaeology.
⚠️ What to Verify: Your Checklist
Before committing to any AI SOC platform, confirm these capabilities exist:
- ☐ AI provides natural-language explanation for every escalated alert
- ☐ Full investigation timeline accessible in one dashboard (not spreadsheets or multiple tools)
- ☐ Evidence packages auto-generated for compliance audits
- ☐ Analyst override decisions logged with rationale
- ☐ Case history searchable for pattern analysis across incidents
- ☐ MITRE ATT&CK technique mapping visible per detection
- ☐ Confidence scoring transparent and adjustable
Why This Matters Now
Regulatory scrutiny of AI-driven security decisions is accelerating. Without explainability, your legal and compliance teams cannot defend automated containment actions. Without native case management, incident review becomes a forensic dig through five different tools to reconstruct what happened.
Think of it as the difference between a doctor who says “take this pill” and one who explains the diagnosis, shows the test results, and documents the treatment plan. Your AI SOC should do the latter, every time.
How UnderDefense MAXI Delivers This
We built UnderDefense MAXI with transparency as a design principle, not an add-on. Every investigative step is observable and auditable. The AI shows which signals triggered a detection, maps the ATT&CK technique, provides confidence scoring, and documents the recommended action with justification. Human analyst decisions are logged alongside AI reasoning in a unified timeline. Compliance evidence packages are auto-generated as standard, not a premium module.
This matters because, as we’ve learned serving 500+ MDR clients, the organizations that trust their security operations are the ones that can see exactly what’s happening inside them. No proprietary magic. No hidden automation. No “trust me, it works.”
“It offers clear and actionable insights, allowing us to react promptly to any security issue. The platform’s interface is intuitive, making it easy even for non-techies to navigate. It’s clear they’ve focused on making a tool that gets straight to the point without unnecessary fluff.”
— Darina I., Customer Success Manager UnderDefense – G2 Verified Review
“I really like how straightforward UnderDefense’s dashboards are. It shows me all I need to know about my computer’s safety in a very simple way. Plus, it guides me on what to do if there’s a problem.”
— Alexey S., CEO UnderDefense – G2 Verified Review
Q7. How Broad Should AI SOC Integration Be, and What’s the Real Cost of Vendor Lock-In?
Picture this: you signed with an AI SOC provider 18 months ago. They promised “full-stack visibility.” Reality? You were forced to migrate your SIEM. Your CrowdStrike EDR feeds are flowing, but your Okta identity data “is on the roadmap.” Your AWS GuardDuty integration requires $15K in professional services. You’re paying for 100% coverage and seeing maybe 60% of your environment.
This isn’t hypothetical but the scenario we hear in nearly every first call with organizations switching providers.
🔍 Root Cause: Vendor Lock-In Creates Visibility Gaps
The problem isn’t that your provider can’t integrate but that they won’t, unless it serves their proprietary ecosystem. When an AI SOC vendor requires you to replace your SIEM or mandates their own agent stack, every tool outside that ecosystem becomes a blind spot. The hidden costs compound fast:
💸 $40–80K/year in professional services fees for “custom” integrations that should be standard
⏰ 3–6 month delays waiting for new tool support to appear on the vendor’s roadmap
❌ 15–30% of your environment invisible at any given time because integrations lag behind your actual stack
💰 Sunk cost trap, the longer you stay, the more business logic and detection rules you lose if you leave
✅ The Ideal State: Vendor-Agnostic by Design
What integration breadth should actually look like in a modern AI SOC:
| Category | Tools That Must Be Supported |
|---|---|
| SIEM | Splunk, Elastic, Microsoft Sentinel, QRadar |
| EDR | CrowdStrike, SentinelOne, Microsoft Defender, Carbon Black |
| IAM | Okta, Azure AD (Entra), Duo, JumpCloud |
| Cloud | AWS (GuardDuty, CloudTrail), GCP, Azure |
| ITSM | ServiceNow, Jira |
| Collaboration | Slack, Microsoft Teams (for ChatOps response) |
Non-negotiable requirements: 200+ out-of-the-box integrations, 30-day deployment, no per-connector fees, and integration included in base pricing, not sold as professional services.
How UnderDefense Solves This
We integrate with 250+ tools because that’s what vendor-agnostic actually means. No proprietary SIEM migration. No per-connector surcharges. No “on the roadmap” excuses. Your existing investments, CrowdStrike, Splunk, Elastic, SentinelOne, Microsoft Defender, and Okta, connect during a 30-day turnkey deployment. Your security data stays in your data lake, under your control.
From 60% visibility with lock-in to 100% stack coverage in 30 days: that’s the shift from renting a vendor’s ecosystem to owning your security architecture.
“We received little value from ArcticWolf. The product offered little visibility when we were using it… Anything you want to look at or changes you need to make in the product must go through their engineering team.”
— Matt C., Manager, Cybersecurity Services Arctic Wolf – G2 Verified Review
“The platform itself is straightforward – it pulls in data from all our existing security tools, so we didn’t have to rip and replace anything.”
— Verified User in Marketing and Advertising UnderDefense – G2 Verified Review
“Underdefense’s ease of integration into our existing tech stack mirrors the positive aspects, enhancing our security without disrupting workflow.”
— CEO, Mid-Market UnderDefense – G2 Verified Review
Q8. The Standard vs. Premium Trap: Which AI SOC Features Should Be Included, Not Charged Extra For?
Use this checklist to evaluate whether your AI SOC vendor includes essential capabilities as standard or hides them behind premium tiers, add-on modules, and professional services invoices. The difference between a transparent provider and an upsell machine often shows up after you’ve signed the contract.
✅ The Standard vs. ⚠️ Premium Audit
| Category | Capability | Should Be Standard? | Often Charged Extra? |
|---|---|---|---|
| Detection | 24/7 monitoring | ✅ Yes | |
| MITRE ATT&CK sub-technique mapping | ✅ Yes | ⚠️ Frequently upsold | |
| Custom detection rules | ✅ Yes | ⚠️ “Professional services” fee | |
| Automation | Alert triage and enrichment | ✅ Yes | |
| Auto-containment (endpoint isolation, credential revocation) | ✅ Yes | ⚠️ “Advanced response” tier | |
| Compliance evidence generation | ✅ Yes | ⚠️ Separate compliance module | |
| Response | Full investigation | ✅ Yes | |
| ChatOps user verification (Slack/Teams/email) | ✅ Yes | ⚠️ Rarely included anywhere | |
| Full remediation (not just recommendations) | ✅ Yes | ⚠️ “Incident response” add-on | |
| Hunting | Continuous proactive threat hunting | ✅ Yes | ⚠️ Premium tier at most providers |
| Documented threat hunting reports | ✅ Yes | ⚠️ Extra fee | |
| Integration | Core connectors (SIEM, EDR, Cloud, IAM) | ✅ Yes | |
| Custom API integrations | ✅ Yes | ⚠️ Per-connector pricing | |
| Analyst Access | Tier 1–2 analyst support | ✅ Yes | |
| Dedicated Tier 3–4 analysts | ✅ Yes | ⚠️ “Concierge” premium | |
| Direct Slack/Teams communication | ✅ Yes | ⚠️ Enterprise-only feature |
How to Read Your Score
Count how many items your current or prospective vendor charges extra for in the ⚠️ column:
- 0–2 items upsold → You found a transparent provider. Validate their claims during a proof-of-value.
- 3–5 items upsold → Significant hidden costs ahead. Calculate your true total cost of ownership before signing.
- 5+ items upsold → You’re buying an incomplete platform. The “base price” is a teaser, and your actual spend will be 40–60% higher than quoted.
💰 What UnderDefense Includes as Standard
Every capability in the table above, including threat hunting, MITRE sub-technique mapping, ChatOps user verification, Tier 3–4 dedicated analyst access, compliance automation, 250+ integrations, and full containment and remediation, is included at $11–15/endpoint/month. No hidden modules. No “contact sales for advanced features.” No surprise professional services invoices.
The philosophy is simple: if a capability is essential to stopping a breach, it shouldn’t be a paid add-on. We learned this from customers who came to us after discovering that their previous vendor’s “MDR” was actually MDR-lite, with response, hunting, and compliance all sold separately.
“UnderDefense is surprisingly affordable considering the level of protection we get. Their proactive threat hunting and rapid response have saved us from incidents that could have been incredibly costly.”
— Verified User in Program Development UnderDefense – G2 Verified Review
“It’s reassuring to know they’re always watching for threats, and it doesn’t cost a fortune. They catch and stop problems quickly, which is a huge relief.”
— Serhii B., CISO UnderDefense – G2 Verified Review
“Arctic Wolf provides solid detection and response capabilities, but overly relies on the client’s team for remediation, which really hurts the value of the service.”
— VP of Technology Arctic Wolf – Gartner Verified Review
If your vendor charges extra for five or more capabilities on this list, you’re not buying managed detection and response. You’re buying a monitoring dashboard with an expensive upgrade path. The right AI SOC bundles everything your security team needs at a price you can predict, because surprise costs during an active incident are the last thing anyone needs.
Q9. What KPIs, SLAs, and Contractual Language Should You Demand From Your AI SOC Provider?
If you can’t measure it, you can’t hold anyone accountable for it. That’s the reality I see over and over: security teams sign contracts with MDR or AI SOC vendors, and six months later they have no idea whether they’re actually getting faster detection, fewer false positives, or better coverage than they had before.
⏰ 7 Essential AI SOC KPIs With 2026 Benchmarks
Every AI SOC contract should be anchored to specific, measurable KPIs. Here’s what to benchmark against in 2026:
- Mean Time to Detect (MTTD): ≤10 minutes for critical threats. If your provider takes longer, their AI is either noisy or undertrained.
- Mean Time to Respond (MTTR): ≤30 minutes for critical incidents. This includes containment actions, not just acknowledgment.
- False Positive Rate: ≤5% of escalated alerts. If more than 1 in 20 escalations wastes your team’s time, the detection layer isn’t working.
- Alert-to-Incident Ratio: ≥50:1 compression. A proper AI SOC should collapse thousands of raw signals into a handful of actionable incidents daily.
- MITRE ATT&CK Coverage: ≥85% technique-level, ≥60% sub-technique-level. Anything less means blind spots in your detection matrix.
- Analyst Alert Reduction: ≥95%. Your team’s time should go to strategy, not triage.
- Hunting Cadence: Continuous, not quarterly. Threat hunting scheduled every 90 days is theater, not security.
One more metric worth tracking: analyst hours saved per month. It ties directly to ROI and gives your CFO a number they can compare against the cost of full-time hires.
📝 SLA Clause Recommendations for Your MSA
KPIs matter only if your contract enforces them. Here’s what to demand in your Master Service Agreement:
- Documented MTTR guarantees with financial penalties for misses, not aspirational targets buried in marketing PDFs.
- Coverage uptime ≥99.9% for 24/7 monitoring. Downtime in a SOC isn’t an inconvenience but exposure.
- Defined escalation paths: who gets notified, within what timeframe, and through which channel.
- Quarterly MITRE ATT&CK reporting showing exactly which techniques are covered and which are not.
- Right-to-audit clauses so your team can verify detection logic, alert workflows, and analyst actions.
- Analyst hours saved reporting, monthly, with trended data.
- Exit clause protections: data portability guarantees, transition timeline commitments, and no lock-in penalties.
📊 Vendor SLA Transparency Comparison
| SLA Element | UnderDefense | Arctic Wolf | CrowdStrike Falcon Complete | Expel | ReliaQuest |
|---|---|---|---|---|---|
| Published MTTR | ✅ 2-min alert-to-triage, 15-min critical escalation | ❌ Not published | ❌ Not published | ⚠️ Partial | ❌ Not published |
| MITRE Coverage Reported | ✅ 96% documented | ❌ Contact sales | ⚠️ General claims | ⚠️ Partial | ❌ Contact sales |
| Noise Reduction SLA | ✅ 99% | ❌ Not published | ❌ Not published | ❌ Not published | ❌ Not published |
| Pricing Transparency | ✅ $11–15/endpoint/mo | ❌ $96K median/yr | ❌ Contact sales | ⚠️ Partial | ❌ Contact sales |
| Contractual Penalties | ✅ Included | ❌ Not standard | ❌ Not standard | ❌ Not standard | ❌ Not standard |
| Exit / Data Portability | ✅ Guaranteed | ❌ Proprietary lock | ⚠️ Limited | ⚠️ Limited | ❌ Proprietary lock |
✅ How UnderDefense Simplifies This
We publish our SLAs: 2-minute alert-to-triage, 15-minute escalation for critical incidents, 96% MITRE ATT&CK coverage, and 99% noise reduction, all backed with contractual guarantees, not marketing claims. Exit clauses, data portability, and quarterly coverage reporting come standard. If a vendor won’t put their numbers in writing, ask yourself why.
Q10. How Should You Score Vendors? A Weighted Evaluation Framework + Complete AI SOC Demand Checklist
You’ve read the checklist. You know what to look for. Now the hard part: how do you score five vendors consistently when every sales deck claims “AI-driven,” “24/7,” and “industry-leading”? Generic RFP templates don’t cut it for AI SOC evaluations because they measure checkbox features, not operational capability.
❌ The Wrong Way to Decide
Most security leaders fall into one of three traps: picking the brand with the biggest marketing budget, choosing whoever supports the most integrations on paper, or relying on analyst quadrant placement. None of these measure what matters, which is whether the provider can detect, verify, and contain threats faster than your team can alone.
✅ The Right Evaluation Framework
Score each vendor across six categories, weighted by operational impact. Use a 0–3 scale for each (0 = absent, 1 = basic, 2 = strong, 3 = exceptional). Total possible: 18 points.
| Category | Weight | What to Measure (Score 0–3) |
|---|---|---|
| Detection Depth | 20% | MITRE technique + sub-technique coverage; behavioral + correlation-based detection |
| Automation Maturity | 20% | Agentic triage, auto-enrichment, detection-as-code, and Level 3–4 automation |
| Threat Hunting | 15% | Continuous vs. scheduled; proactive hypothesis-driven hunts; documented cadence |
| Analyst Support | 15% | Direct Tier 3–4 access; concierge model vs. ticket escalation; ChatOps verification |
| Integration Breadth | 15% | Vendor-agnostic coverage; number of supported tools; SIEM/data ownership preserved |
| Pricing & SLA Transparency | 15% | Published pricing; documented MTTR/MTTD; contractual guarantees with penalties |
📋 Master Checklist: 30 Items by Category
DETECTION (6 items): Behavioral analytics, correlation engine, MITRE sub-technique mapping, detection-as-code support, custom rule creation, and false-positive feedback loop.
AUTOMATION (5 items): Agentic AI triage, auto-enrichment with context, automated containment playbooks, user verification automation, and evidence timeline generation.
HUNTING (4 items): Continuous hunting cadence, hypothesis-driven methodology, threat intel integration, and documented hunting reports with findings.
ANALYST (5 items): Direct Tier 3–4 access, ChatOps user verification, concierge team with organizational context, named analyst assignment, and 24/7 human escalation path.
INTEGRATION (5 items): 200+ tool support, SIEM agnosticism, cloud-native connectors (AWS/Azure/GCP), identity provider integration, and data ownership preservation.
PRICING/SLAs (5 items): Published per-endpoint pricing, documented MTTR guarantees, contractual penalties, exit clause protections, and quarterly reporting commitments.
🎯 Scoring Interpretation
- 15–18 points: Enterprise-grade AI SOC. Proceed with confidence.
- 10–14 points: Significant gaps. Negotiate hard or reconsider.
- Below 10 points: You’re buying a monitoring tool, not an AI SOC.
⭐ UnderDefense Score: 17/18
| Category | Score | Justification |
|---|---|---|
| Detection Depth | 3 | 96% MITRE coverage, detection-as-code, behavioral + correlation |
| Automation Maturity | 3 | Agentic AI triage, 2-min alert-to-triage, and auto-enrichment |
| Threat Hunting | 3 | Continuous hunting, documented case studies (Black Basta stopped in minutes) |
| Analyst Support | 3 | Direct concierge analysts, ChatOps user verification via Slack/Teams |
| Integration Breadth | 3 | 250+ tools, SIEM-agnostic, preserves customer data ownership |
| Pricing & SLA Transparency | 2 | Published $11–15/endpoint/mo; contractual MTTR guarantees |
Request a scored side-by-side evaluation vs. your current provider, or download the scoring template to run it yourself.
Q11. Which SOC Providers Actually Deliver These Features? See the Full Comparison
The AI SOC providers most consistently meeting the criteria outlined in this checklist include UnderDefense, Intezer, Torq, Radiant Security, and Prophet Security, each with distinct architectural approaches, pricing models, and automation maturity levels.
🔍 What Separates the Leaders
The difference between “AI SOC” marketing and operational reality comes down to four dimensions:
- Integration flexibility: Vendor-agnostic platforms that preserve your SIEM and data ownership vs. proprietary stacks that force rip-and-replace.
- Automation maturity: Level 2 automation (enrichment-only) vs. Level 3–4 (agentic triage, containment, and user verification).
- Analyst support model: AI copilot assisting your team vs. concierge analysts who own outcomes and communicate directly with affected users.
- Pricing transparency: Published per-endpoint rates vs. “contact sales” opacity.
🔗 Finding the Right Fit
Each provider excels in different scenarios. The right choice depends on your current stack, team maturity, and operational priorities. For a complete ranked comparison with pricing, response times, and integration capabilities, see the full breakdown below.
This analysis is based on documented response times, G2 reviews, published pricing, and operational outcomes across 500+ MDR deployments.
1. What are the must-have features for an AI SOC platform in 2026?
We’ve identified 30 essential capabilities across six categories that every AI SOC should deliver as standard in 2026. These include behavioral analytics with MITRE ATT&CK sub-technique mapping, Level 3–4 automation maturity (agentic triage, auto-enrichment, and automated containment), continuous 24/7 threat hunting with documented playbooks, concierge-model analyst support with direct ChatOps verification, vendor-agnostic integration across 200+ tools, and published SLAs with contractual penalties.
The critical distinction: most vendors deliver only a subset of these at their base tier and gate the rest behind premium modules. When we built the UnderDefense MAXI platform, we included all 30 items as standard because incomplete coverage creates the exact blind spots attackers exploit. Your evaluation should score vendors across all six categories using a weighted framework, not just count features on a marketing page.
2. How do you measure MITRE ATT&CK coverage beyond a vendor's percentage claim?
A vendor claiming “95% MITRE ATT&CK coverage” is meaningless without context. The real question is whether that covers techniques only (approximately 200–250) or sub-techniques (400–700+). We recommend a 5-point scoring framework: demand ≥85% technique-level AND ≥60% sub-technique-level coverage for your top-5 risk tactics, require detection confidence scoring (high/medium/low) on every alert, request a real-time detection heat map, verify custom detection rules beyond out-of-box defaults, and confirm detection drift monitoring is automated rather than a point-in-time snapshot.
At UnderDefense, we deliver 96% MITRE ATT&CK technique coverage with sub-technique mapping across all 14 tactics, accessible in your dashboard from day one of the 30-day onboarding. If your vendor can’t break down coverage by tactic or show a live heat map, that’s a red flag.
3. What automation levels should an AI SOC operate at, and where do humans stay in the loop?
We use a 5-level AI SOC automation maturity model. Level 0 is fully manual. Level 1 is AI-assisted enrichment. Level 2 is semi-autonomous with human approval. Level 3 is autonomous containment for low/medium severity threats. Level 4 is predictive hunting based on behavioral anomalies.
For 2026, we recommend demanding Level 2–3 minimum across all core SOC tasks, with specific actions that should never be fully autonomous: production system shutdowns, legal/regulatory notifications, cross-environment containment, and VIP account actions. These guardrails should be defined contractually.
Our UnderDefense MAXI platform operates at Level 3 for triage, phishing, and endpoint containment, with Level 4 predictive hunting running continuously and human-in-the-loop guardrails for all high-impact actions.
4. Should AI SOC threat hunting be continuous or scheduled, and when do you still need human analysts?
Threat hunting in 2026 splits into three models: human-led (deep but slow), AI-assisted (scalable with contextual judgment), and fully autonomous (fast but misses organizational context). We advocate for AI-assisted hybrid hunting, where AI generates hypotheses 24/7 from behavioral anomalies and ATT&CK patterns, and human analysts investigate, validate, and apply business context.
Fully autonomous hunting fails when threats require organizational knowledge, such as distinguishing a late-night project deadline from data exfiltration, or identifying supply chain compromises that mimic authorized updates. Demand continuous cadence, documented MITRE-mapped playbooks, and coverage mapped to your specific threat landscape.
We include continuous threat hunting as standard with documented findings reports, not a premium add-on or quarterly PDF.
5. What is the difference between a copilot, virtual analyst, and concierge analyst support model?
These three models differ across five critical criteria: autonomy, organizational context, communication capability, response authority, and 24/7 availability.
A copilot needs prompting and only recommends actions. A virtual analyst follows rigid playbooks with partial autonomy. A concierge model acts independently 24/7, learns your VIPs and business rhythms, communicates directly with affected users via ChatOps, and executes full containment and remediation.
For mid-market organizations without a 24/7 internal SOC, the concierge model consistently scores highest because it’s the only model where the system that detects the threat can also verify it with the affected user and contain it without waking your team. We built our SOC as a service around this model with Tier 3–4 analyst access, 2-minute alert-to-triage, and 15-minute escalation SLAs for critical incidents.
6. How do you avoid vendor lock-in when choosing an AI SOC provider?
Vendor lock-in happens when your AI SOC provider forces proprietary SIEM migration, charges per-connector fees for integrations, or holds your detection rules hostage if you leave. The hidden costs compound quickly: $40–80K/year in professional services for “custom” integrations, 3–6 month delays for new tool support, and 15–30% of your environment invisible at any given time.
We recommend demanding vendor-agnostic design as non-negotiable: 200+ out-of-the-box integrations, 30-day deployment, no per-connector fees, data ownership preservation, and exit clause protections in your contract. Your security data should stay in your data lake, under your control.
At UnderDefense, we integrate with 250+ tools, including CrowdStrike, Splunk, Elastic, SentinelOne, Microsoft Defender, and Okta, during a 30-day turnkey deployment with no proprietary SIEM migration required.
7. What KPIs and SLA clauses should be in an AI SOC contract?
We recommend anchoring every AI SOC contract to seven essential KPIs with 2026 benchmarks: MTTD ≤10 minutes, MTTR ≤30 minutes (including containment), false positive rate ≤5%, alert-to-incident ratio ≥50:1, MITRE ATT&CK coverage ≥85% technique-level, analyst alert reduction ≥95%, and continuous hunting cadence.
Your Master Service Agreement should include documented MTTR guarantees with financial penalties, ≥99.9% monitoring uptime, defined escalation paths, quarterly MITRE coverage reports, right-to-audit clauses, and exit clause protections with data portability guarantees.
We publish our SOC metrics and SLAs openly: 2-minute alert-to-triage, 15-minute critical escalation, 96% MITRE coverage, and 99% noise reduction, all backed by contractual guarantees rather than marketing claims.
8. Which AI SOC features should be included as standard, not charged as premium add-ons?
We’ve identified 17 capabilities that should be standard in any AI SOC contract. The most commonly upsold features include MITRE ATT&CK sub-technique mapping, custom detection rules, auto-containment, compliance evidence generation, ChatOps user verification, full remediation, continuous threat hunting, documented hunting reports, custom API integrations, dedicated Tier 3–4 analysts, and direct Slack/Teams communication.
If your vendor charges extra for 5 or more of these, you’re buying a monitoring dashboard with an expensive upgrade path, not managed detection and response. Use our scoring method: 0–2 items upsold means a transparent provider, 3–5 means significant hidden costs, and 5+ means your actual spend will be 40–60% higher than quoted.
Every one of these capabilities is included in our MDR pricing at $11–15/endpoint/month, with no hidden modules or surprise professional services invoices.
The post What Features Should AI SOC Have in 2026? A Complete Checklist appeared first on UnderDefense.