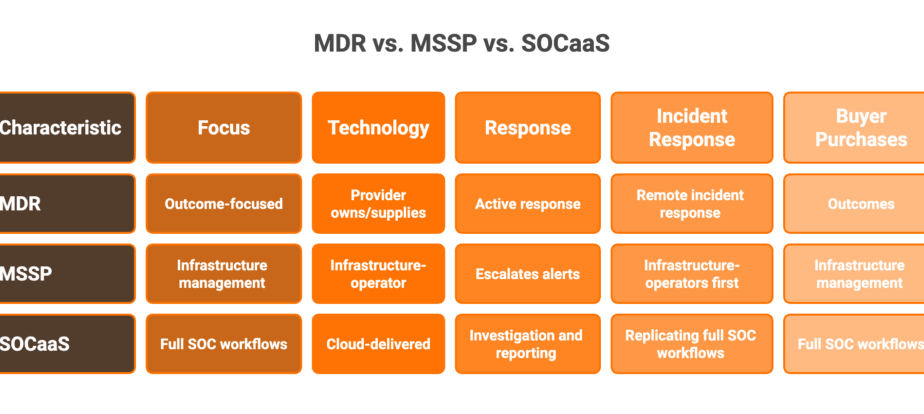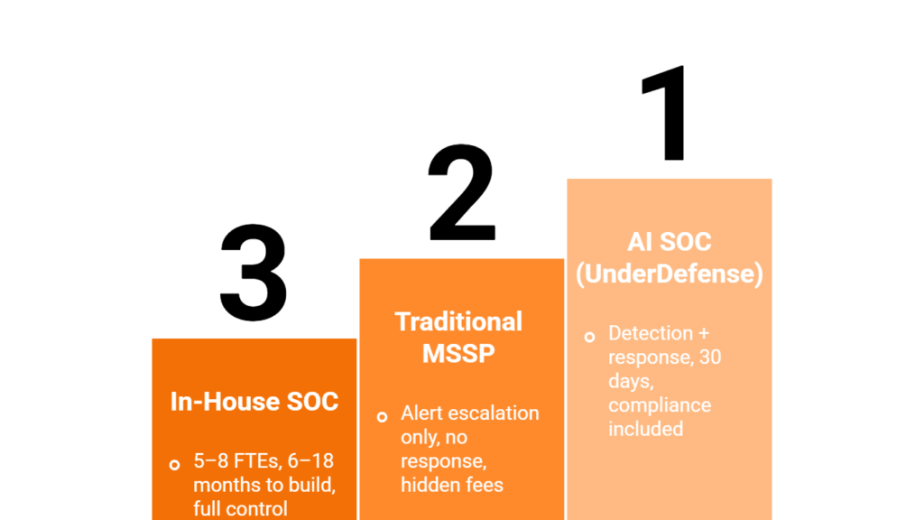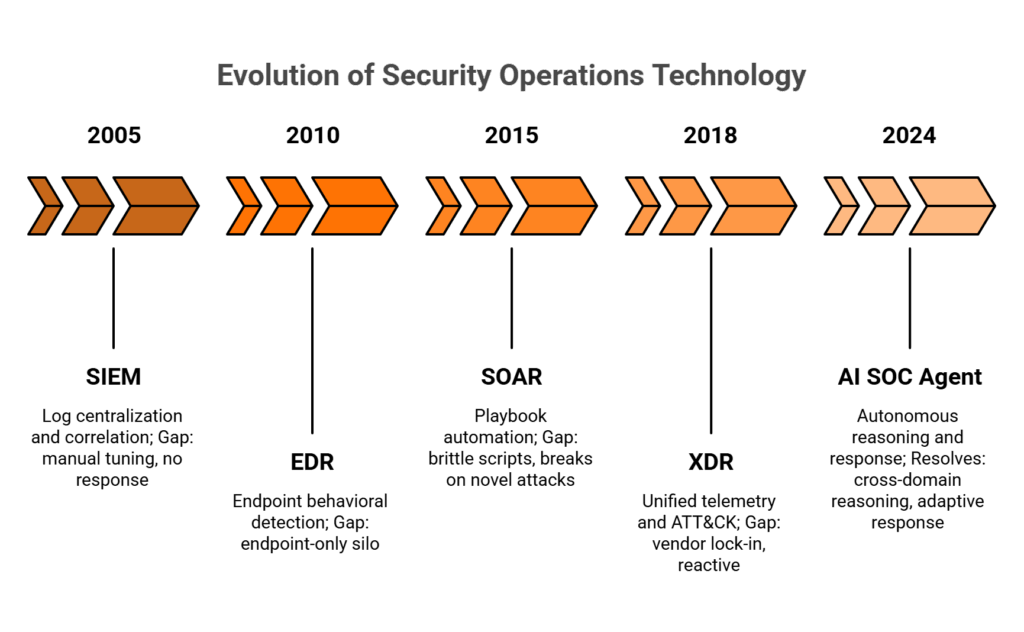
Q1: What Is an AI SOC Agent, and How Does It Differ from a Chatbot, Co-Pilot, SOAR, or SIEM?
Here’s the operational reality most security leaders live with: 40 to 70 security tools generating thousands of daily alerts, yet no single system that reasons across them. CrowdStrike for endpoints, Splunk for logs, Okta for identity, cloud-native consoles for infrastructure, all creating alert volume without understanding. Organizations don’t lack detection; they lack synthesis. And that gap is where incidents slip through at 2 AM while your team sleeps.
⚠️ The Taxonomy Confusion Is Costing You Time
The market has flooded you with terms, including chatbot, co-pilot, SOAR, SIEM, and XDR, and most vendors deliberately blur the lines. Let me cut through it with a clear framework:
| Capability | AI SOC Agent | Chatbot | Co-Pilot | SOAR | SIEM |
|---|---|---|---|---|---|
| Autonomy Level | High, acts independently within guardrails | None, responds to prompts | Low, suggests, human executes | Medium, runs pre-built playbooks | None, aggregates and correlates |
| Reasoning Type | Dynamic, hypothesis-driven (LLM-powered) | Pattern-matched Q&A | Contextual suggestions | Static if-then logic | Rule-based correlation |
| Action Capability | Investigates, decides, and executes response | Answers questions about alerts | Recommends next steps | Executes pre-defined playbooks | Fires alerts based on rules |
| Adaptability | Learns from analyst feedback and org context | Limited to training data | Moderate | Brittle, breaks when attacks deviate | Requires manual rule tuning |
A chatbot answers questions about alerts; it doesn’t investigate them. A co-pilot suggests next steps for a human to execute, while an agent acts autonomously. SOAR runs static if-then playbooks that break the moment an attack deviates from the script. SIEM aggregates logs and correlates rules, but it doesn’t formulate hypotheses across sources.
🔍 Detection Without Response Is Noise
An AI SOC agent is an LLM-powered autonomous system that can: (1) perceive security telemetry from multiple sources, (2) reason across data to formulate investigation hypotheses, (3) decide on investigation and response paths, and (4) execute actions, not via static playbooks, but via learned reasoning with organizational context. The key insight is straightforward: detection without response is noise, and response without context is risk.
Traditional MDR providers like Arctic Wolf see alerts but force proprietary tool replacement. Endpoint-focused providers like CrowdStrike see threats but miss organizational context and user verification. One Gartner reviewer noted about Arctic Wolf:
“This is not an extension of our security team as was originally sold. Some alerts are just a regurgitation of Microsoft alerts which means duplicates.”
— Sr. Cybersecurity Engineer, Manufacturing Arctic Wolf – Gartner Verified Review
✅ The AI SOC + Human Ally Model
This is where we built UnderDefense differently. The UnderDefense MAXI platform integrates vendor-agnostically with 250+ tools, drives AI-powered triage and enrichment, and pairs it with concierge analyst response that verifies suspicious activity directly with affected users via Slack or Teams. We don’t replace your stack; we make it operationally effective.
While traditional MDR tells you “suspicious login detected, please investigate,” UnderDefense tells you who logged in, confirms with the user directly, and contains the threat before your team wakes up. That’s the difference between an alert factory and an outcome-driven security operation.
Q2: Why Are AI SOC Agents Emerging Now? The SOC Crisis and Market Momentum
AI SOC agents are emerging because three forces converged simultaneously: SOC teams are breaking under alert volume they cannot physically process, LLM technology matured enough to reason about security data, and the market validated the category with Gartner recognition and significant investment.
⏰ The SOC Is Breaking, and the Numbers Prove It
Alert overload: SOC teams process an average of 960 alerts per day, with large enterprises handling over 3,000 daily alerts from 30+ tools. Forty percent go uninvestigated. A 2026 Forbes report puts the figure even higher: 4,330 alerts daily with fewer than half investigated.
Analyst burnout: 77% of organizations report increased alert volume year-over-year, and 76% cite alert fatigue as their top challenge. Staffing shortages follow closely at 73%. The SANS 2025 survey confirms “very frequent” false positives jumped from 13% to 20% year-over-year.
Talent gap: The global cybersecurity workforce gap reached 4.8 million unfilled positions (ISC² 2025), and the workforce needs to grow 87% to satisfy current demand. Staffing a 24/7 SOC internally exceeds $1M/year, and that’s before accounting for training pipelines, career progression, and turnover.
Technology maturity + market recognition: Gartner placed AI SOC agents on the Hype Cycle for Security Operations in 2025, positioning them at the “Peak of Inflated Expectations” with 1–5% market penetration, signaling early-mover advantage. Agentic frameworks now enable agents to interact with 90+ security tools natively.
💡 Why This Matters for Decision-Makers
As a practitioner, I’ve seen the pattern repeat across organizations of every size: you can’t scale with humans alone, and you can’t automate everything. The math simply doesn’t work. You need a system that handles the mechanical investigation steps at machine speed while humans focus on judgment calls that require business context.
✅ Built for This Convergence
We anticipated this at UnderDefense. The UnderDefense MAXI platform was built as an AI SOC + Human Ally from inception, not a legacy tool with AI bolted on. The AI automates context collection, queries your SIEM, pulls logs, enriches with threat intelligence, and correlates across systems. The human analysts handle what AI still can’t: understanding intent, validating with affected users, and making business-risk decisions. Result: 99% alert noise reduction and 2-minute alert-to-triage from day one.
Q3: How Did We Get Here? The SIEM → EDR → SOAR → XDR → AI SOC Evolution
Every generation of security technology solved a real problem and left a new gap behind. Understanding this evolution isn’t academic; it determines whether your next investment compounds value or adds another silo to manage.
📌 Gen 1–2: SIEM + EDR (2005–2015)
SIEMs solved log centralization and correlation, giving security teams a single pane of glass for the first time. But they created massive data volumes, constant tuning requirements, rule-based detection that missed novel attacks, and zero native response capability. You could see what happened, but you couldn’t act on it without manual intervention.
EDR added endpoint visibility and behavioral detection, a genuine leap forward. But it created another silo: endpoint-only context with no identity, cloud, or network reasoning. If your attacker pivoted from a compromised endpoint to an OAuth token abuse, your EDR had no idea.
📌 Gen 3–4: SOAR + XDR (2015–2023)
SOAR promised playbook automation, but here’s the operational reality: playbooks are brittle. They break the moment an attack deviates from the script. XDR unified endpoint, network, and cloud telemetry with MITRE ATT&CK mapping and native response, but remained reactive with pre-defined logic, static correlation, and vendors who locked customers into proprietary ecosystems.
| Generation | Core Innovation | Persistent Limitation | What AI SOC Agents Resolve |
|---|---|---|---|
| SIEM (2005+) | Log centralization + correlation | Massive data volumes, manual tuning, no response | Autonomous reasoning across all log sources |
| EDR (2010+) | Endpoint behavioral detection | Endpoint-only context, siloed visibility | Cross-domain correlation (identity, cloud, network) |
| SOAR (2015+) | Playbook automation | Brittle scripts, break on novel attacks | Adaptive reasoning that formulates hypotheses dynamically |
| XDR (2018+) | Unified telemetry + ATT&CK mapping | Vendor lock-in, static correlation, reactive | Vendor-agnostic integration + proactive response |
| AI SOC Agent (2024+) | Autonomous reasoning + response | Early maturity, guardrails needed | Human-in-the-loop validation with machine-speed investigation |
As one CISO noted about the vendor lock-in problem in an Arctic Wolf Gartner review:
“Log collectors show working, however when asked to provide logs for an investigation no logs could be provided. Analysts provide little context, and when asked for more information nothing is ever provided.”
— CISO, Manufacturing Arctic Wolf – Gartner Verified Review
🔄 Gen 5: The AI-Era Transformation (2024–Present)
The fundamental shift is from “detect and alert” to “perceive, reason, and act.” LLM-powered agents formulate investigation hypotheses across multi-domain telemetry, execute response autonomously, and adapt based on organizational context. SIEM isn’t dead; it’s evolving into a cloud-native control layer on top of a security data lake.
✅ Where UnderDefense Sits
We built for Gen 5 from the ground up, not a SIEM vendor bolting on AI, not an XDR vendor adding chatbots. UnderDefense MAXI integrates with 250+ tools across all five generations and adds the reasoning plus response layer on top. Vendor-agnostic by design, it protects your Gen 1–4 investments while adding Gen 5 intelligence. As we tell every prospect: your business logic, your correlation rules, your data should stay with you, not locked inside a vendor’s proprietary system.
Q4: How Do AI SOC Agents Work? Agentic Architecture, Multi-Agent Orchestration, and Reasoning Models
Understanding the architecture behind AI SOC agents isn’t optional for security leaders evaluating these systems; it’s how you distinguish vendors who built genuine agentic capabilities from those who bolted a chatbot onto a dashboard and called it “AI-powered.”
🔍 The 5-Step Investigation Cycle
Every AI SOC agent follows a variation of this cycle, though the quality of execution varies dramatically:
- INGEST — Normalize telemetry from SIEM, EDR, identity, cloud, email, and network sources into a unified data model. Without normalization, reasoning across sources is impossible.
- ENRICH — Augment raw alerts with threat intelligence, asset context, and user behavior baselines via RAG (Retrieval-Augmented Generation). This is where organizational context enters the picture.
- INVESTIGATE — The LLM-based reasoning engine formulates hypotheses, selects investigation paths, and queries additional sources using tool-use (function calling) APIs. This is the step that separates agents from playbooks.
- DECIDE — Determine severity, required actions, and whether human approval is needed based on policy engine thresholds.
- ADAPT — Update baselines, learn from analyst feedback, and refine detection models. Without this loop, you have a static system with an LLM wrapper.
🧩 Multi-Agent Orchestration Patterns
Complex attacks span multiple domains; no single agent has full context. Three orchestration patterns dominate production deployments:
Supervisor-Worker: A meta-orchestrator routes tasks to domain-specific agents (triage, identity, endpoint, cloud, and response). Best for structured, high-volume environments.
Peer-to-Peer: Agents communicate directly. The endpoint agent tasks the identity agent to check OAuth anomalies. Faster, but requires robust conflict resolution (what happens when one agent isolates an endpoint while another still investigates?).
Hierarchical: Tiered agents with escalation: L1 triage → L2 investigation → L3 response. Mirrors traditional SOC structure, making it intuitive for teams transitioning from manual operations.
⚖️ Reasoning Model Spectrum
| Approach | Strengths | Limitations | Best For |
|---|---|---|---|
| Pure LLM | Flexible reasoning, handles novel attacks | Hallucination risk, expensive compute | Research, hypothesis generation |
| Pure Deterministic | Fast, predictable, auditable | Brittle against novel attacks | Known-threat playbooks |
| Hybrid (Dominant) | LLM reasoning + deterministic guardrails | Higher complexity to build | Enterprise production deployments |
Most production AI SOC agents use hybrid approaches: LLM for reasoning, deterministic guardrails for action validation. Domain-specific language models (DSLMs) fine-tuned on security data offer better precision than general-purpose LLMs, though they require significant training investment.
🛡️ Guardrails and Human-in-the-Loop Design
Tiered autonomy is non-negotiable: auto-close false positives, but escalate containment above severity thresholds. Every decision must produce an auditable reasoning chain. If your AI SOC can’t show its work, you have a black box with extra steps. Memory systems split into short-term (investigation context) and long-term (organizational baselines), ensuring the agent gets smarter about your environment over time.
✅ How UnderDefense MAXI Embeds This Architecture
UnderDefense MAXI embeds this architecture natively, connecting all telemetry into a single context-aware layer with built-in guardrails and human oversight. The concierge analyst model ensures no high-impact action occurs without human validation. We call it supervised autonomy: the AI collects context and accelerates investigation at machine speed, but humans make the final call on decisions that matter. No blind automation, no black boxes, only observable workflows you can audit and reproduce.
Q5: What Are the Core Capabilities of AI SOC Agents, and What Do They Look Like in Practice?
It’s 2:47 AM on a Tuesday. Your phone buzzes with the 14th critical alert this week. You log in, spend 45 minutes investigating, and discover it’s another false positive: a developer running a legitimate PowerShell script. You’ve been awake for an hour. You still don’t know if you missed something real.
This scenario plays out in thousands of SOCs every night. The problem isn’t that security tools don’t detect; nobody can act fast enough on what matters. Here are the six core capabilities that separate a real AI SOC agent from another dashboard:
📌 Core Capabilities Reference
| # | Capability | What It Does | What It Replaces |
|---|---|---|---|
| 1 | Automated Alert Triage + False Positive Suppression | Correlates across all sources, verifies with users, auto-closes noise | Manual L1 analyst triage (10–15 hrs/week) |
| 2 | Autonomous Investigation + Cross-Source Correlation | Multi-domain hypothesis testing, 45–61% faster than manual (CSA benchmark) | Analyst copy-pasting between 5 consoles |
| 3 | Proactive Threat Hunting + Anomaly Detection | Continuous hunting without waiting for alerts to fire | Quarterly threat hunts that miss real-time threats |
| 4 | MITRE ATT&CK Mapping + Attack Path Construction | Auto-maps observed TTPs to kill chain stages | Manual spreadsheet mapping post-incident |
| 5 | Self-Adapting Response Workflows | Containment actions adjust based on investigation findings | Static SOAR playbooks that break on novel attacks |
| 6 | Automated Documentation + Compliance Reporting | Incident reports and audit evidence generated automatically | Analyst writing reports at 4 AM |
⚠️ Scenario A: Fileless Attack at 2 AM
A fileless living-off-the-land (LOTL) attack uses legitimate PowerShell and WMI to evade signature detection. Traditional tools see isolated events and generate 47 separate alerts. The AI SOC agent correlates process chains across EDR, identity, and network telemetry, recognizes LOTL techniques via ATT&CK (T1059, T1047), and constructs the full attack path in minutes, not hours.
⏰ Scenario B: OAuth Token Abuse During the Shift Gap
At 1 AM during the US-EU shift gap, an OAuth token abuse from a finance account goes undetected. No one investigates until morning, and dwell time expands by hours. An AI SOC agent queries the identity provider, checks email for phishing indicators, cross-references cloud logs, and verifies with the user via Slack. Contained in minutes, not the next business day.
✅ How This Looks in Practice at UnderDefense
UnderDefense MAXI resolves all these scenarios daily. Our concierge analysts validate AI-driven containment, communicate directly with affected users, and deliver complete incident reports by morning. The result: 100% ransomware prevention record across 500+ MDR clients over 6 years.
“Not having to worry about ransomware, alert overload and reporting. Getting a clear view of my security posture, where the threats are coming from and how they are handled. They literally took care of all our problems.”
— Arlin O., Enterprise UnderDefense – G2 Verified Review
“The biggest win for me was getting actual control over our security alerts. Before the guys from UD stepped in, we were getting bombarded with alerts from all our security tools. Their team cleaned up our configurations and got the noise under control within the first week.”
— Verified User, Marketing and Advertising UnderDefense – G2 Verified Review
Q6: What Is the Strategic Impact? Workforce Augmentation, SOC Transformation, and Analyst Evolution
AI SOC agents don’t eliminate analyst jobs; they eliminate the work that makes analysts quit. The strategic impact is a fundamental transformation from tiered alert escalation (L1 screens → L2 investigates → L3 hunts) to skill-based collaboration where every analyst operates at L3+ because AI handles the L1–L2 workload.
🔑 Four Measurable Impacts
Workforce augmentation: AI handles 80–90% of L1 triage: automated context collection, log queries, threat intel enrichment, and cross-system correlation at machine speed. Analysts focus on complex investigations, threat hunting, and security architecture.
SOC model transformation: The traditional L1/L2/L3 pyramid flattens to a skill-based model. Detection engineers, threat hunters, incident commanders, and policy architects replace alert triagers. This isn’t theory but operational reality at organizations that adopt AI SOC agents effectively.
Analyst career evolution: The job shifts from “process this alert” to “design this detection strategy” and “govern this AI policy.” Tenure increases from 18 months (burnout-driven turnover) to 3–5 years (growth-driven retention). When your best people stop leaving, institutional knowledge compounds.
Force multiplication: A 3-person team paired with an AI SOC agent achieves coverage equivalent to a 15–20 person traditional SOC, not by working harder, but by eliminating the mechanical investigation steps that consumed 70% of their time.
💰 The Real ROI: Headcount Elevation, Not Reduction
UnderDefense clients reclaim 10–15 hours per week from alert triage, reinvesting that time in threat hunting, compliance automation, and security architecture. That’s not headcount reduction but headcount elevation. As one client put it:
“Underdefense act as an extension of our team, so we don’t need additional resources, ensuring 24/7 protection. It also solved our problem of having separate security tools that didn’t work well together. Now, everything is connected and easier to manage.”
— Inga M., CEO UnderDefense – G2 Verified Review
“Their experienced SOC engineers work closely with our team, providing continuous monitoring and threat detection. They delivered the deployment to 1,200 endpoints in just 23 business days.”
— Oleksii M., Mid-Market UnderDefense – G2 Verified Review
Q7: What Are the Challenges, Adversarial Risks, and Limitations of AI SOC Agents?
As AI SOC agents gain autonomous authority to isolate endpoints, revoke credentials, and block traffic, they become high-value targets themselves. An attacker who compromises an AI SOC agent gains the keys to the kingdom. Honest assessment of these risks isn’t optional but the difference between responsible deployment and a new attack surface.
⚠️ Category A: Operational Challenges
Data quality and integration dependencies: Agents are only as good as ingested telemetry. Incomplete logs, misconfigured integrations, and inconsistent formats degrade accuracy. If your SIEM isn’t shipping DNS logs, your agent can’t detect C2 beaconing. Garbage in, garbage out applies to AI as much as anything else.
Trust, transparency, and explainability: Teams won’t trust actions they can’t understand. Every autonomous decision must produce a human-readable reasoning chain. If your AI SOC can’t show its work, you have a black box with extra steps: the same problem traditional MDR already creates.
❌ Category B: Six Adversarial Attack Surfaces
| # | Threat | Description | Mitigation |
|---|---|---|---|
| 1 | Prompt Injection | Adversarial inputs in log data manipulating agent reasoning | Input sanitization + sandboxed reasoning environments |
| 2 | Training Data Poisoning | Corrupting fine-tuning data to degrade detection accuracy | Provenance tracking + anomaly detection on training pipelines |
| 3 | Agent Credential Hijacking | Stealing service account credentials for autonomous actions | Least-privilege access + credential rotation + short-lived tokens |
| 4 | Model Hallucination | Plausible but incorrect investigation conclusions | Consensus mechanisms + confidence scoring + human validation |
| 5 | Agent Communication Poisoning | False data injected into multi-agent communication channels | Signed + encrypted inter-agent messages |
| 6 | Resource Overload | Overwhelming compute during active attacks when agents are needed most | Rate limiting + graceful degradation + priority queuing |
🛡️ Category C: Governance Risks
Human oversight vs. full autonomy: Tiered autonomy is non-negotiable. Auto-close low-severity false positives; escalate high-severity containment for human approval. The line between “helpful automation” and “unsupervised risk” must be drawn explicitly in policy.
Model drift: Detection models degrade as threats evolve. Without continuous tuning and feedback loops, your AI SOC agent gets dumber over time, not smarter.
Over-reliance: Teams that stop questioning AI lose edge-case detection ability. Mandatory human review for novel patterns prevents the “automation complacency” trap.
✅ Why the Human Ally Model Matters Here
The Human Ally model at UnderDefense means no AI agent takes high-impact action without concierge analyst validation. Every autonomous decision is logged, explainable, and reversible. This is supervised autonomy, not blind automation. AI collects context and accelerates investigation; humans make the final call on decisions that matter.
Q8: How Do AI SOC Agents Map to Compliance Frameworks: SOC 2, HIPAA, NIS2, DORA, and GDPR?
Most organizations run security operations and compliance as separate workstreams: different tools, different teams, different timelines. AI SOC agents collapse this gap. Every alert investigated, action taken, and decision made produces a timestamped, explainable audit record. Compliance evidence becomes a natural byproduct of detection and response, not a quarterly scramble.
📋 Compliance-Capability Mapping
| AI SOC Agent Capability | Regulatory Requirement | Audit Evidence Generated |
|---|---|---|
| Continuous 24/7 monitoring | SOC 2 CC7.2, HIPAA §164.312(b), ISO 27001 A.12.4 | Real-time monitoring logs with timestamps |
| Incident detection & response | NIS2 Art. 21, PCI DSS Req 12.10, DORA Art. 17 | Incident timeline with automated response actions |
| Access anomaly detection | SOC 2 CC6.1, HIPAA §164.312(d), GDPR Art. 32 | Identity verification records via ChatOps |
| Audit trail & explainability | SOC 2 CC7.3, ISO 27001 A.12.4.3 | Agent reasoning chains with confidence scores |
| Incident reporting | NIS2 24-hour mandate, SEC 4-business-day disclosure | Auto-generated reports within minutes of containment |
🔒 Secure Agent Gateway and Data Access Policies
Three architectural requirements protect compliance during AI SOC agent operations:
Model Context Protocol (MCP): A standardized framework governing how agents access, process, and retain data. Every data interaction is scoped, logged, and auditable.
Data minimization: Agents access only the telemetry required for a specific investigation. No blanket access, no persistent data hoarding.
Data residency: Processing respects geographic sovereignty. EU data stays in EU infrastructure. This matters for GDPR Art. 44–49 and DORA’s operational resilience requirements.
⚖️ Audit Trail Requirements for Autonomous Decisions
Every autonomous decision must log five elements: input data, reasoning chain, confidence score, action taken, and authorizing policy rule. Without this, your AI SOC is a compliance liability, not an asset. Auditors don’t accept “the AI decided”; they need reproducible evidence of why it decided and under what authority.
✅ UnderDefense: Compliance Built into Security Operations
We include forever-free compliance kits with every MDR engagement: SOC 2, HIPAA, ISO 27001, and PCI DSS, generating audit-ready evidence automatically from the same AI-driven workflows that protect your environment. No separate GRC tools, no additional cost. As one client noted:
“UnderDefense also helped us navigate key compliance requirements, ensuring we met industry standards smoothly and efficiently. What stood out the most was their responsiveness and flexibility.”
— Arman N., CTO UnderDefense – G2 Verified Review
“Building our cybersecurity from scratch felt like a daunting challenge. Their vCISO team was amazing in supporting us with ISO 27001.”
— Val R., Small-Business UnderDefense – G2 Verified Review
Q9: How Should Security Leaders Evaluate and Test AI SOC Agent Vendors?
Choosing an AI SOC agent is one of the highest-stakes architectural decisions a security leader makes. Get it right, and you’ve got a force multiplier that scales detection, investigation, and response across your entire environment. Get it wrong, and you’re locked into a proprietary ecosystem, drowning in AI-generated noise, or, worse, paying for autonomous detection that still escalates tickets right back to your team.
⚠️ The Wrong Way to Decide
Most leaders default to brand recognition (“CrowdStrike is the biggest”) or integration counts (“They support 500 tools”). Neither tells you what actually matters: Can the system reason across your environment with organizational context, respond to threats autonomously where appropriate, and explain its decisions so your team, and your auditors, can verify what happened? If a vendor can’t show you the investigation workflow step by step, you’re buying a black box.
Here’s the 12-point evaluation framework I use when advising security teams on vendor selection. Score each criterion 0–2 (0 = absent, 1 = partial, 2 = fully met).
✅ 12-Point AI SOC Agent Evaluation Framework
| # | Criterion | What to Look For |
|---|---|---|
| 1 | Vendor-Agnostic Integration | Works with your existing SIEM, EDR, cloud, and identity, no forced replacement |
| 2 | Autonomy Depth | L1 triage only vs. L1–L3 investigation + containment |
| 3 | Human-in-the-Loop Design | Direct analyst access vs. ticket-based escalation |
| 4 | Explainability & Audit Trail | Every AI decision observable, auditable, and reproducible |
| 5 | Response Capability | Detection-only vs. full containment + remediation |
| 6 | MITRE ATT&CK Coverage % | Documented coverage against the framework (target: 90%+) |
| 7 | Pricing Transparency | Published rates vs. “contact sales” |
| 8 | Compliance Integration | Automated evidence collection for SOC 2, HIPAA, and ISO 27001 |
| 9 | Onboarding Speed | Days-to-value: 30-day turnkey vs. 6-month professional services |
| 10 | User Verification / ChatOps | Can analysts reach affected users directly via Slack, Teams, or SMS? |
| 11 | Multi-Agent Architecture | Coordinated agents across EDR, SIEM, identity, and cloud |
| 12 | Adversarial Robustness | Resistance to prompt injection, model poisoning, and evasion |
Max Score: 24. Providers scoring 20+ represent strong architectural fit. Below 16 means you’re buying an alert feed, not a managed AI SOC.
💰 Pricing Model Comparison
| Model | How It Works | Pros | Cons |
|---|---|---|---|
| Per-Alert | Charged per alert investigated | Scales with volume | Unpredictable costs; penalizes noisy environments |
| Per-Endpoint | Fixed monthly rate per device | Predictable budgeting; easy to forecast | Doesn’t reflect investigation complexity |
| Platform Fee | Flat annual license | Simple procurement | May overpay at smaller scale; hides per-unit economics |
UnderDefense uses the per-endpoint model at $11–$15/endpoint/month, published, predictable, and audit-friendly. Compare that to Arctic Wolf’s opaque $96K median annual contracts or CrowdStrike’s $60/user/year premium tiers.
📊 Key Metrics to Track During Evaluation
- MTTD (Mean Time to Detect): Target < 5 minutes for known threat patterns
- MTTR (Mean Time to Respond): Target < 1 hour for critical incidents
- MTTT (Mean Time to Triage): From alert to enriched verdict, target < 2 minutes
- Escalation Rate: Percentage of alerts requiring human review (< 10% is strong)
- True Positive Rate: Accuracy of confirmed threats vs. false positives (target: 95%+)
The CSA’s 2025 benchmark study confirmed that AI-assisted analysts completed investigations 45–61% faster and were 22–29% more accurate than manual counterparts, but only when the AI platform provided transparent, auditable workflows.
✅ AI SOC Agent Vendor Comparison Matrix
| Criterion | UnderDefense MAXI | CrowdStrike Charlotte AI | Palo Alto XSIAM | Dropzone AI | ReliaQuest GreyMatter |
|---|---|---|---|---|---|
| Vendor-Agnostic Integration | 2 | 0 (Falcon-native) | 1 (PAN ecosystem) | 2 | 1 (proprietary) |
| Autonomy Depth (L1–L3) | 2 | 1 (L1–L2) | 2 | 2 | 1 |
| Human-in-the-Loop | 2 (direct concierge) | 1 (ticket-based) | 1 | 0 (autonomous only) | 1 |
| Explainability & Audit | 2 | 1 | 1 | 2 | 1 |
| Response Capability | 2 | 2 | 2 | 1 (investigation focus) | 1 |
| MITRE ATT&CK Coverage | 2 (96%) | 2 | 2 | 1 | 1 |
| Pricing Transparency | 2 ($11–15/ep/mo) | 0 (contact sales) | 0 (contact sales) | 1 (custom quotes) | 0 (contact sales) |
| Compliance Integration | 2 (forever-free kits) | 0 | 1 | 0 | 0 |
| Onboarding Speed | 2 (30 days) | 1 | 1 | 2 | 1 |
| User Verification / ChatOps | 2 (Slack/Teams/SMS) | 0 | 0 | 0 | 0 |
| Multi-Agent Architecture | 2 | 2 | 2 | 2 | 1 |
| Adversarial Robustness | 2 | 2 | 2 | 1 | 1 |
| Total | 24/24 | 12/24 | 15/24 | 14/24 | 9/24 |
🔍 POV/POC Playbook: Validate Before You Commit
Pre-POV Checklist (complete before any pilot):
- Define 3–5 measurable success criteria (MTTR, false positive reduction, analyst hours saved)
- Prepare realistic test data from your environment (not vendor-supplied datasets)
- Identify 3 critical integration points (your SIEM, primary EDR, and identity provider)
- Assign an internal evaluator who will own the scoring
- Set a 14-day evaluation timeline with weekly check-ins
5 Test Scenarios:
- High-volume false positive suppression: inject 500+ benign alerts; measure noise reduction
- Multi-stage attack investigation: simulate lateral movement across endpoints and cloud
- Identity + cloud cross-correlation: test impossible travel + suspicious OAuth grant chain
- Autonomous containment under time pressure: introduce active threat; measure time-to-contain
- Compliance report generation: request SOC 2 evidence package from the evaluation period
Scoring Rubric: 0–2 per scenario × 5 = max 10. Combined with the 12-point framework (max 24), total possible = 34. 28+ = strong fit. 20–27 = conditional (negotiate gaps). <20 = architectural misalignment.
We invite every prospect to run this exact evaluation against us, because if a vendor can’t perform under your conditions with your data, no demo deck or sales pitch changes that reality.
“Their team provided us with clear and detailed insights into security vulnerabilities, along with practical recommendations on how to fix them. This level of transparency made it easy for our team to take action and strengthen our security.”
— Arman N., CTO UnderDefense – G2 Verified Review
“UnderDefense MAXI integrates well with our systems, specifically with our SIEM, Splunk. Their team is proactive in identifying and addressing threats, providing 24/7 oversight.”
— Oleg K., Director Information Security UnderDefense – G2 Verified Review
Q10: Which AI SOC Agent Solutions Should You Evaluate in 2026?
The leading AI SOC agent solutions for 2026 include UnderDefense MAXI (AI SOC + Human Ally with vendor-agnostic integration across 250+ tools), CrowdStrike Charlotte AI (Falcon-native agentic detection), Palo Alto XSIAM (unified SIEM-to-SOC platform), Dropzone AI (autonomous investigation specialist), and Stellar Cyber (Open XDR with agentic capabilities), each with distinct architectural approaches, pricing models, and response philosophies.
What Separates the Leaders
AI SOC agents have moved from conference buzzwords to production-ready platforms. But the differences between them are architectural, not cosmetic. Here’s what actually matters when narrowing your shortlist:
- Vendor-agnostic integration vs. proprietary lock-in: Does it work with your existing SIEM and EDR, or force replacement?
- Autonomous response vs. detection-only: Can it contain threats, or just surface alerts for your team?
- Human analyst access, direct vs. ticket-based: Do you reach a Tier 3–4 analyst, or submit a support ticket?
- Published pricing vs. opaque enterprise quotes: Can you build a budget before the first sales call?
- Compliance evidence built-in vs. separate add-on: Does security monitoring generate audit artifacts automatically?
⏰ Matching Solutions to Scenarios
Each solution excels in different operational contexts. UnderDefense is purpose-built for organizations that want to protect existing security investments and need human-ally response alongside AI automation. CrowdStrike Charlotte AI fits Falcon-native environments that have standardized on the CrowdStrike ecosystem. Palo Alto XSIAM suits organizations pursuing full ecosystem consolidation under one vendor. The right choice depends on your current security stack, budget constraints, and operational model.
This analysis is based on documented response times, G2 Spring 2025 rankings, published pricing, and operational outcomes across 500+ MDR deployments.
Q11: What Is the Real ROI of an AI SOC Agent? A Board-Ready Business Case
Every board presentation on cybersecurity eventually hits the same question: “What are we getting for this spend?” The ROI of an AI SOC agent isn’t theoretical but measurable across operational savings, risk reduction, and strategic reallocation. Here’s how to build the business case with numbers your CFO can verify.
📊 Core ROI Metrics: Before and After AI SOC
| Metric | Before AI SOC (Industry Avg.) | After AI SOC (UnderDefense Benchmarks) |
|---|---|---|
| MTTD (Mean Time to Detect) | 194 days (IBM 2024) | Minutes (real-time AI correlation) |
| MTTR (Mean Time to Respond) | 24–72 hours | 0.5 hours for critical incidents |
| MTTT (Mean Time to Triage) | 30+ minutes per alert | < 2 minutes per alert |
| False Positive Reduction | Baseline (100% manual review) | 99% fewer customer-facing alerts |
| Investigation Speed | Manual baseline | 45–61% faster (CSA benchmark) |
| Escalation Rate | 100% manual review | < 10% requiring human decision |
The CSA’s October 2025 benchmark study, testing 148 security professionals, confirmed that AI-assisted analysts were 22–29% more accurate and 45–61% faster than manual counterparts, with consistency maintained over time while manual analysts’ quality dropped 27%.
💰 Cost-Benefit Calculation Model
| Cost Component | Internal SOC (24/7) | AI SOC Agent (UnderDefense) |
|---|---|---|
| Analyst Staffing | 5 analysts × $110K = $550K/year | Included in platform |
| Security Tooling (SIEM, SOAR, TI) | ~$200K/year | Included (UnderDefense MAXI platform) |
| Total Annual Cost | ~$750K/year | $66K–$90K/year (500 endpoints × $11–$15/mo) |
| Net Operational Savings | — | $660K–$684K/year |
For breach cost avoidance: IBM’s 2025 Cost of a Data Breach Report found the global average dropped to $4.44 million (down 9% from $4.88M), driven by faster AI-powered containment. With a 30–50% reduced breach likelihood through 24/7 AI SOC coverage, the risk-adjusted value is $1.33M–$2.22M annually.
⚠️ Hidden Costs Most Business Cases Miss
Analyst Turnover: Replacing a burned-out SOC analyst costs 1.5–2× their salary (~$165K–$220K per departure). AI eliminates the repetitive triage work that drives 18-month average tenure in SOC roles.
Compliance Tool Consolidation: Forever-free compliance kits (SOC 2, ISO 27001, and HIPAA) eliminate $50K–$150K/year in separate GRC platforms like Vanta or Drata. Security monitoring and compliance evidence collection happen in one system.
Strategic Reallocation: When analysts shift from alert triage to threat hunting and architecture improvement, the value compounds. An analyst doing proactive work generates 3–5× more security value than one manually closing false positives.
Cyber Insurance Premium Reduction: Documented 24/7 SOC capabilities with auditable AI workflows reduce cyber insurance premiums by 10–25%. Carriers increasingly require evidence of automated detection and response.
✅ The Board-Ready Summary
Published pricing ($11–$15/endpoint/month), forever-free compliance kits, documented 0.5-hour MTTR for critical incidents, and 830% ROI over 3 years: these are concrete numbers for board-level justification, not vendor promises requiring faith.
Q12: Where Are AI SOC Agents Heading? The Autonomous SOC Roadmap (2026–2030)
AI SOC agents sit at a pivotal inflection point. Gartner’s 2025 Hype Cycle for Security Operations placed AI SOC Agents on the Innovation Trigger: early adoption, moderate benefit rating, with deployments expected as controlled pilots tied to workflow outcomes. The prediction: by 2026, 50% of SOCs will deploy AI-based decision support. But “decision support” is very different from “fully autonomous,” and the gap between those two states is where the real strategic planning happens.
The Overpromise Risk
Here’s the uncomfortable truth: vendors claiming “fully autonomous SOC” today are overpromising. Adversarial sophistication increases alongside AI capability: polymorphic malware, AI-generated social engineering, and automated reconnaissance evolve at the same pace as defensive AI. A fully autonomous SOC without human judgment isn’t resilient but a single point of failure. The realistic trajectory is supervised autonomy expanding, not humans being removed.
✅ 5-Level SOC Autonomy Maturity Model
| Level | Name | Description | Human Role | Timeline |
|---|---|---|---|---|
| 1 | MANUAL | Humans do everything; tools provide raw data | Investigate, triage, respond, and hunt | Legacy (pre-2020) |
| 2 | PLAYBOOK-ASSISTED | SOAR automates known patterns; humans handle exceptions | Configure playbooks, handle edge cases | 2020–2023 |
| 3 | AI-AUGMENTED | AI handles L1 triage (80–90% resolved autonomously); humans investigate + respond | Investigate complex alerts, approve response, govern AI | Most orgs today (2024–2026) |
| 4 | AI-LED | AI handles triage + investigation; humans approve high-impact response + govern policy | Policy governance, high-impact decisions, strategic hunting | Realistic target (2028–2030) |
| 5 | FULLY AUTONOMOUS | AI end-to-end; humans set policy + audit | Policy design, adversarial red-teaming, audit | Theoretical (requires solved adversarial robustness) |
🔍 Agent-to-Agent Orchestration: The Next Frontier
The most significant architectural shift through 2030 won’t be individual AI agents getting smarter; it will be agent-to-agent orchestration across multi-vendor ecosystems. Your EDR agent, SIEM agent, identity agent, and cloud security agent collaborating via standardized protocols regardless of vendor. This is why vendor-agnostic design matters today: platforms built on proprietary stacks can’t participate in this cross-ecosystem orchestration without fundamental re-architecture.
UnderDefense’s Forward Position
We architected UnderDefense MAXI for Level 4 from day one: AI-led operations with human governance built into every workflow. The vendor-agnostic design (250+ integrations) means the platform evolves with the market. As AI capabilities mature, the human-to-AI ratio shifts, but the Human Ally never disappears. Organizations running UnderDefense MAXI today operate at Level 3, building institutional context and tuning detection models that position them for Level 4 transition without rip-and-replace.
⏰ The Call to Action
The organizations best positioned in 2028 are the ones deploying AI SOC agents today. Not because the technology is perfect, because it isn’t, but because institutional context, detection model tuning, and team governance skills compound over time. Every month of alert data, user verification patterns, and organizational context makes the AI more effective and the human team more strategic. The question isn’t whether to adopt AI SOC agents. It’s whether to start building that compounding advantage now, or start behind.
1. How does an AI SOC agent differ from a chatbot, co-pilot, or SOAR playbook?
The distinction comes down to autonomy, reasoning, and action capability. A chatbot answers questions about alerts but cannot investigate them. A co-pilot suggests next steps for a human to execute manually. SOAR runs static if-then playbooks that break the moment an attack deviates from the scripted pattern.
An AI SOC agent operates fundamentally differently. It is an LLM-powered autonomous system that perceives security telemetry from multiple sources, reasons across data to formulate investigation hypotheses, decides on response paths, and executes actions using learned reasoning with organizational context.
At UnderDefense, we built the UnderDefense MAXI platform around this distinction. The AI handles context collection, SIEM queries, log enrichment, and cross-system correlation at machine speed. Human concierge analysts handle what AI still cannot: understanding intent, validating with affected users, and making business-risk decisions. Detection without response is noise, and response without context is risk.
2. Why are AI SOC agents emerging as a category in 2025 and 2026?
Three forces converged simultaneously to create this category. First, SOC teams are breaking under alert volume they cannot physically process. Teams handle an average of 960 alerts per day, with large enterprises exceeding 3,000 daily alerts from 30+ tools. Forty percent go uninvestigated entirely.
Second, LLM technology matured enough to reason about security data, not just pattern-match against it. Agentic frameworks now enable agents to interact with 90+ security tools natively.
Third, the market validated the category. Gartner placed AI SOC agents on the Hype Cycle for Security Operations in 2025, and the global cybersecurity workforce gap reached 4.8 million unfilled positions.
We anticipated this convergence at UnderDefense. Staffing a 24/7 SOC internally exceeds $1M/year, and the math simply does not work for most mid-market organizations. The result is a system that handles mechanical investigation steps at machine speed while humans focus on judgment calls requiring business context.
3. What is the agentic architecture behind AI SOC agents, and how does multi-agent orchestration work?
Every AI SOC agent follows a five-step investigation cycle: Ingest (normalize telemetry into a unified data model), Enrich (augment with threat intelligence and user behavior baselines via RAG), Investigate (LLM-based reasoning engine formulates hypotheses and queries additional sources), Decide (determine severity and required actions based on policy thresholds), and Adapt (update baselines and learn from analyst feedback).
Complex attacks span multiple domains, so no single agent has full context. Three orchestration patterns dominate production deployments:
-
Supervisor-Worker: A meta-orchestrator routes tasks to domain-specific agents across triage, identity, endpoint, cloud, and response.
-
Peer-to-Peer: Agents communicate directly, with the endpoint agent tasking the identity agent to check OAuth anomalies.
-
Hierarchical: Tiered agents with escalation from L1 triage through L2 investigation to L3 response, mirroring traditional SOC structure.
Most production systems use hybrid reasoning: LLM for flexible investigation, deterministic guardrails for action validation. This ensures both adaptability and auditability.
4. What are the six core capabilities that define a real AI SOC agent?
The six capabilities that separate a production AI SOC agent from another dashboard are:
-
Automated Alert Triage + False Positive Suppression: Correlates across all sources, verifies with users, and auto-closes noise, replacing 10 to 15 hours per week of manual L1 analyst triage.
-
Autonomous Investigation + Cross-Source Correlation: Multi-domain hypothesis testing, 45 to 61% faster than manual investigation per CSA benchmarks.
-
Proactive Threat Hunting + Anomaly Detection: Continuous hunting without waiting for alerts to fire, replacing quarterly threat hunts that miss real-time threats.
-
MITRE ATT&CK Mapping + Attack Path Construction: Auto-maps observed TTPs to kill chain stages automatically.
-
Self-Adapting Response Workflows: Containment actions adjust based on investigation findings, replacing static SOAR playbooks.
-
Automated Documentation + Compliance Reporting: Incident reports and audit evidence generated automatically.
UnderDefense MAXI resolves scenarios using all six capabilities daily, with concierge analysts validating AI-driven containment and delivering complete incident reports by morning.
5. How do AI SOC agents map to compliance frameworks like SOC 2, HIPAA, NIS2, DORA, and GDPR?
AI SOC agents collapse the gap between security operations and compliance by generating timestamped, explainable audit records as a natural byproduct of detection and response. Every alert investigated, action taken, and decision made produces compliance evidence automatically.
Key mappings include:
-
Continuous 24/7 monitoring satisfies SOC 2 CC7.2, HIPAA §164.312(b), and ISO 27001 A.12.4.
-
Incident detection and response covers NIS2 Art. 21, PCI DSS Req 12.10, and DORA Art. 17.
-
Access anomaly detection addresses SOC 2 CC6.1, HIPAA §164.312(d), and GDPR Art. 32.
-
Incident reporting meets the NIS2 24-hour mandate and SEC 4-business-day disclosure requirements.
Every autonomous decision must log five elements: input data, reasoning chain, confidence score, action taken, and authorizing policy rule. We include forever-free compliance kits with every MDR engagement, generating audit-ready evidence automatically from the same AI-driven workflows that protect your environment.
6. How should security leaders evaluate and score AI SOC agent vendors?
We use a 12-point evaluation framework when advising security teams. Score each criterion 0 to 2 (0 = absent, 1 = partial, 2 = fully met):
Vendor-Agnostic Integration, Autonomy Depth (L1 through L3), Human-in-the-Loop Design, Explainability and Audit Trail, Response Capability, MITRE ATT&CK Coverage (target 90%+), Pricing Transparency, Compliance Integration, Onboarding Speed, User Verification/ChatOps, Multi-Agent Architecture, and Adversarial Robustness.
Providers scoring 20+ out of 24 represent strong architectural fit. Below 16 means you are buying an alert feed, not a managed AI SOC. Pair this with a POV/POC playbook: define 3 to 5 measurable success criteria, prepare realistic test data from your environment, and run five test scenarios including high-volume false positive suppression and autonomous containment under time pressure.
We invite every prospect to run this evaluation against us, because if a vendor cannot perform under your conditions with your data, no demo deck changes that reality.
7. What is the real ROI of deploying an AI SOC agent, and how do we present it to the board?
The ROI is measurable across three dimensions: operational savings, risk reduction, and strategic reallocation. An internal 24/7 SOC costs approximately $750K/year (5 analysts at $110K plus ~$200K in tooling). An AI SOC agent through UnderDefense costs $66K to $90K/year for 500 endpoints at $11 to $15/endpoint/month, delivering $660K to $684K in net operational savings.
For breach cost avoidance, IBM’s 2025 Cost of a Data Breach Report found the global average at $4.44 million. With 30 to 50% reduced breach likelihood through 24/7 AI SOC coverage, the risk-adjusted value is $1.33M to $2.22M annually.
Hidden costs most business cases miss include analyst turnover ($165K to $220K per departure), compliance tool consolidation ($50K to $150K/year saved with forever-free compliance kits), and cyber insurance premium reductions of 10 to 25%. The board-ready number: 830% ROI over 3 years with published, verifiable pricing.
8. What are the adversarial risks of AI SOC agents, and how do you mitigate them?
As AI SOC agents gain autonomous authority to isolate endpoints, revoke credentials, and block traffic, they become high-value targets themselves. Six adversarial attack surfaces require active mitigation:
-
Prompt Injection: Adversarial inputs in log data manipulating agent reasoning, mitigated by input sanitization and sandboxed reasoning environments.
-
Training Data Poisoning: Corrupting fine-tuning data to degrade detection accuracy, mitigated by provenance tracking.
-
Agent Credential Hijacking: Stealing service account credentials, mitigated by least-privilege access and short-lived tokens.
-
Model Hallucination: Plausible but incorrect investigation conclusions, mitigated by consensus mechanisms and confidence scoring.
-
Agent Communication Poisoning: False data injected into multi-agent channels, mitigated by signed and encrypted inter-agent messages.
-
Resource Overload: Overwhelming compute during active attacks, mitigated by rate limiting and priority queuing.
The Human Ally model at UnderDefense means no AI agent takes high-impact action without concierge analyst validation. This is supervised autonomy, not blind automation.
The post AI SOC Agents: Architecture, Evaluation, and the 2026 Vendor Comparison appeared first on UnderDefense.